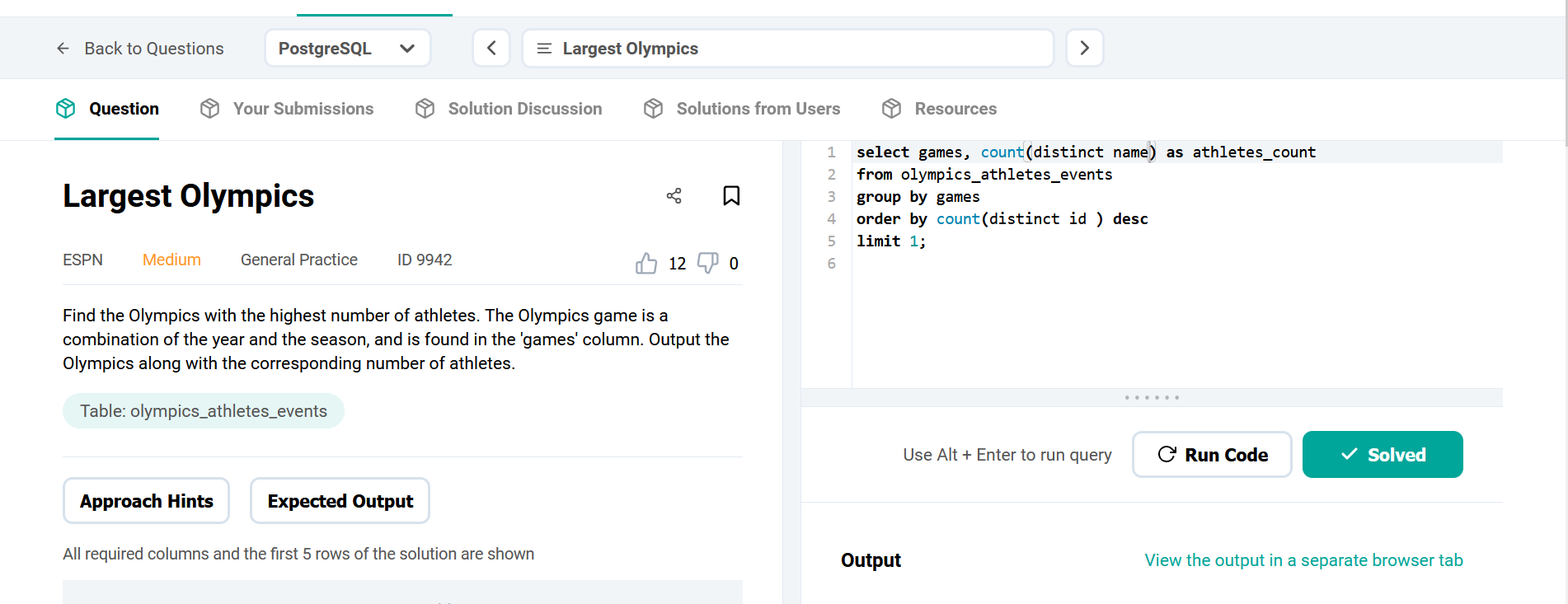
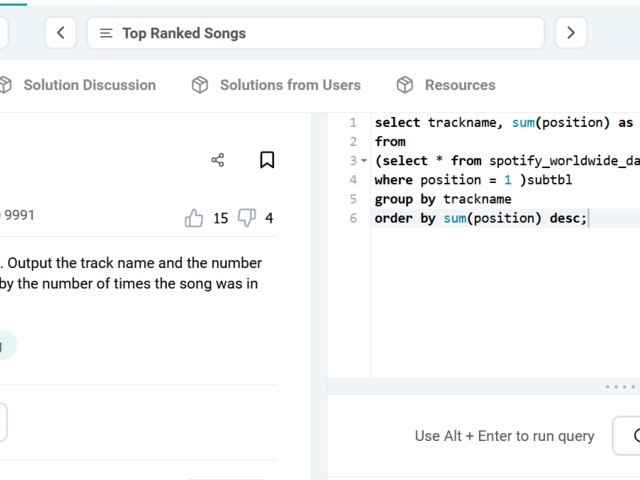
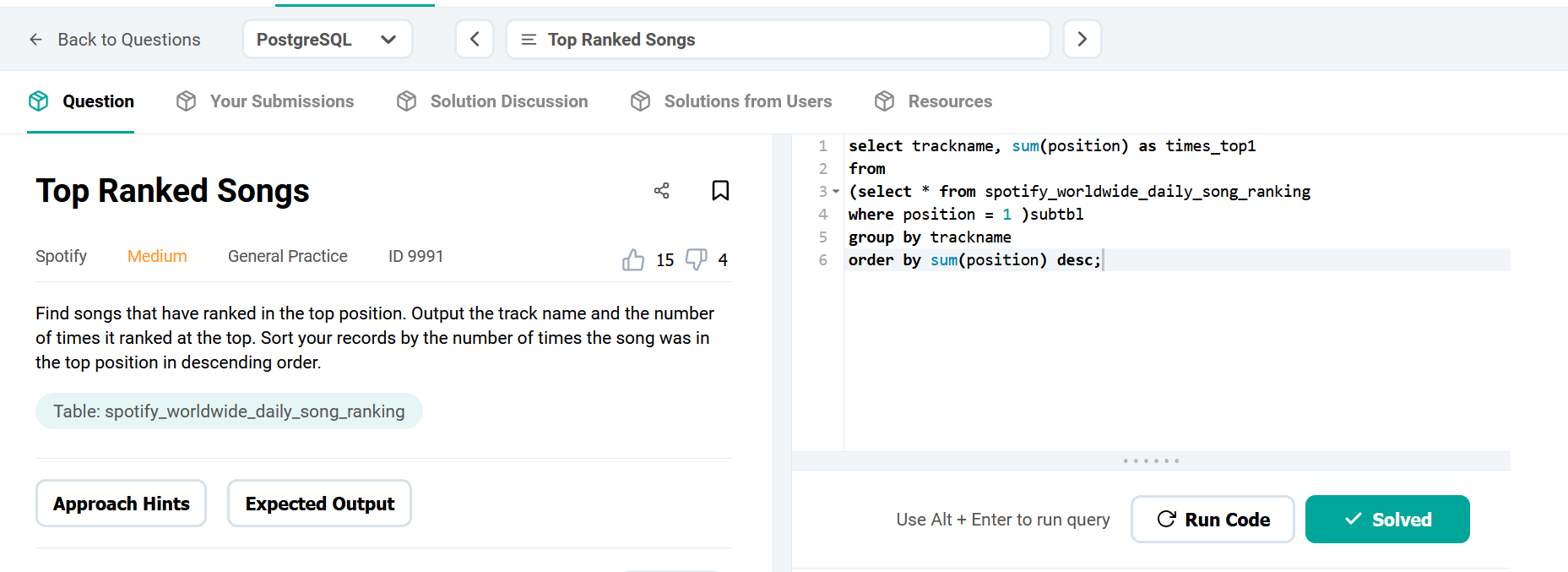
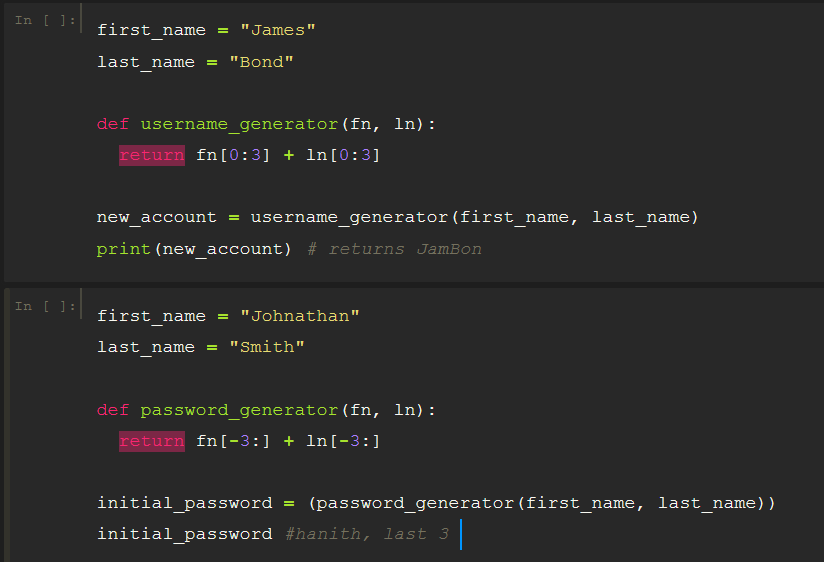
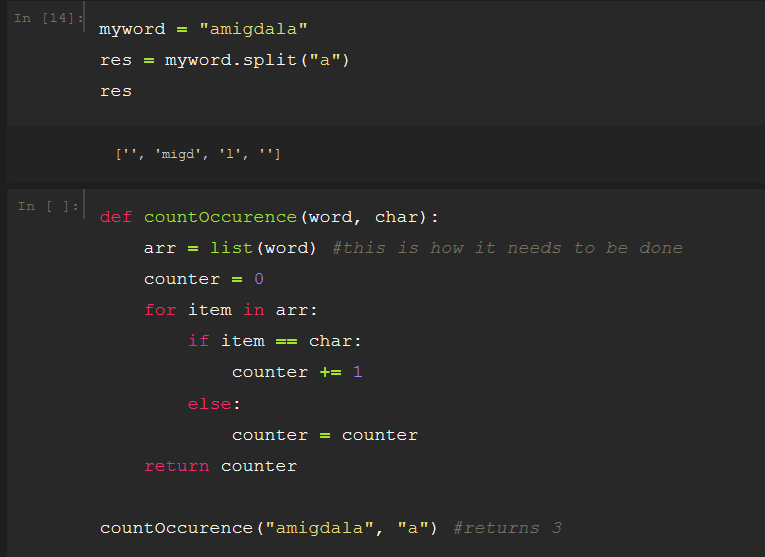
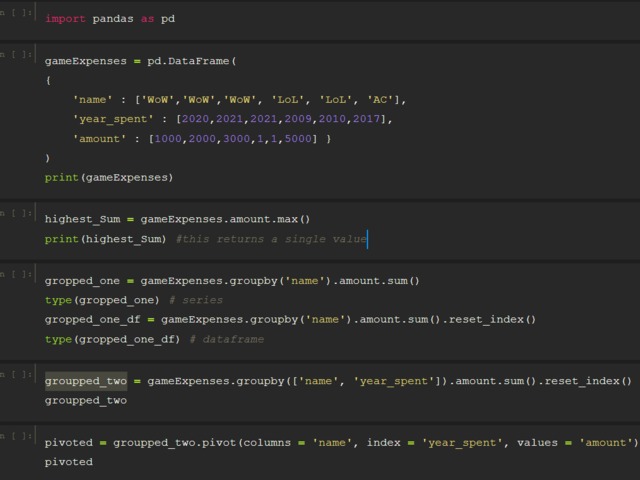
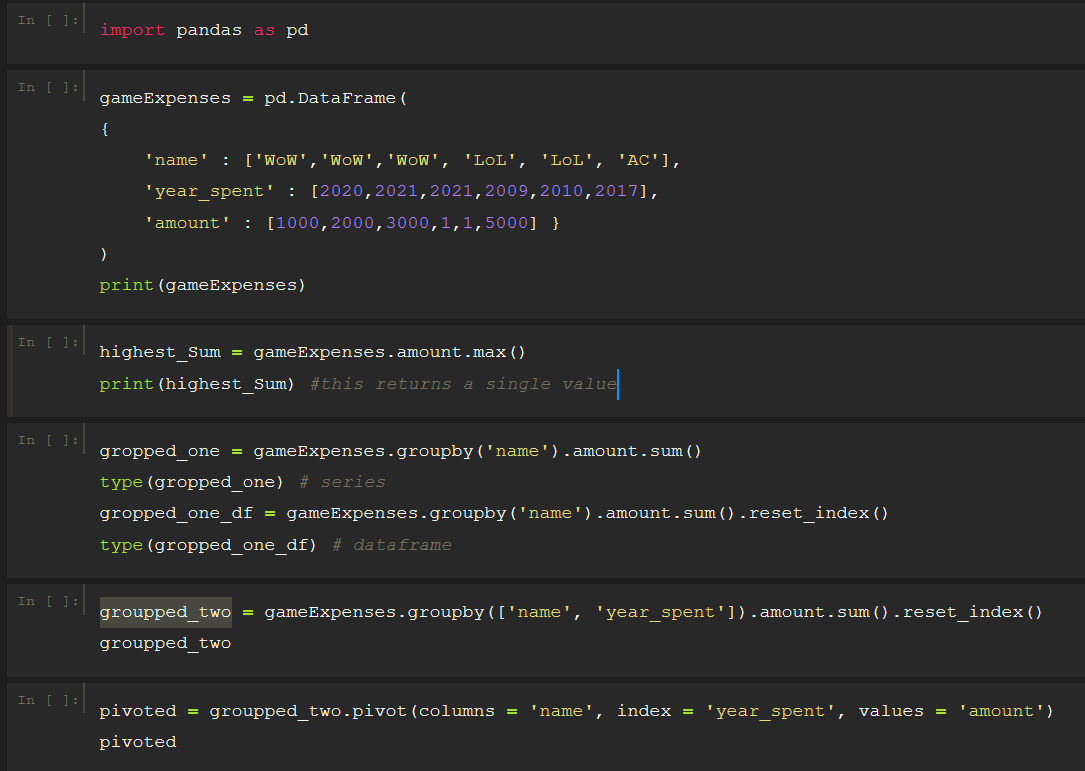
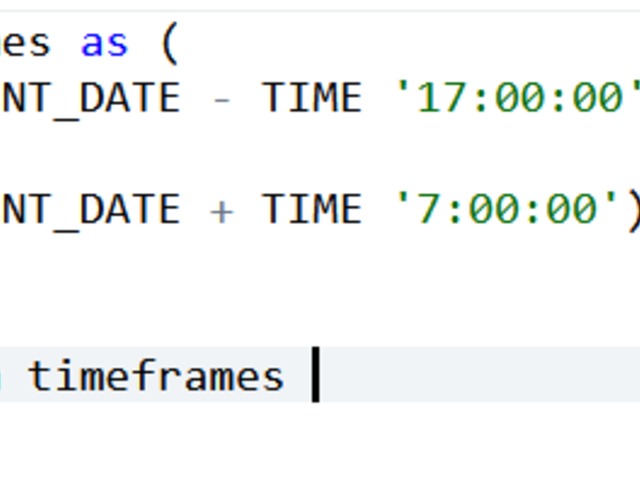
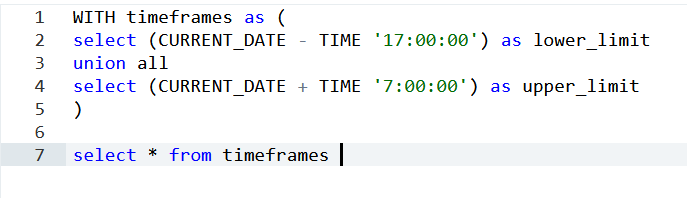
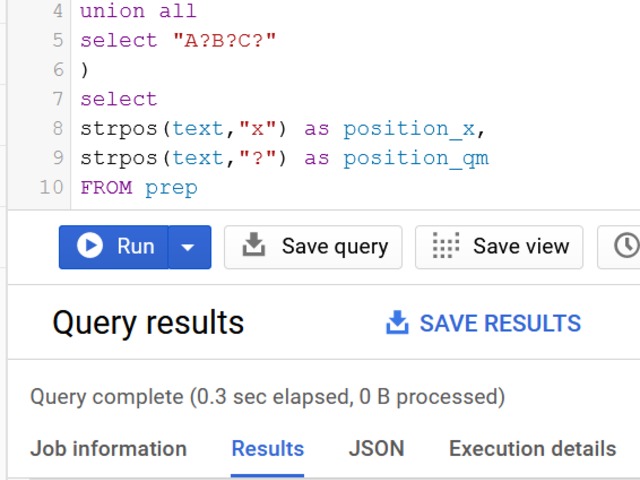
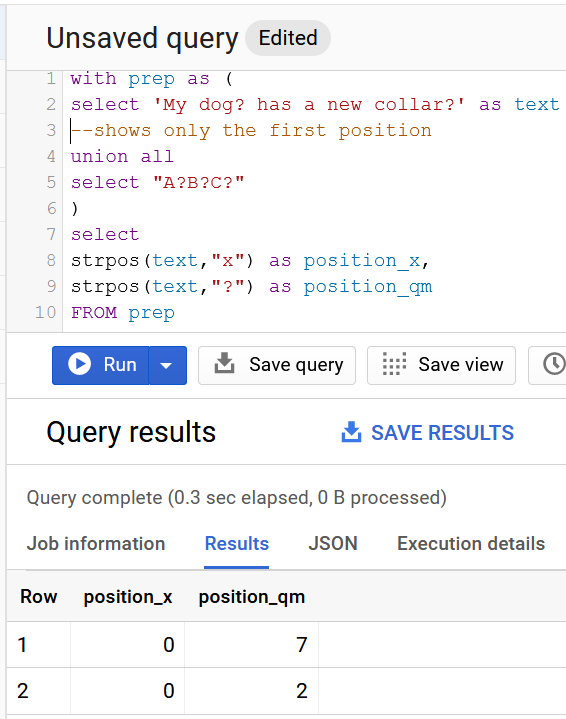
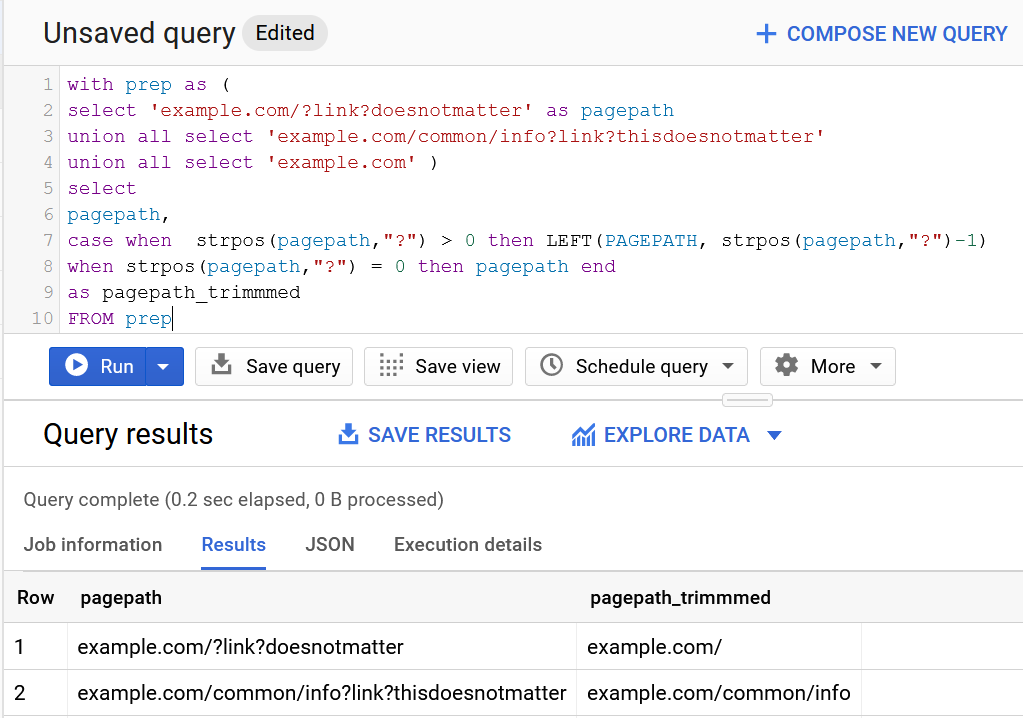
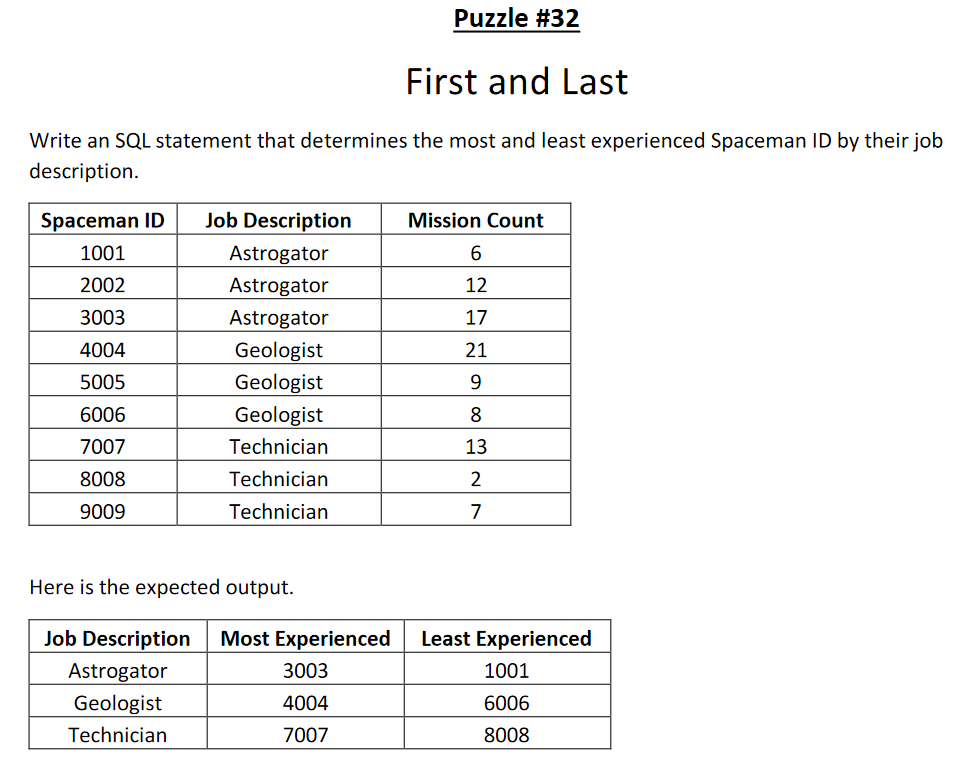
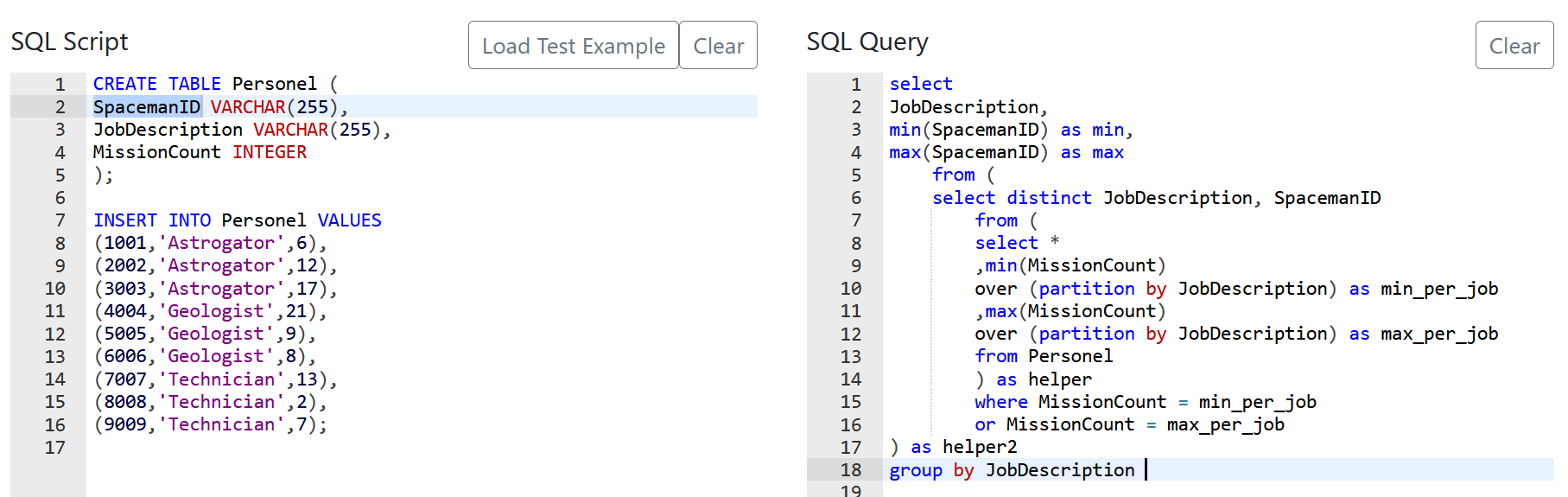
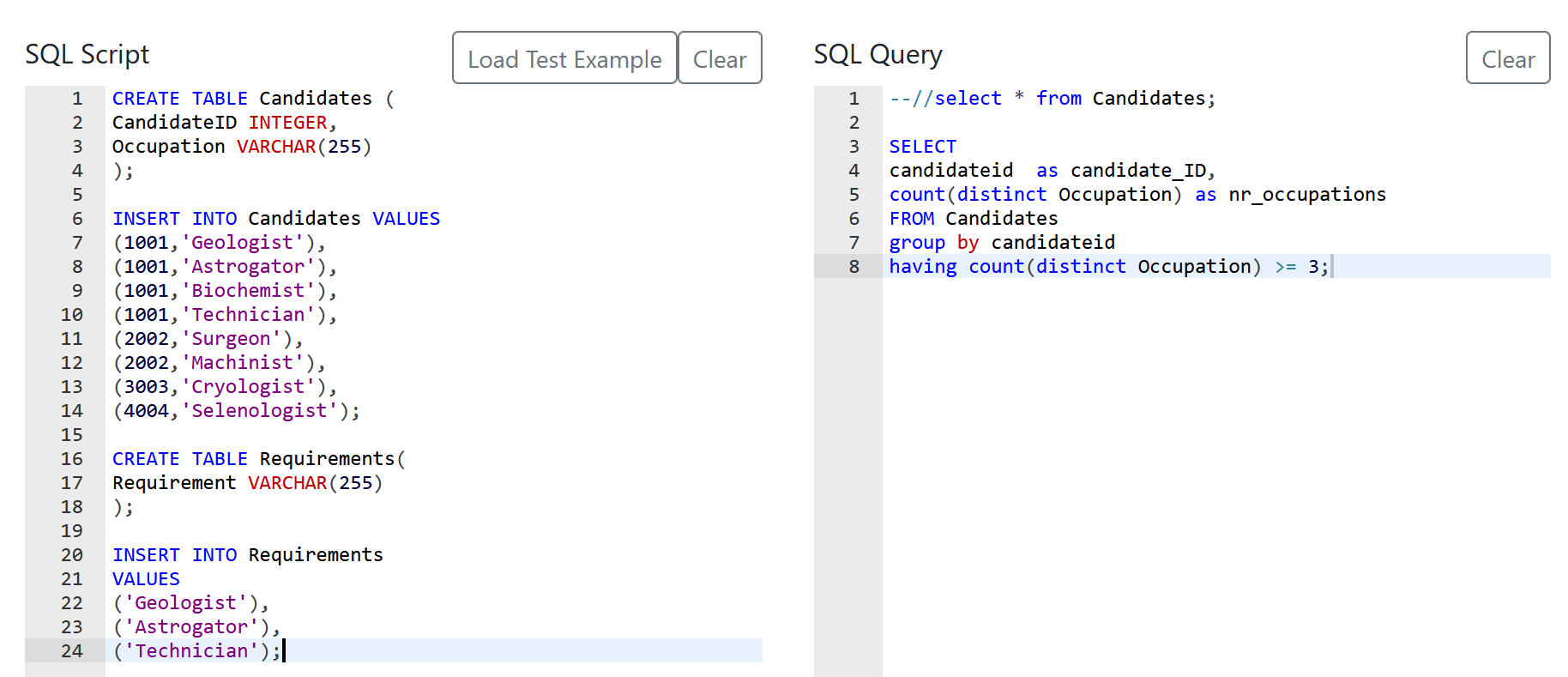
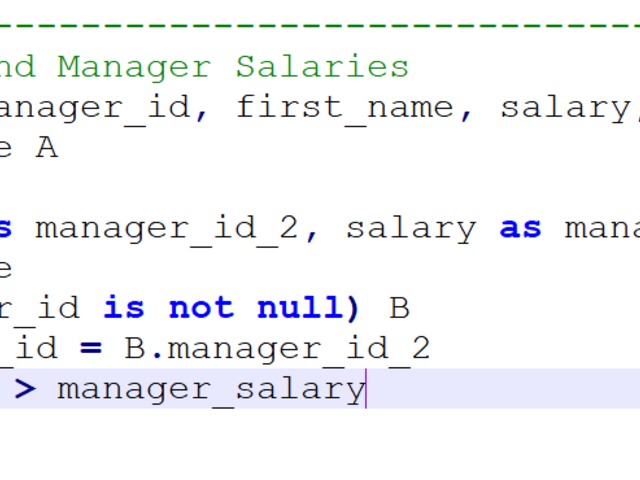
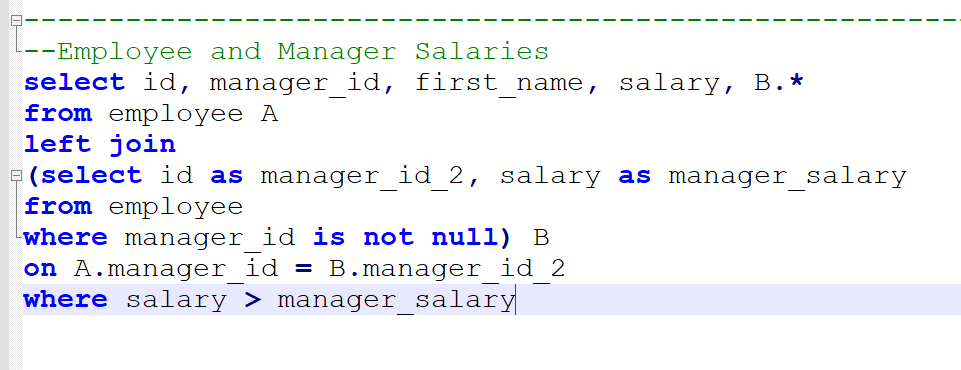
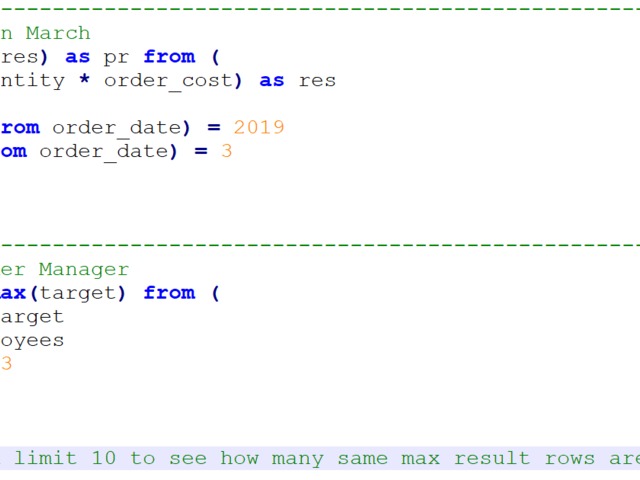
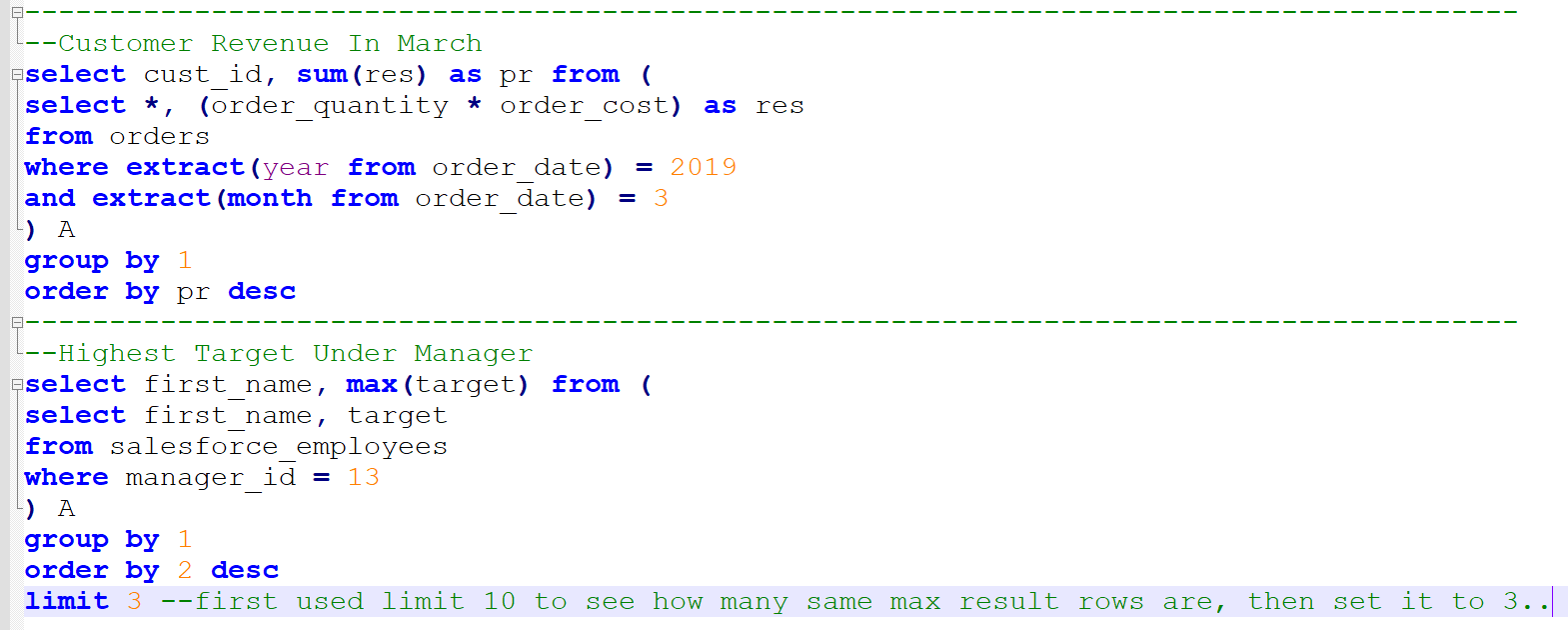
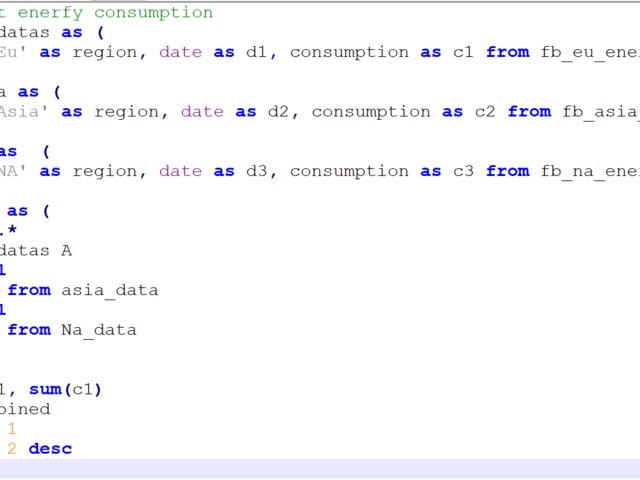
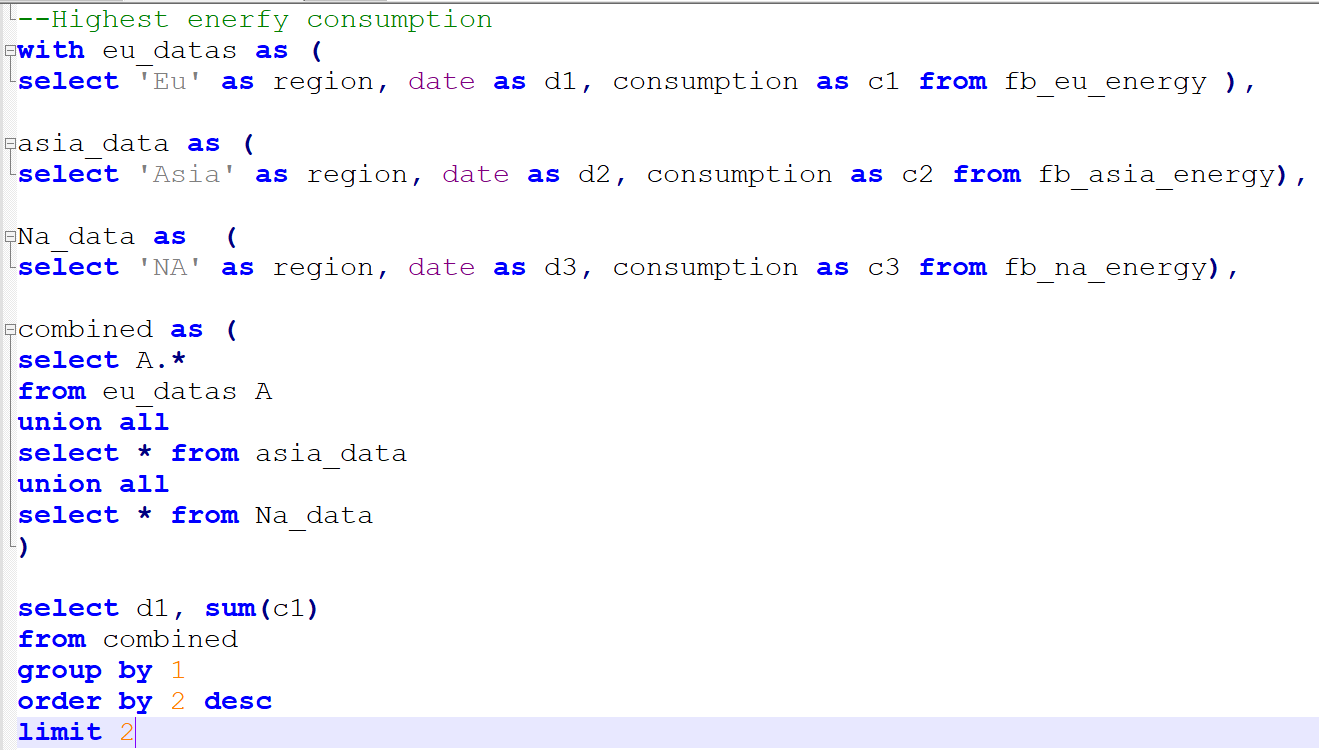
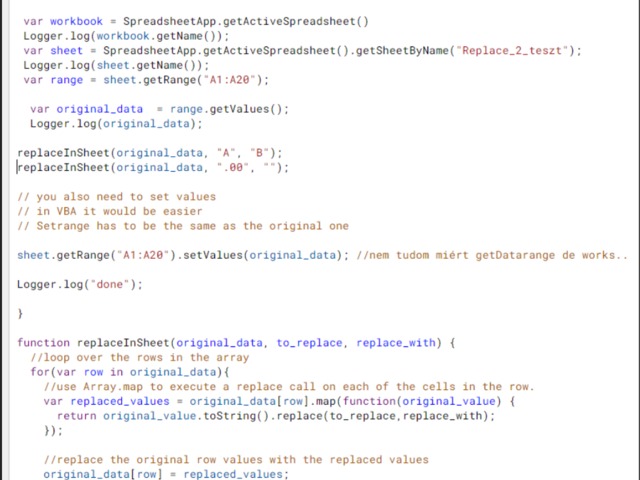
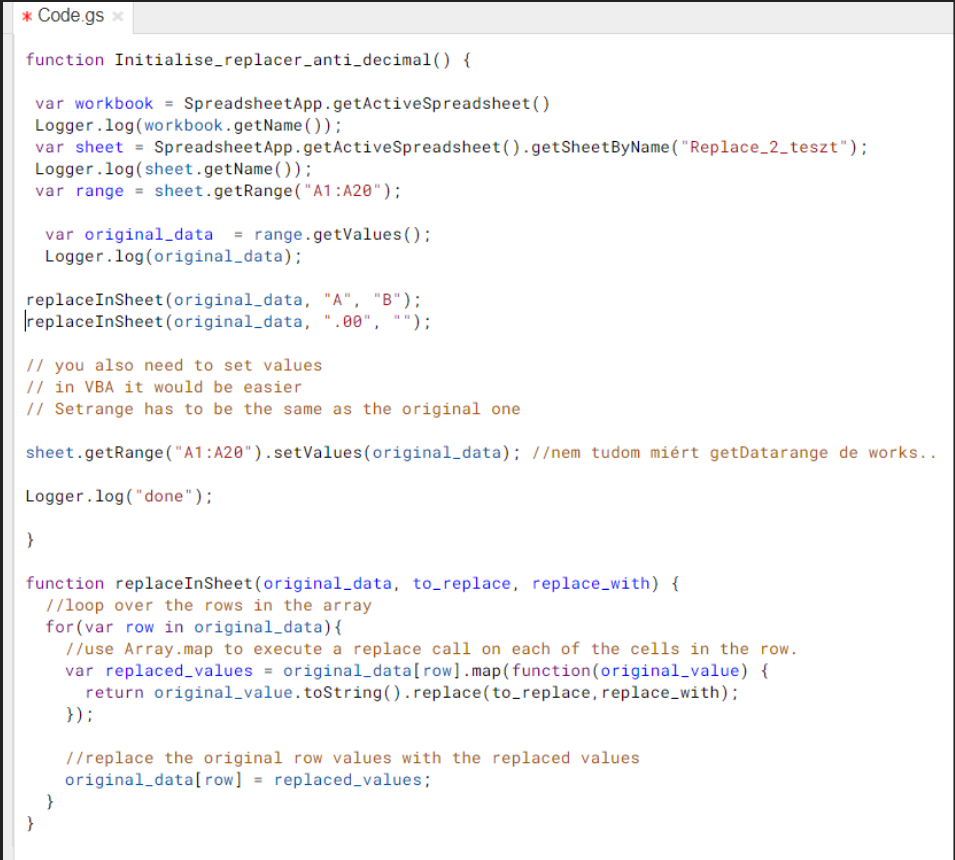
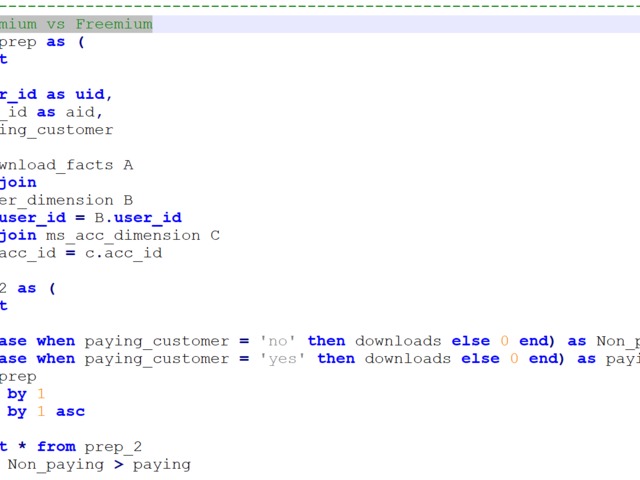
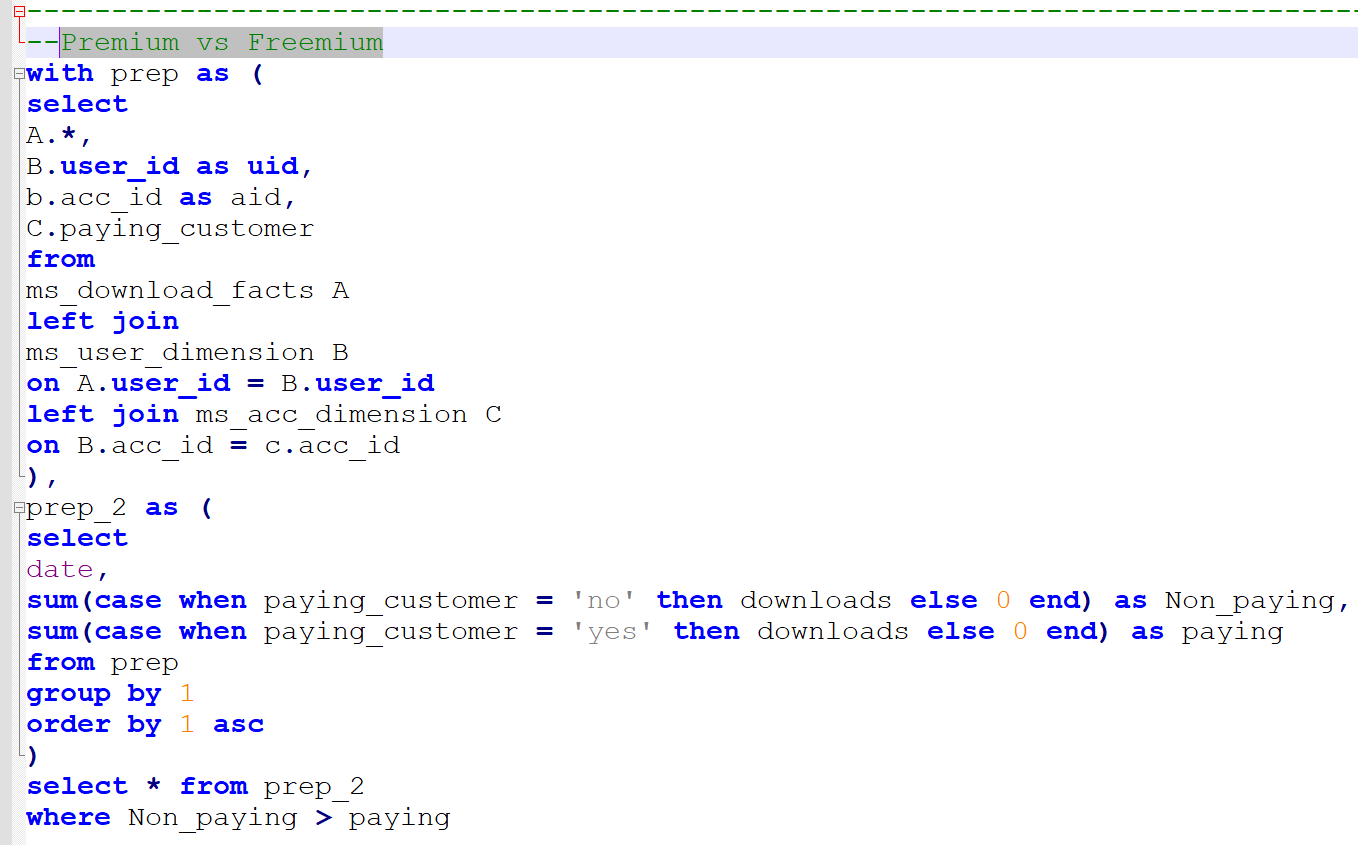
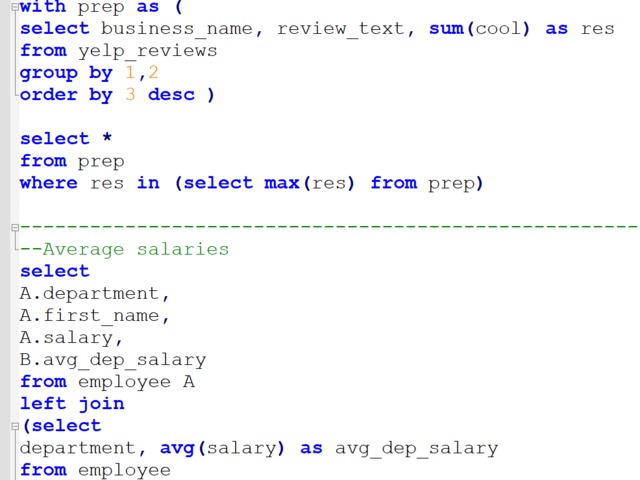
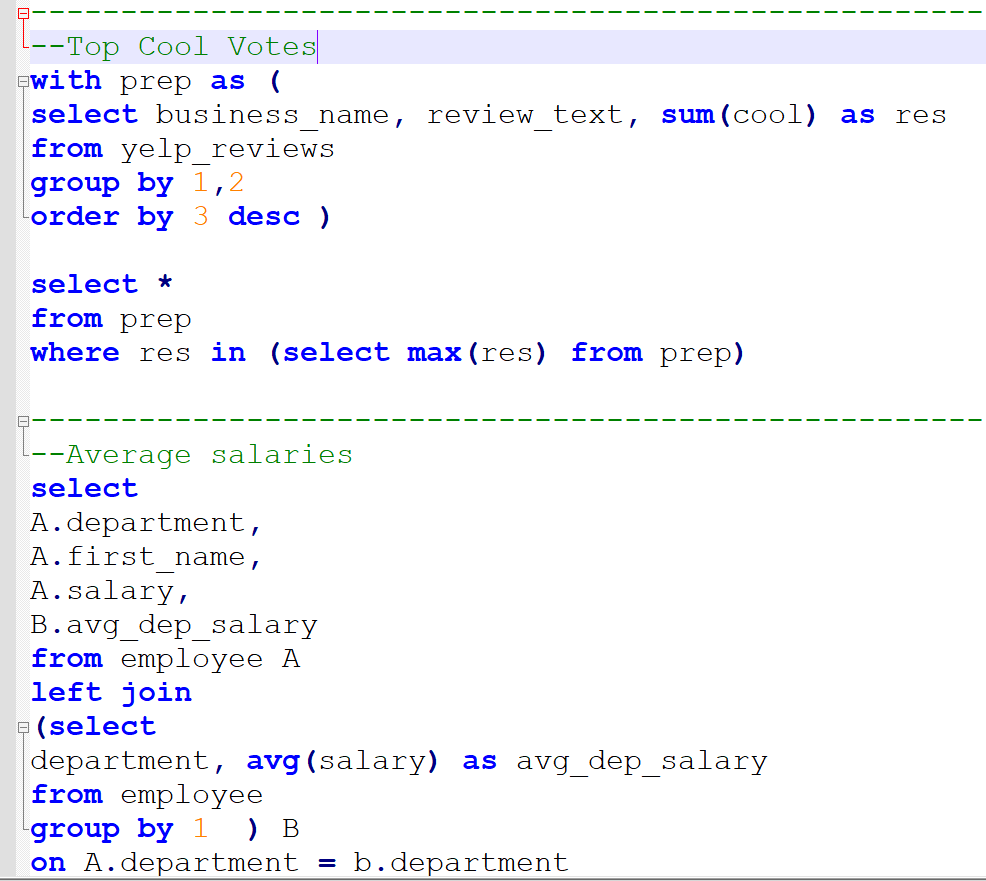
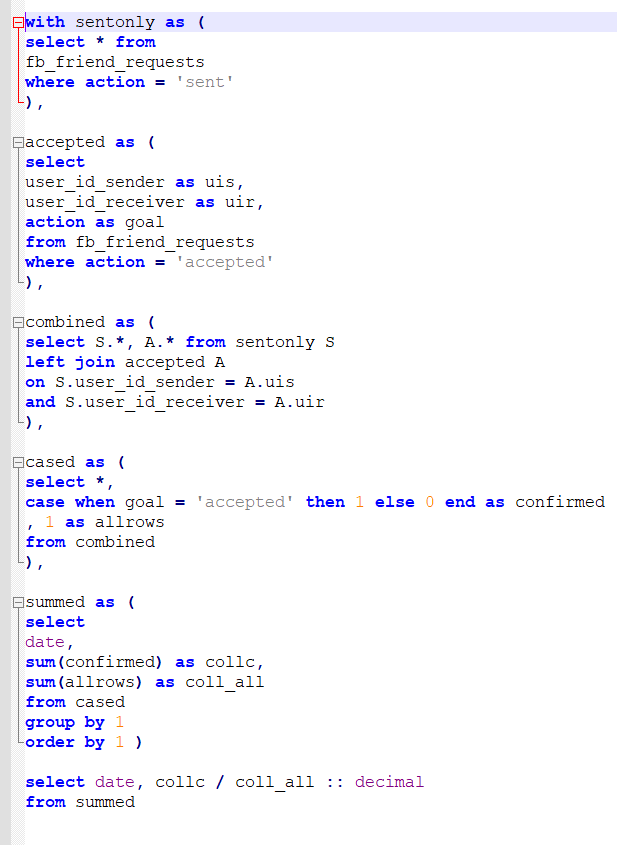
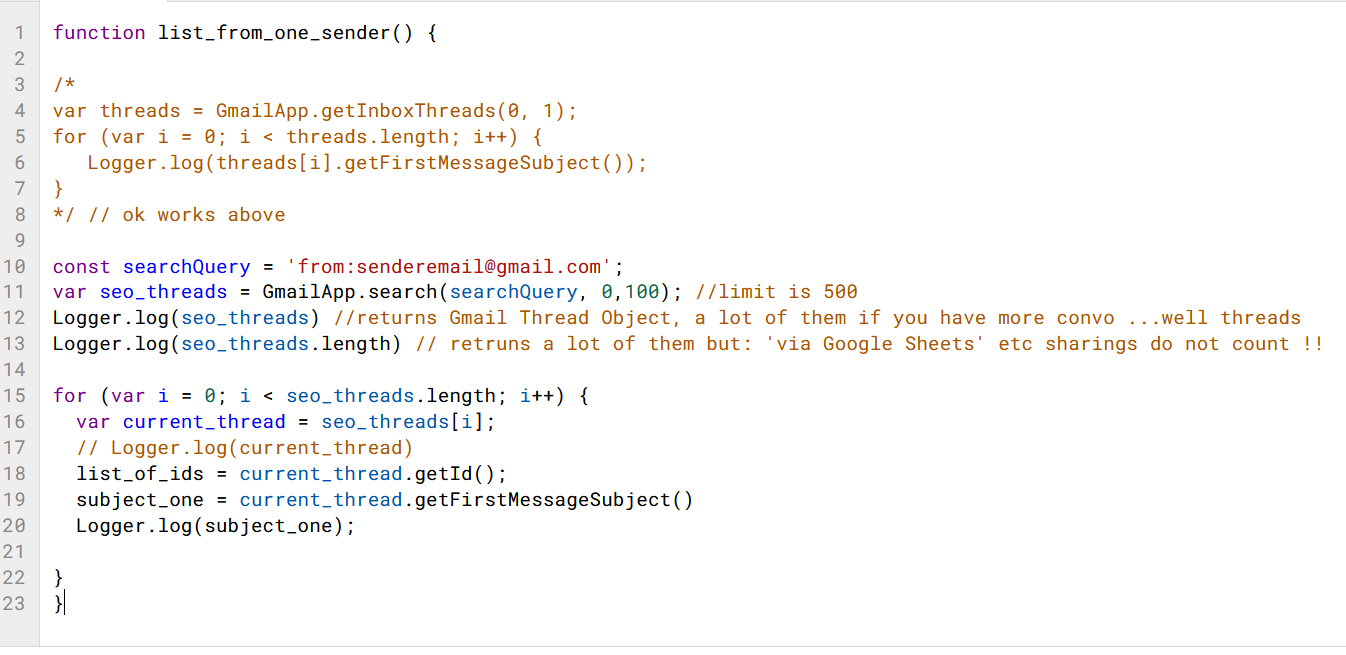
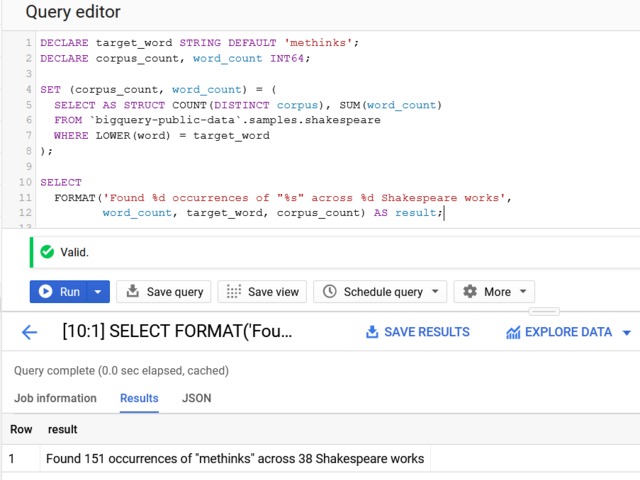
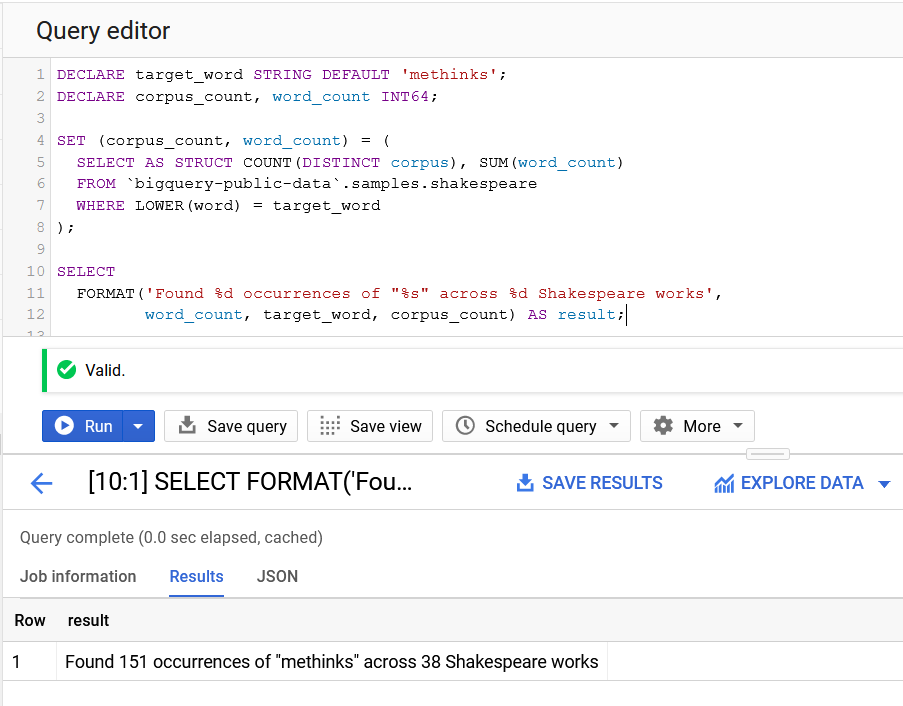
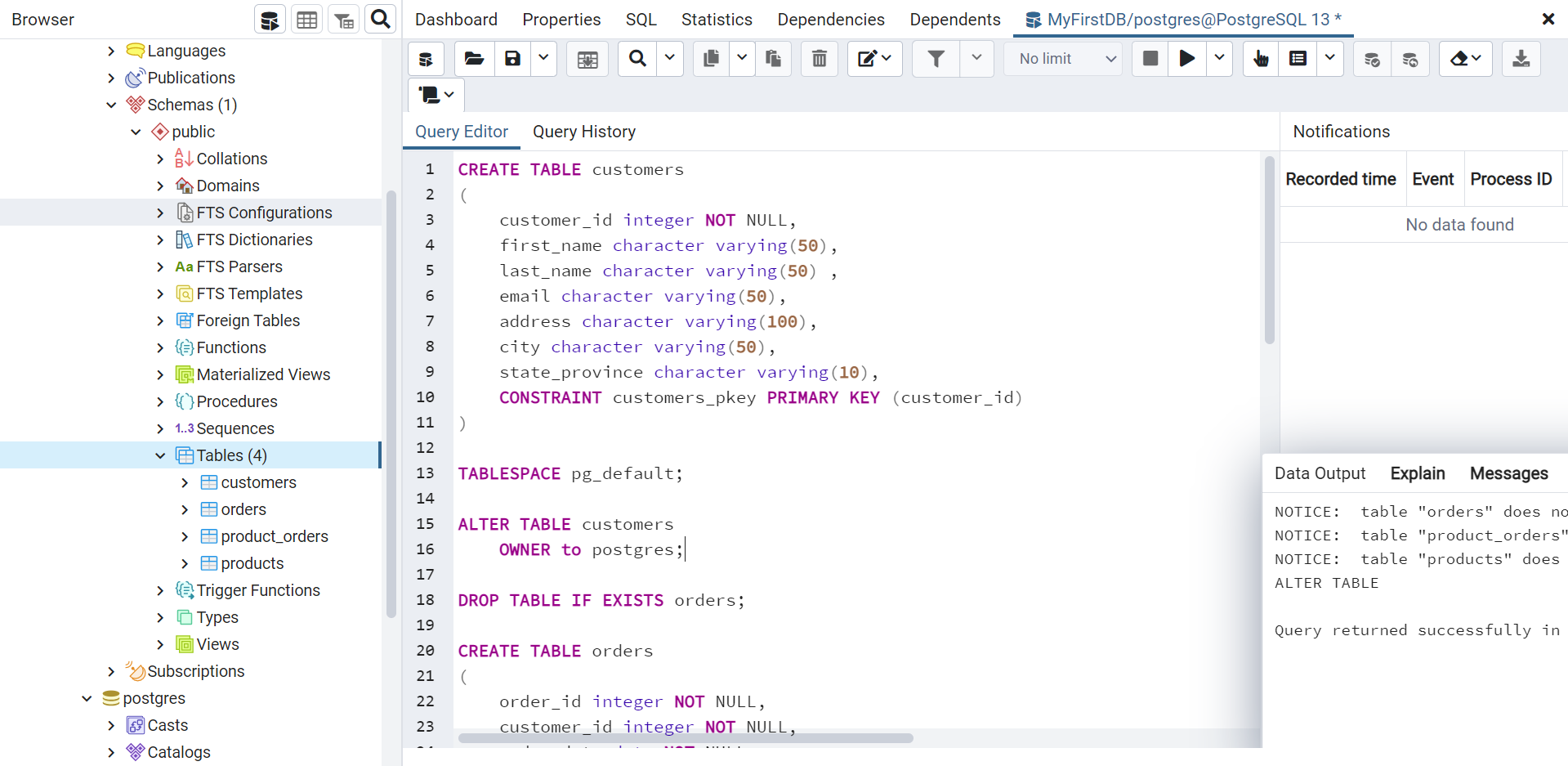
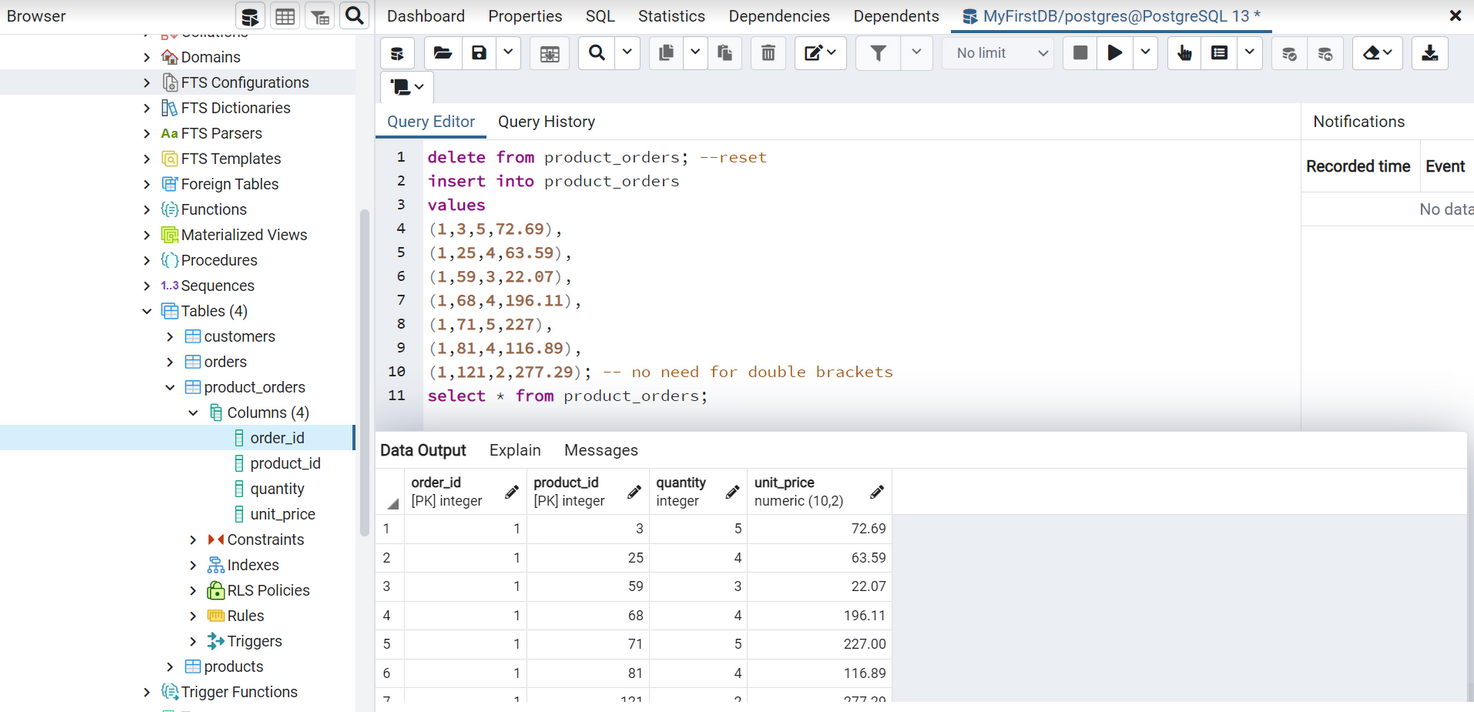
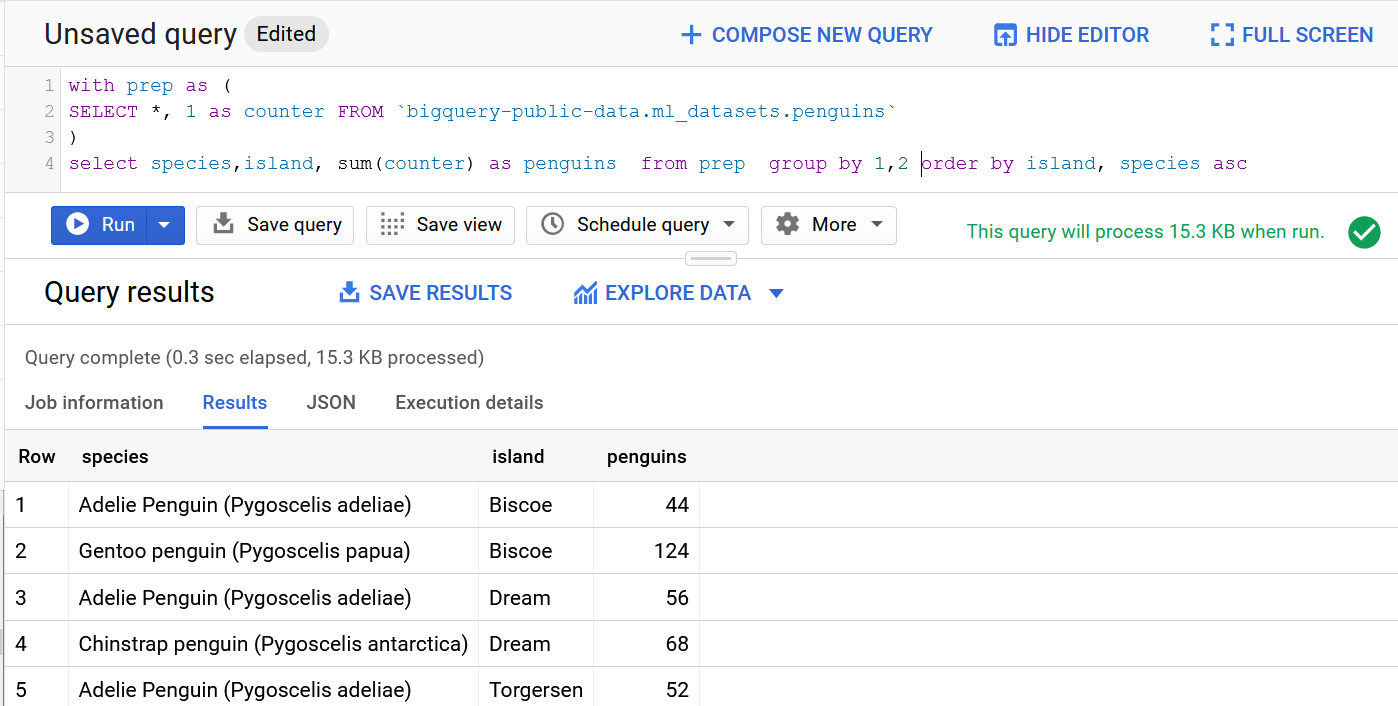
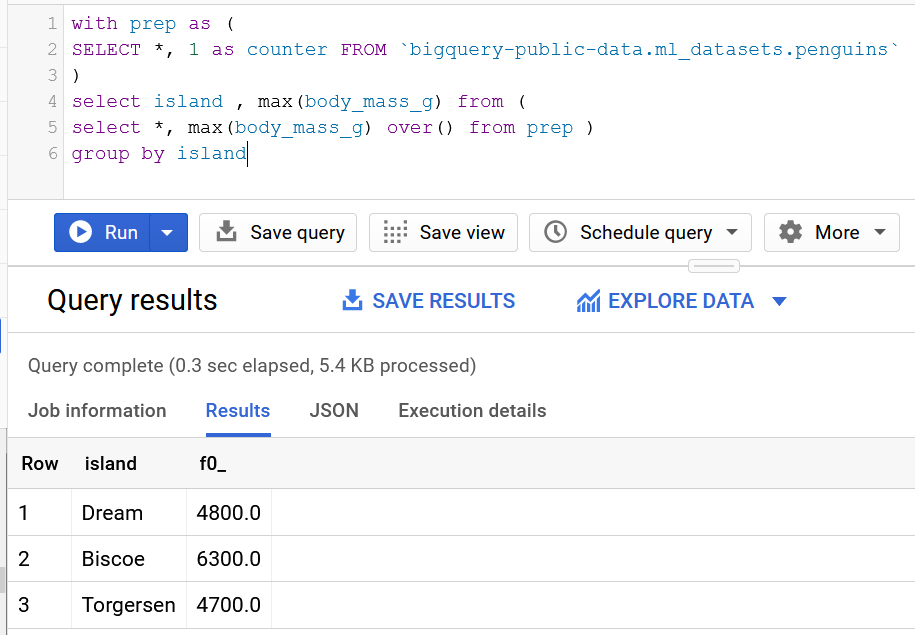
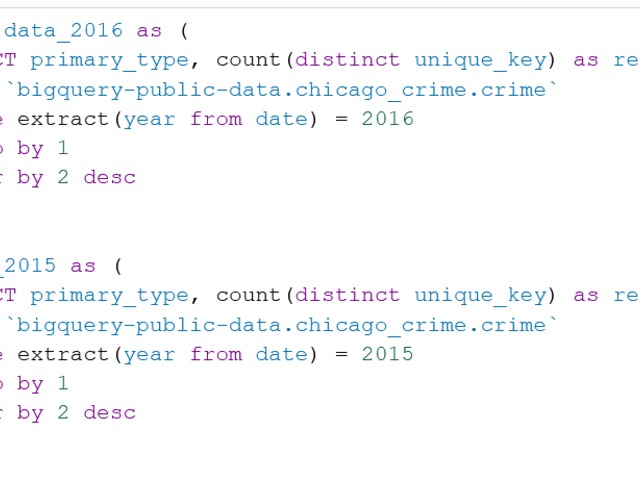
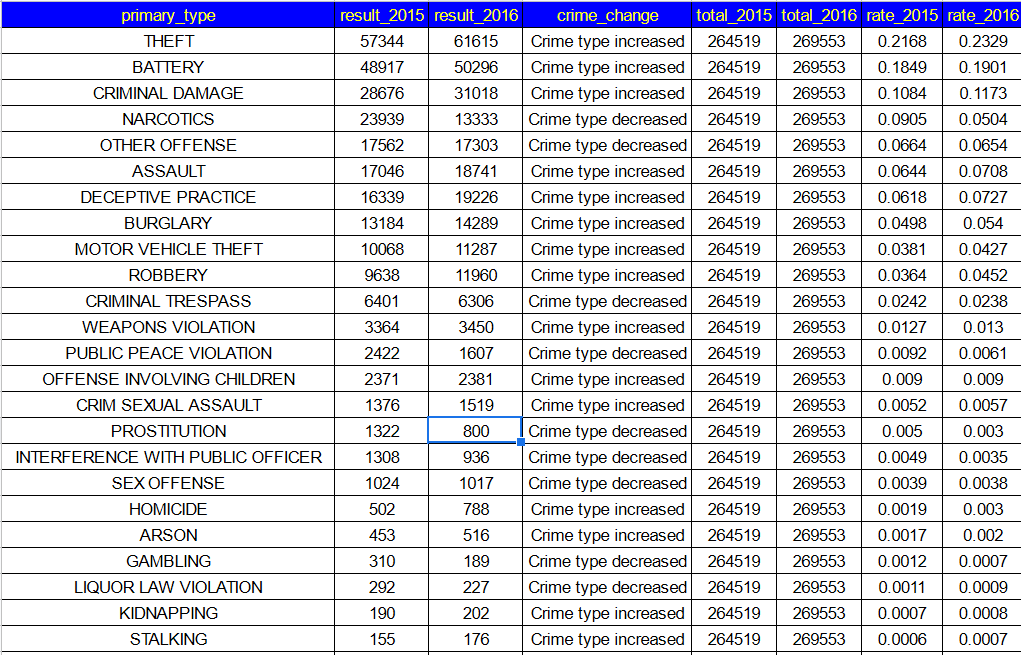
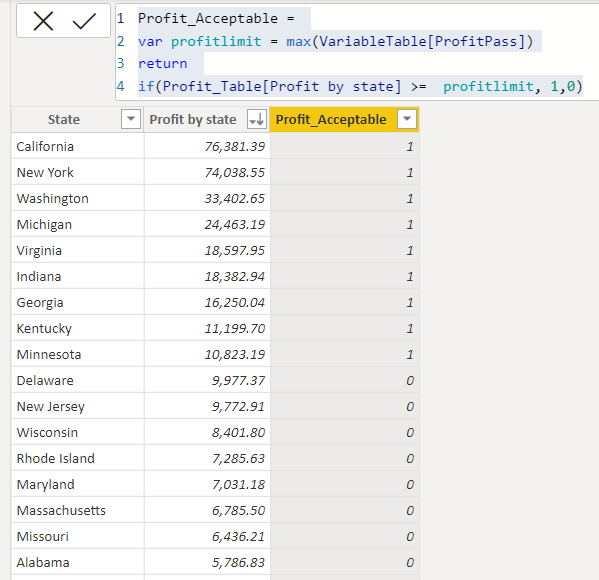
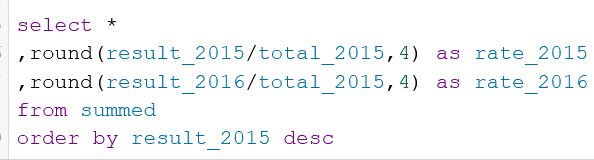Compensation outliers SOLUTION
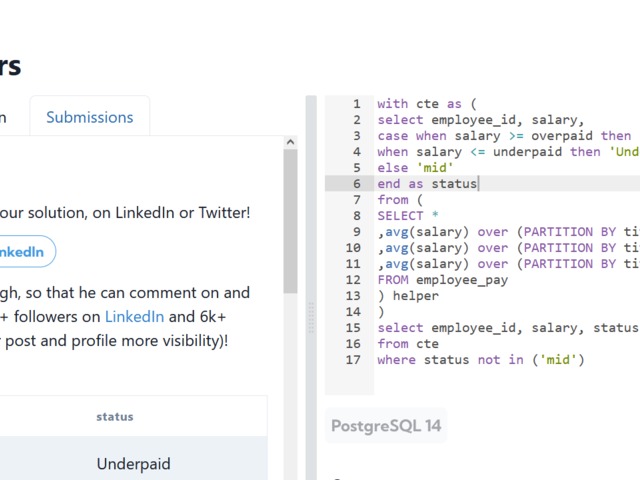
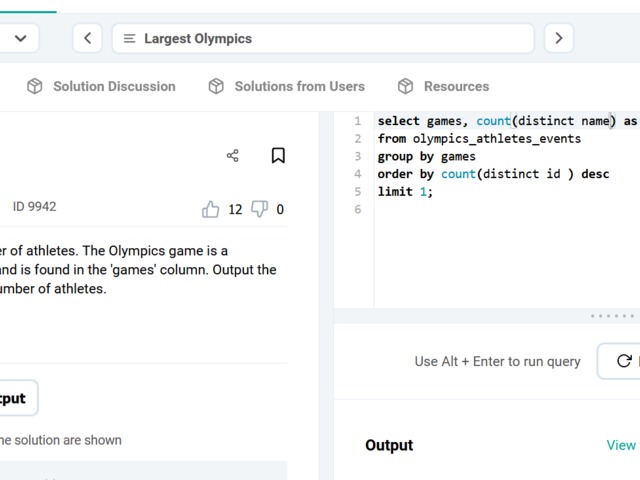
DataLemur, easy tier
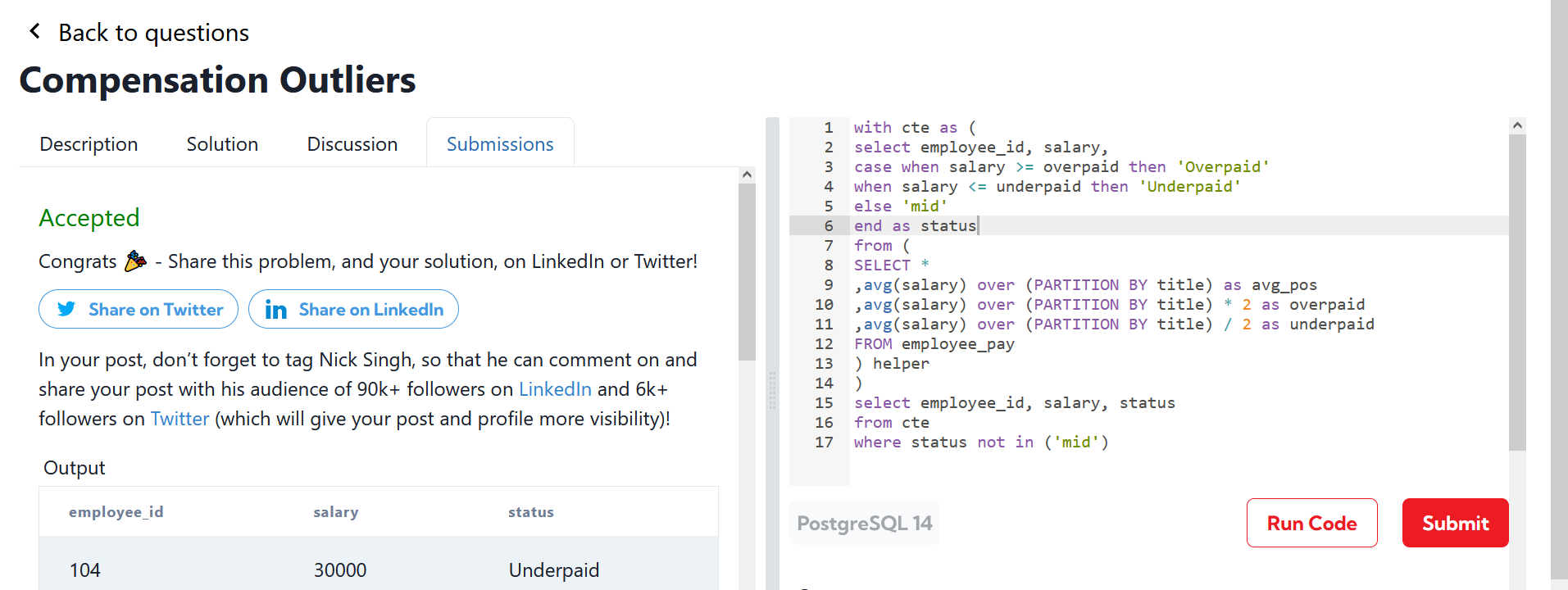
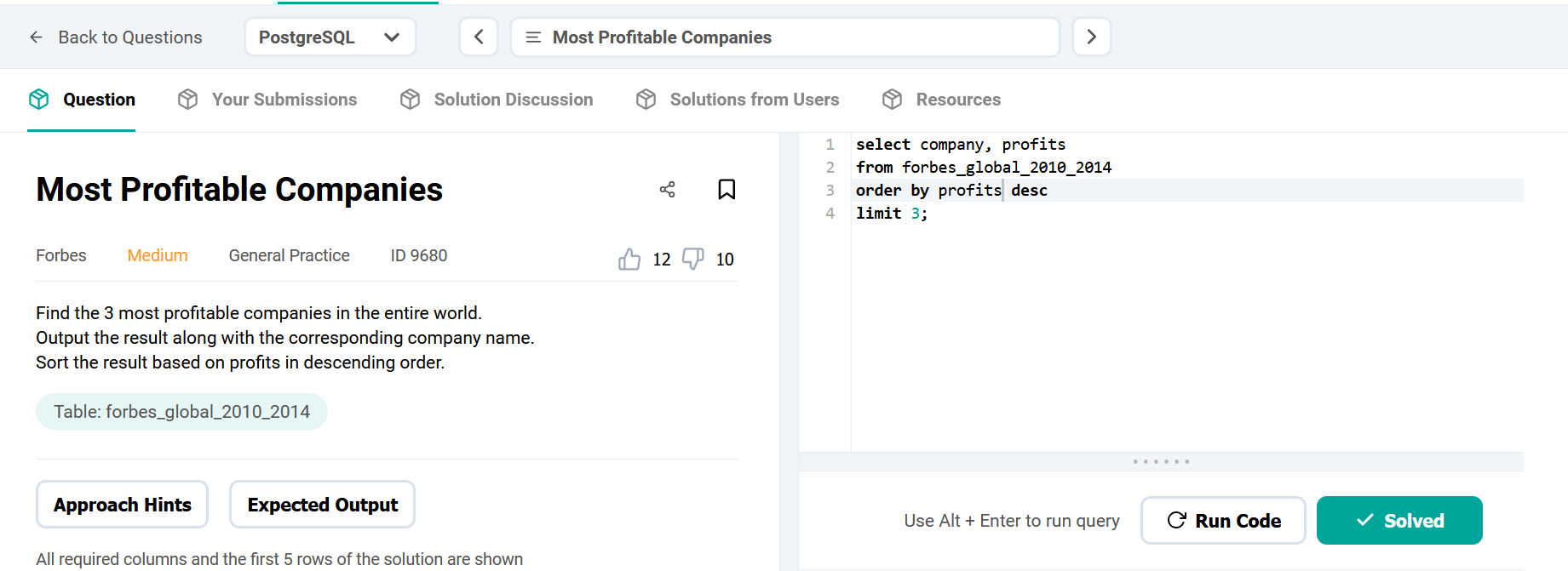
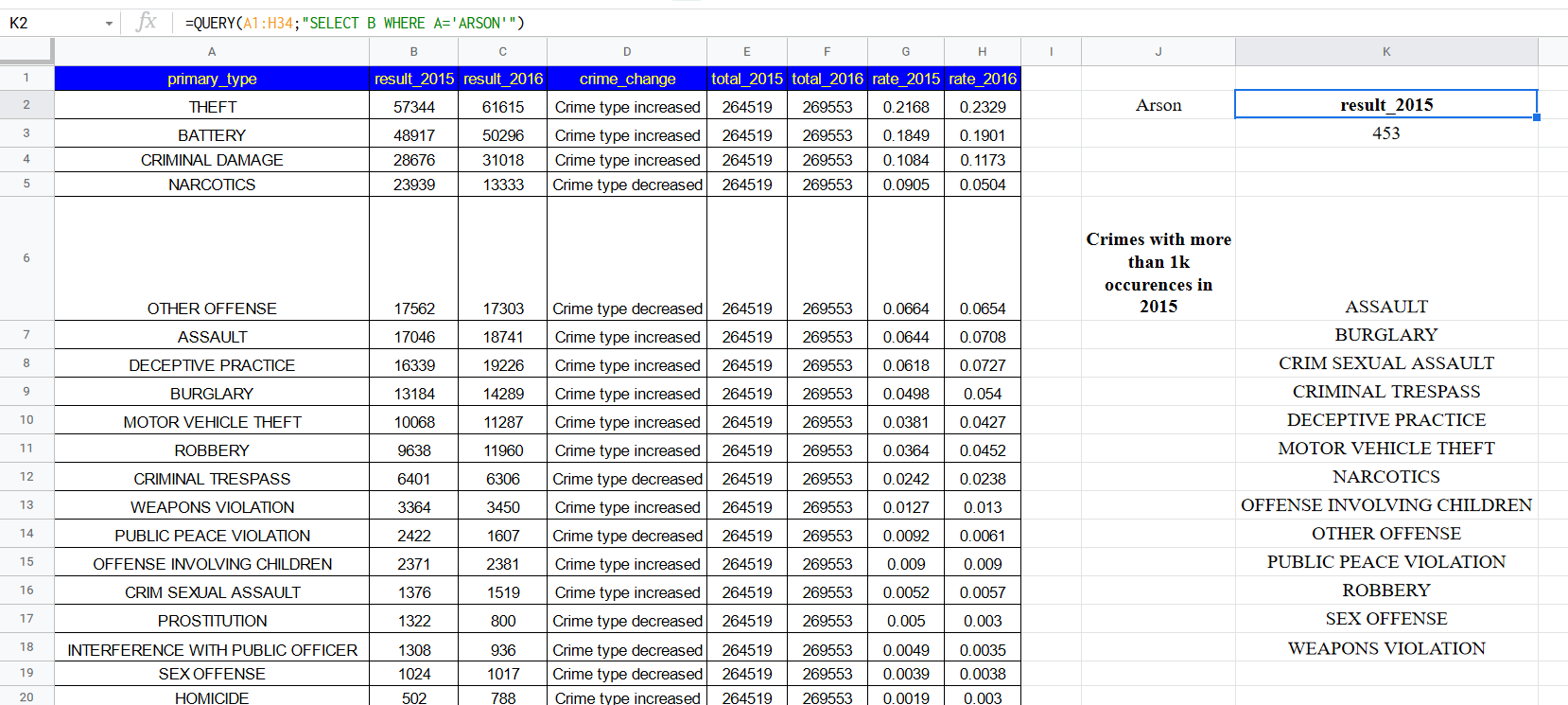
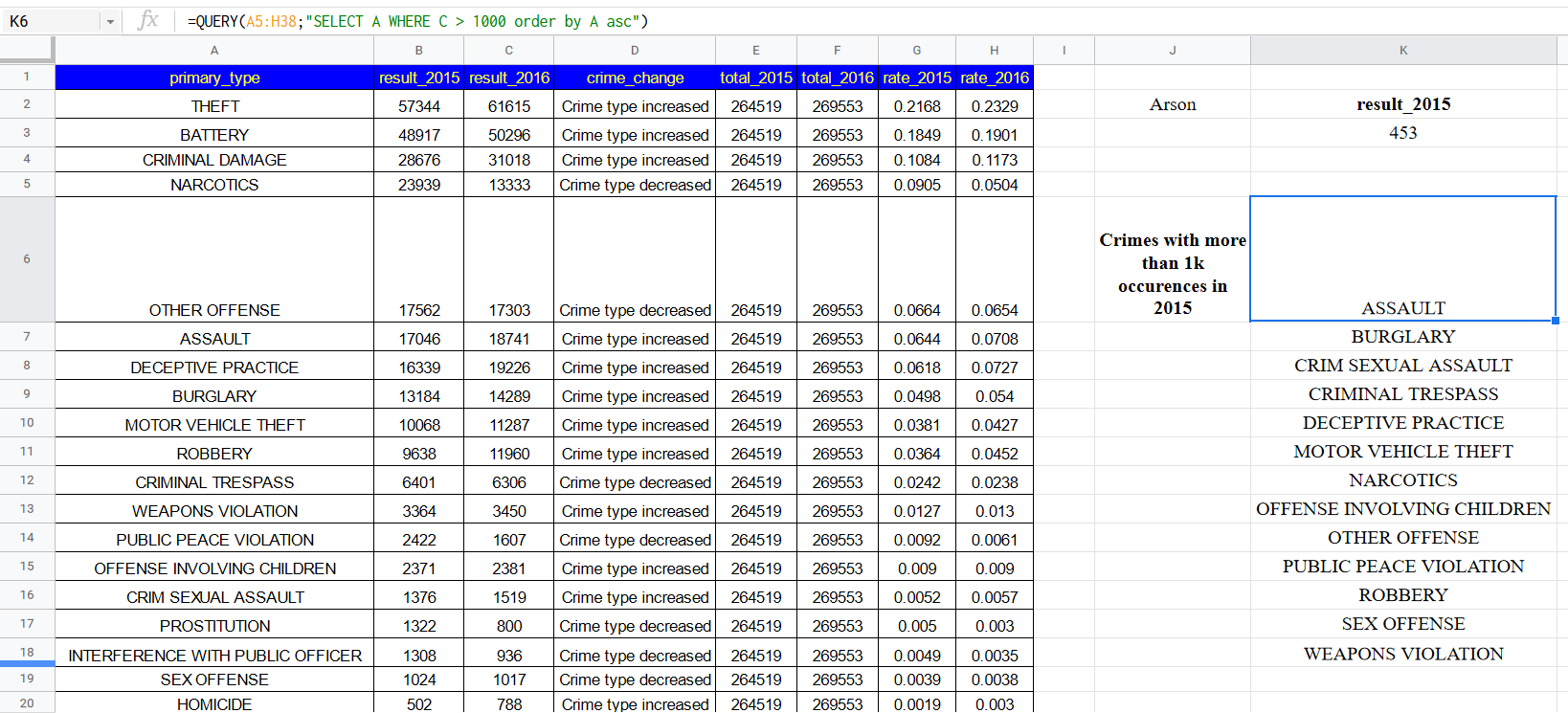
DataLemur, free tier, MEDIUM
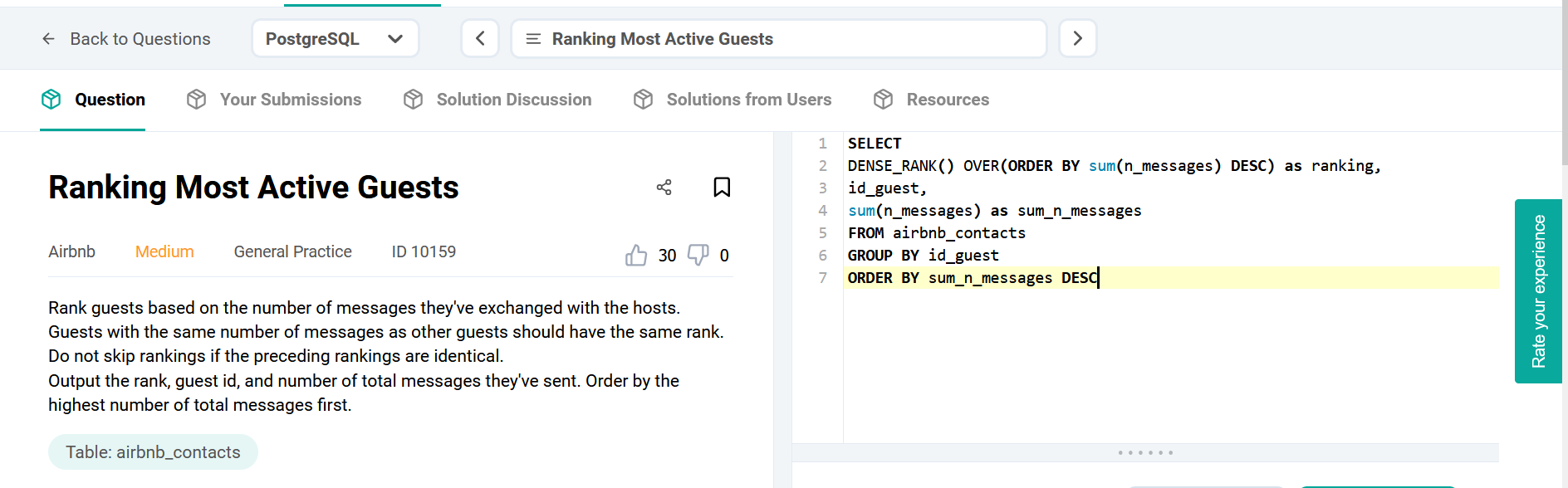
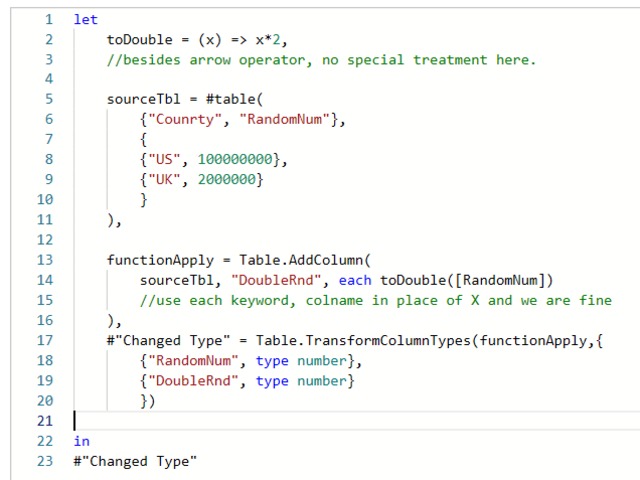
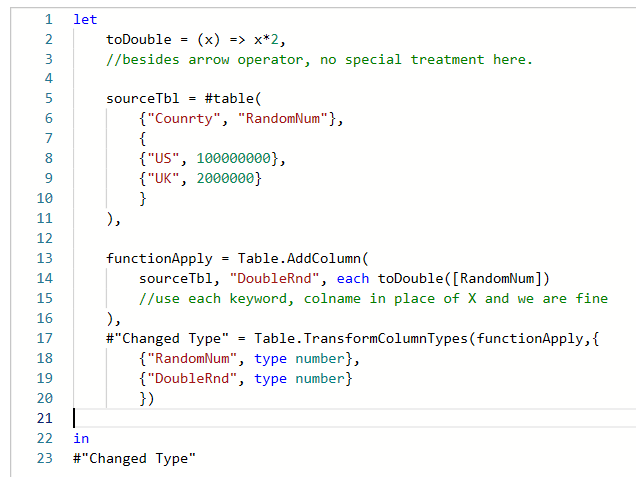
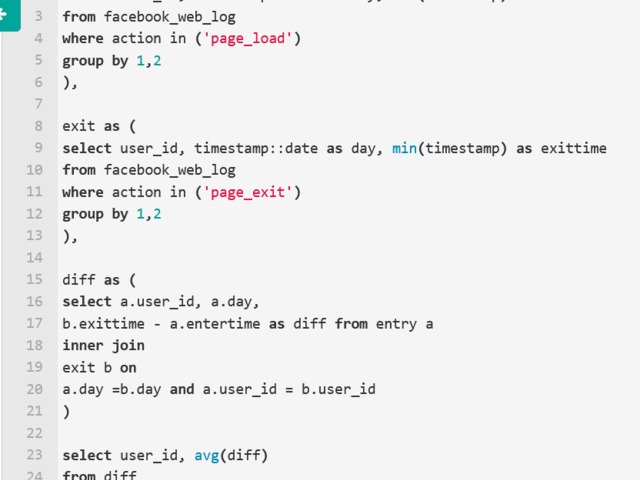
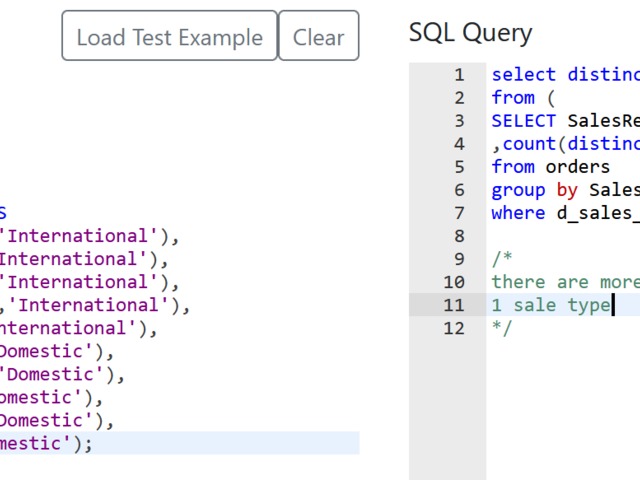
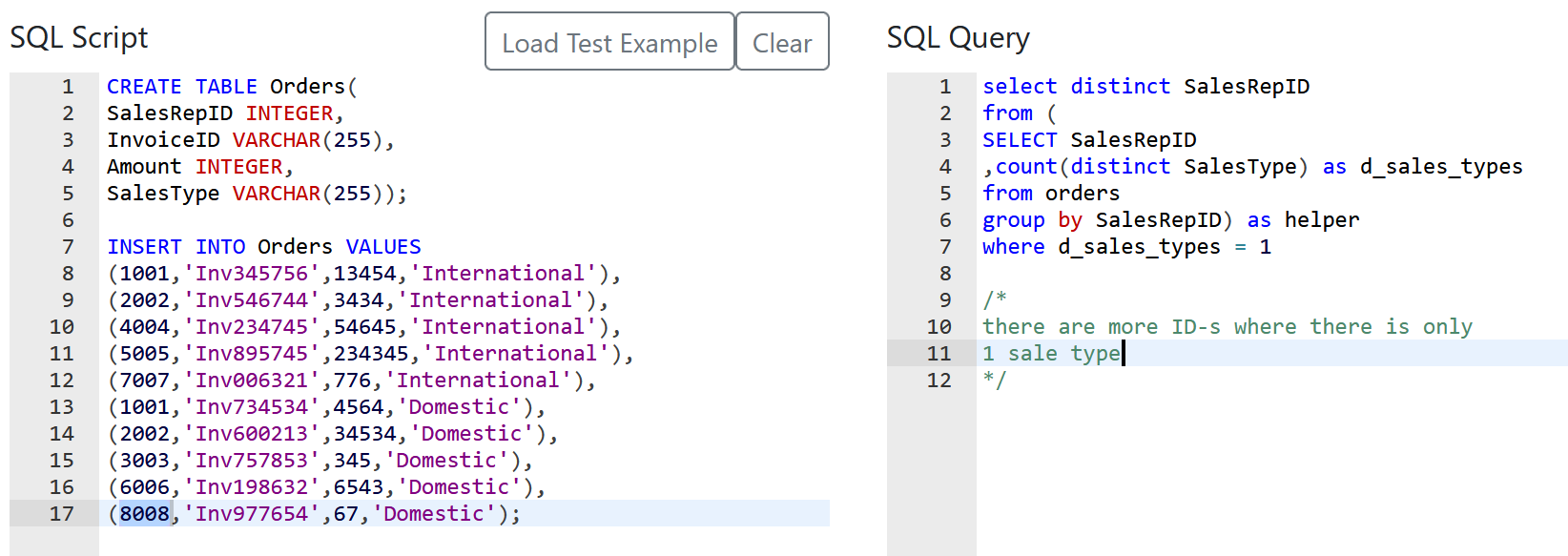
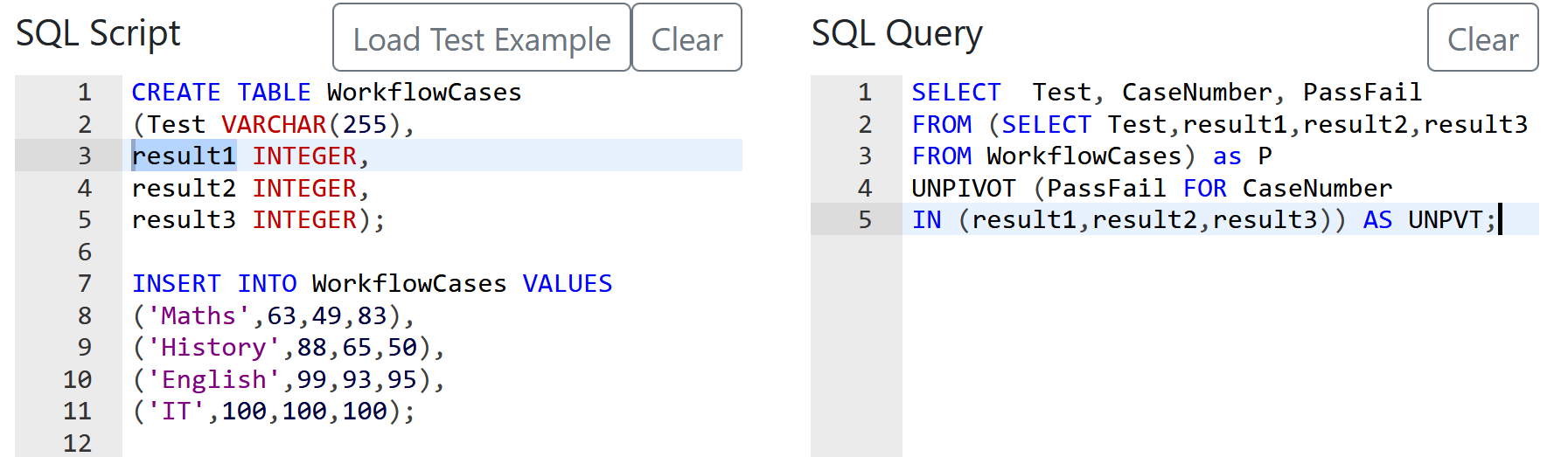
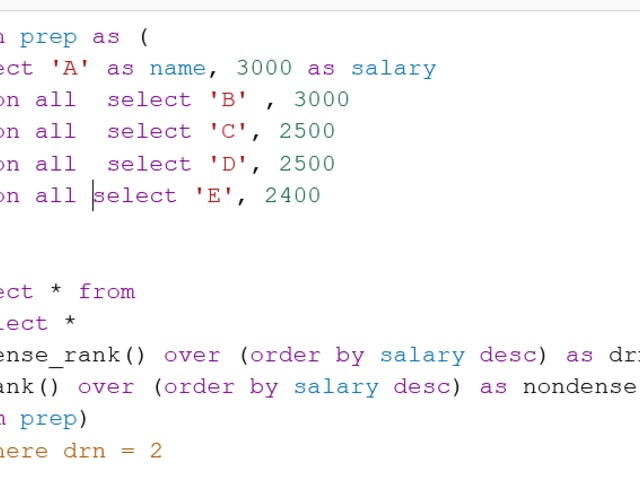
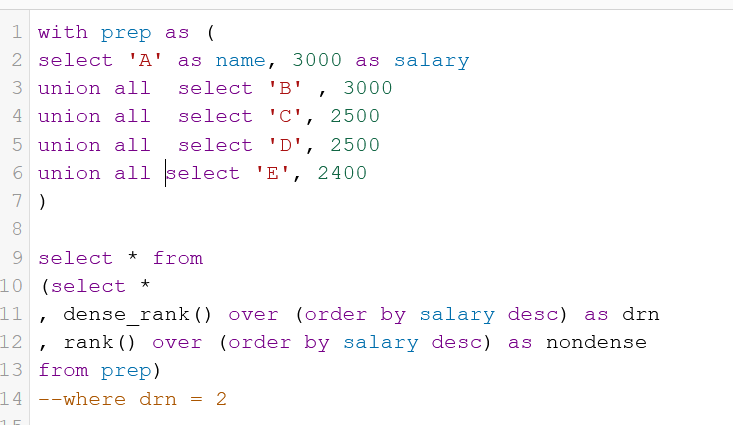
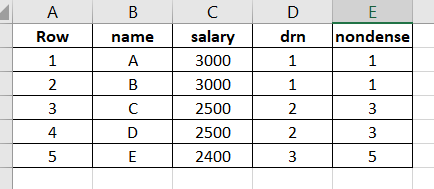
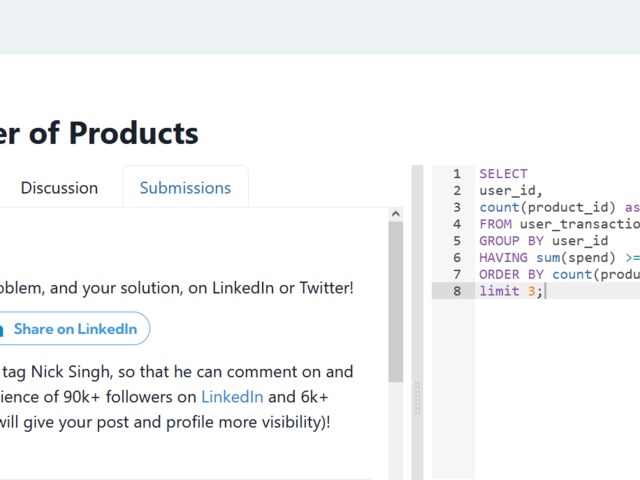
Nothing special here again, use can use CTE or a subselect, the main target of this question was to get you to use RANK() or ROW_NUMBER() WINDOW FUNCTION.
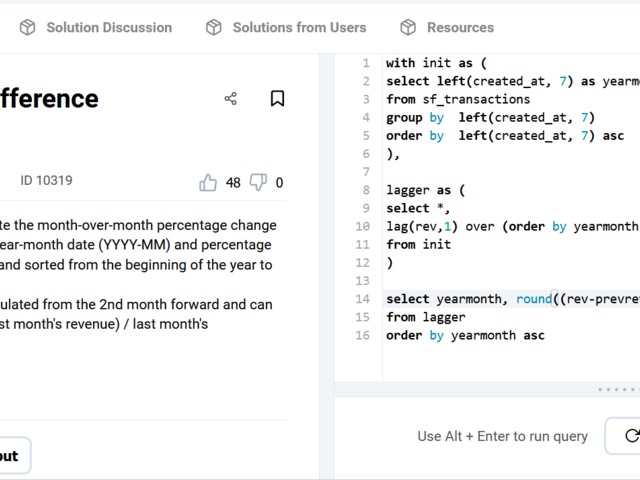
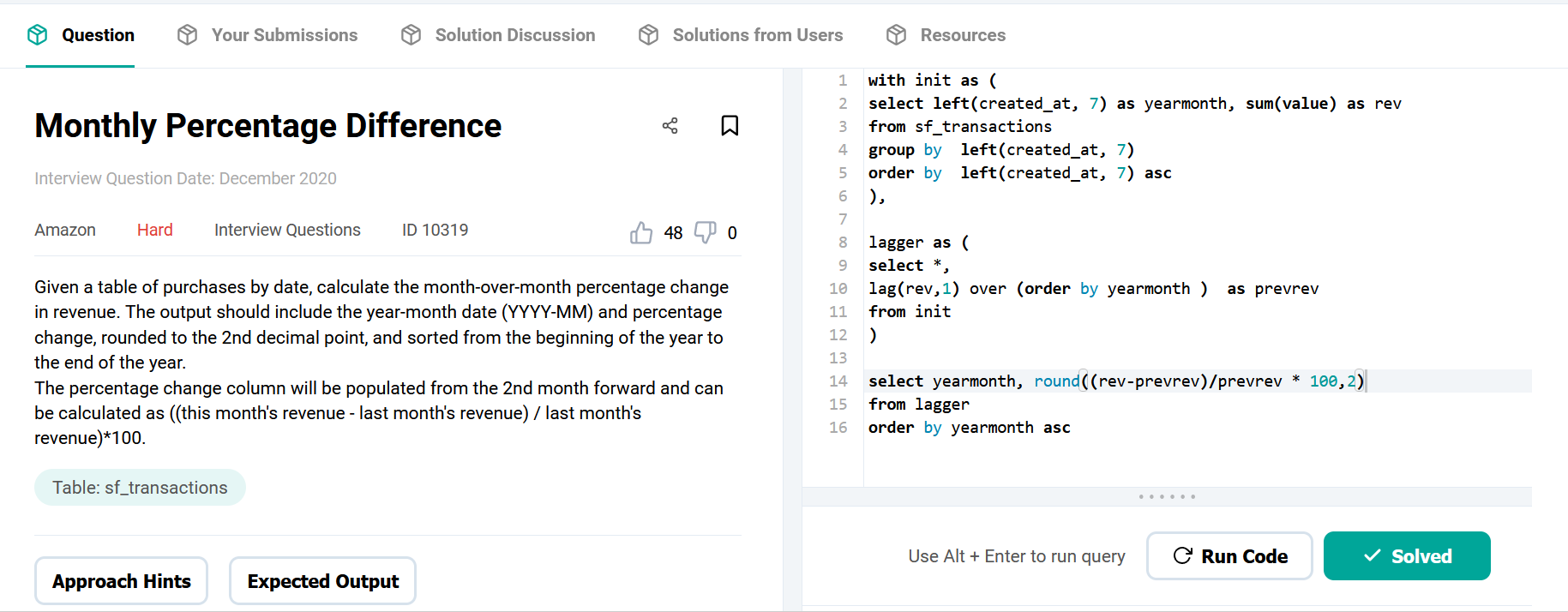
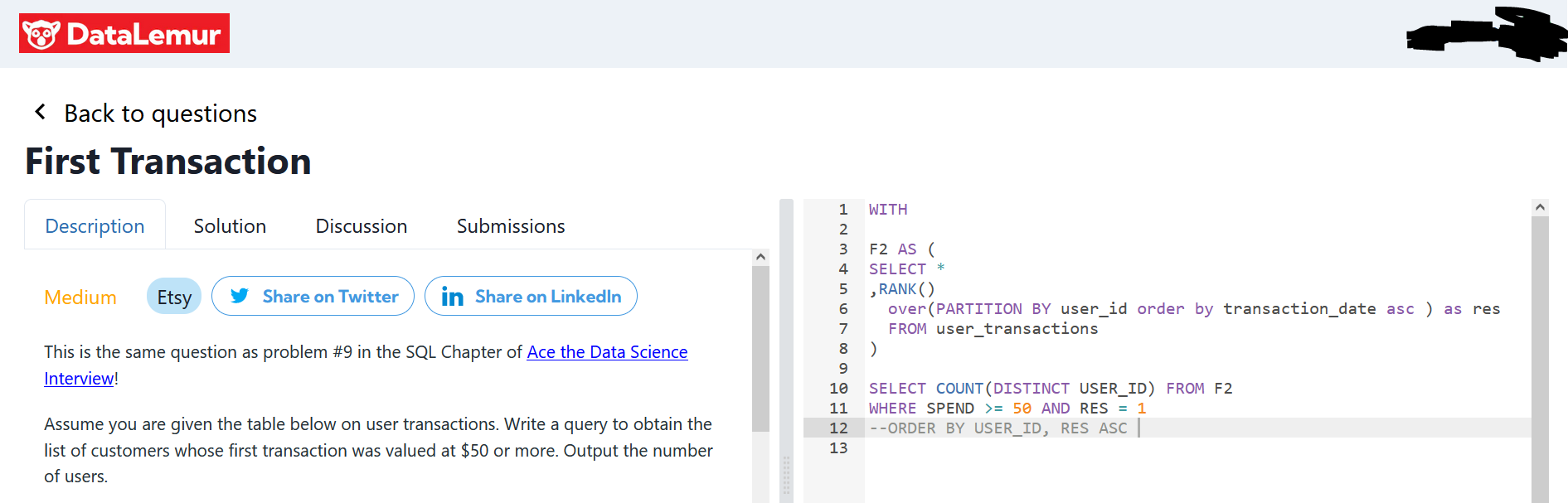
DataLemur, free tier
This goes over the basics pretty much.
use of aggregates
use of HAVING
use of multiple order by conditions
use of limit;
Not tricky
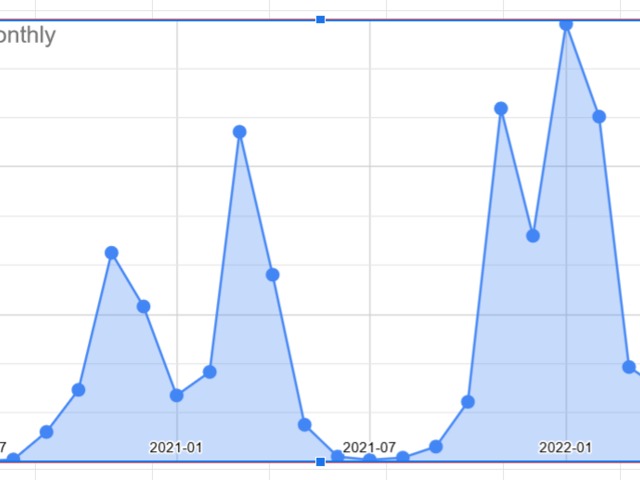
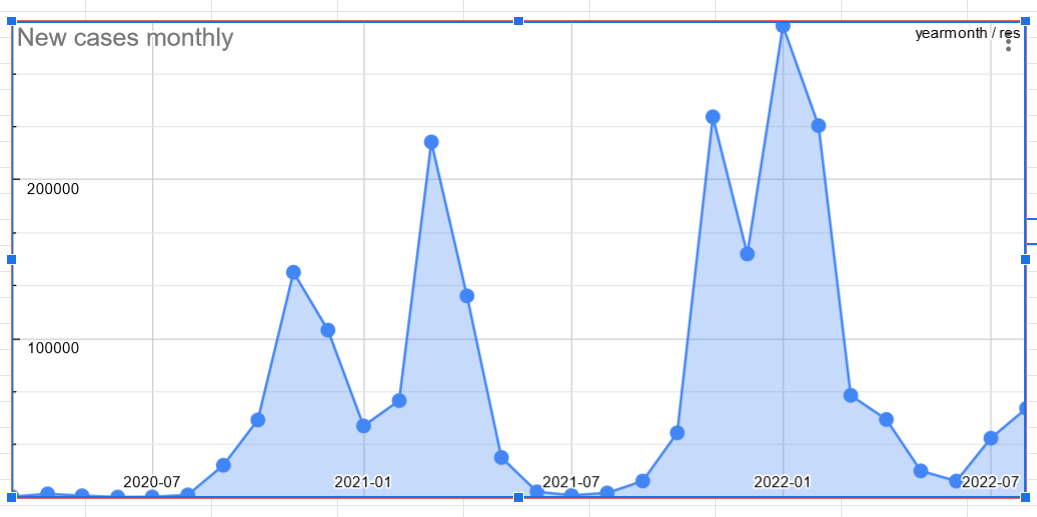
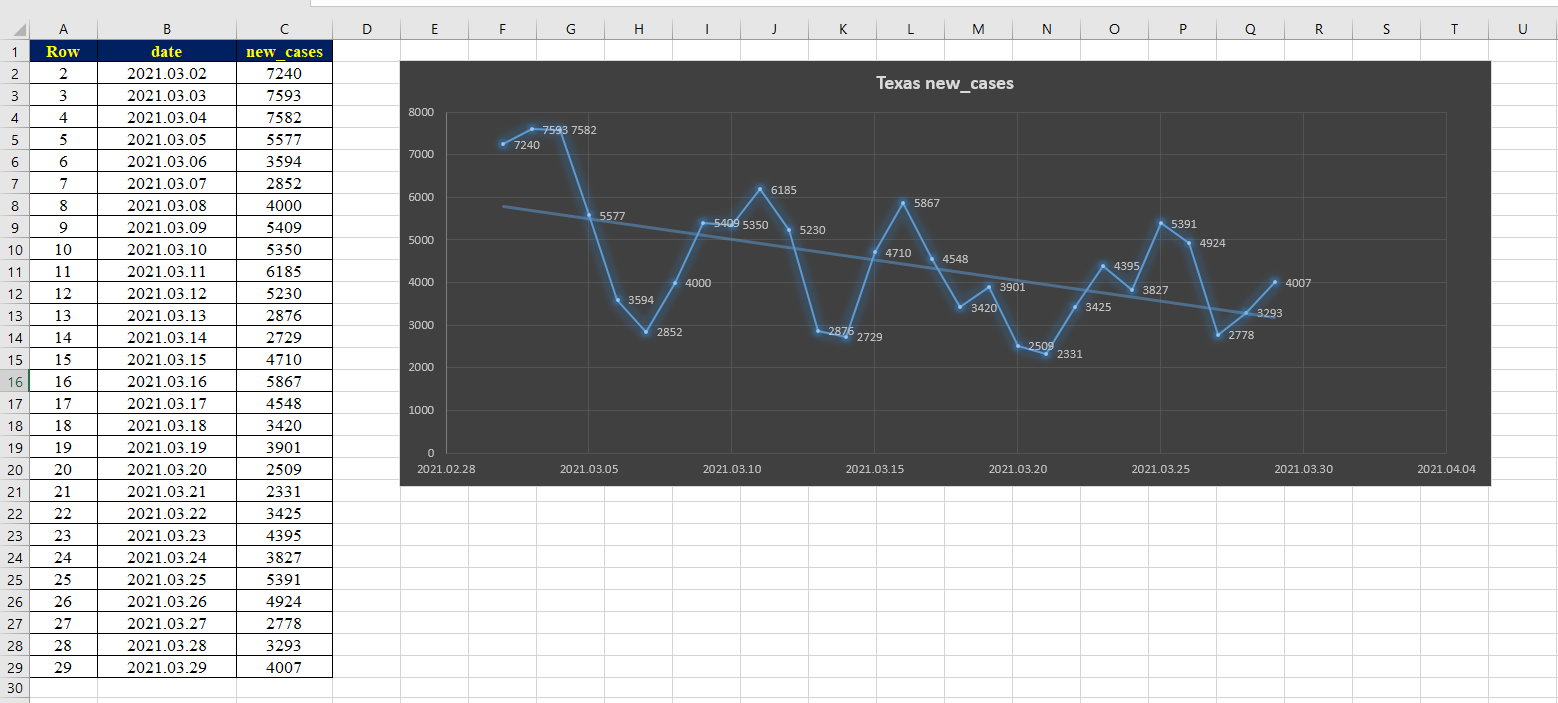
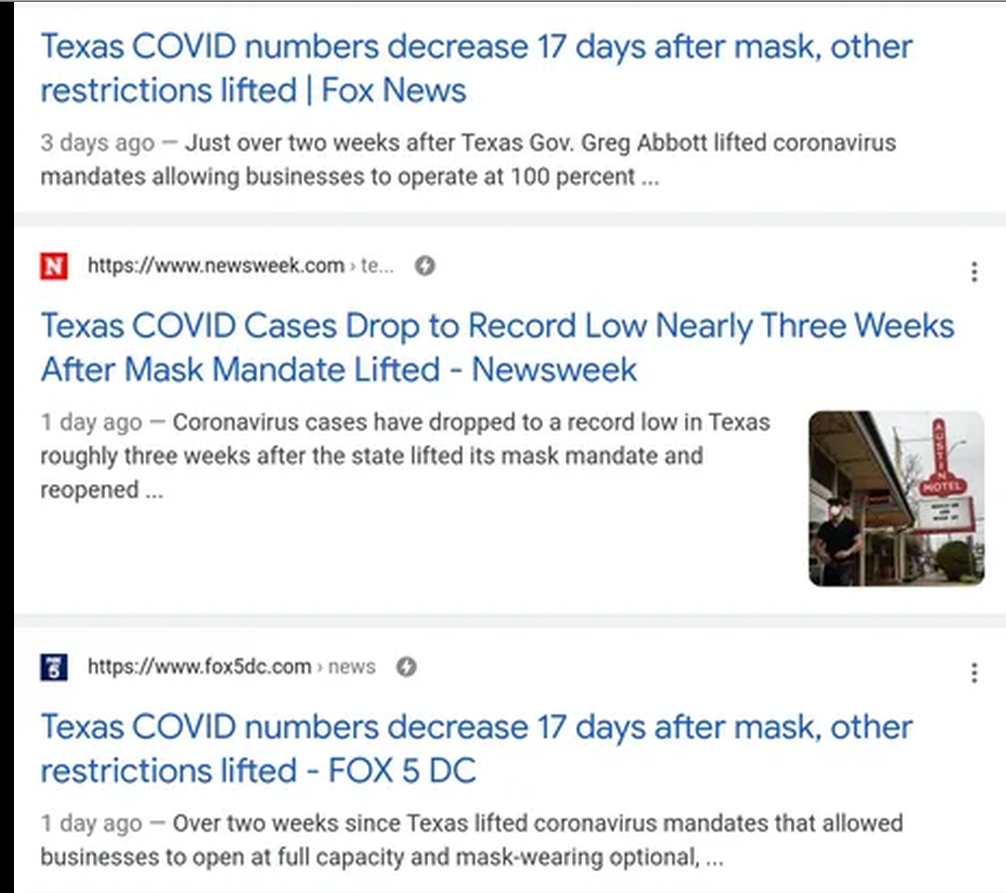
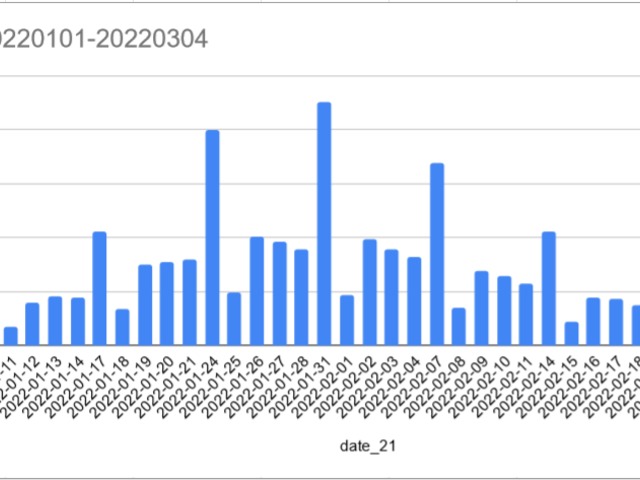
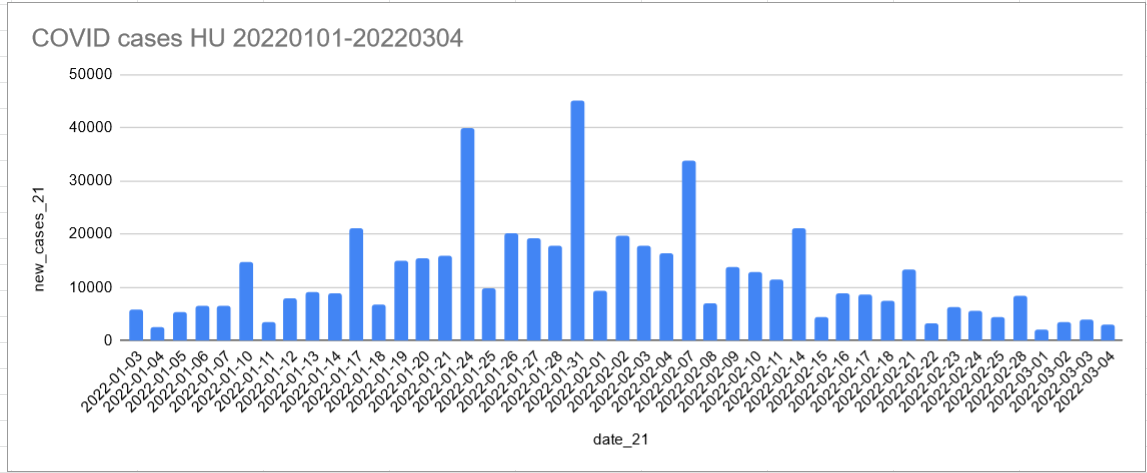
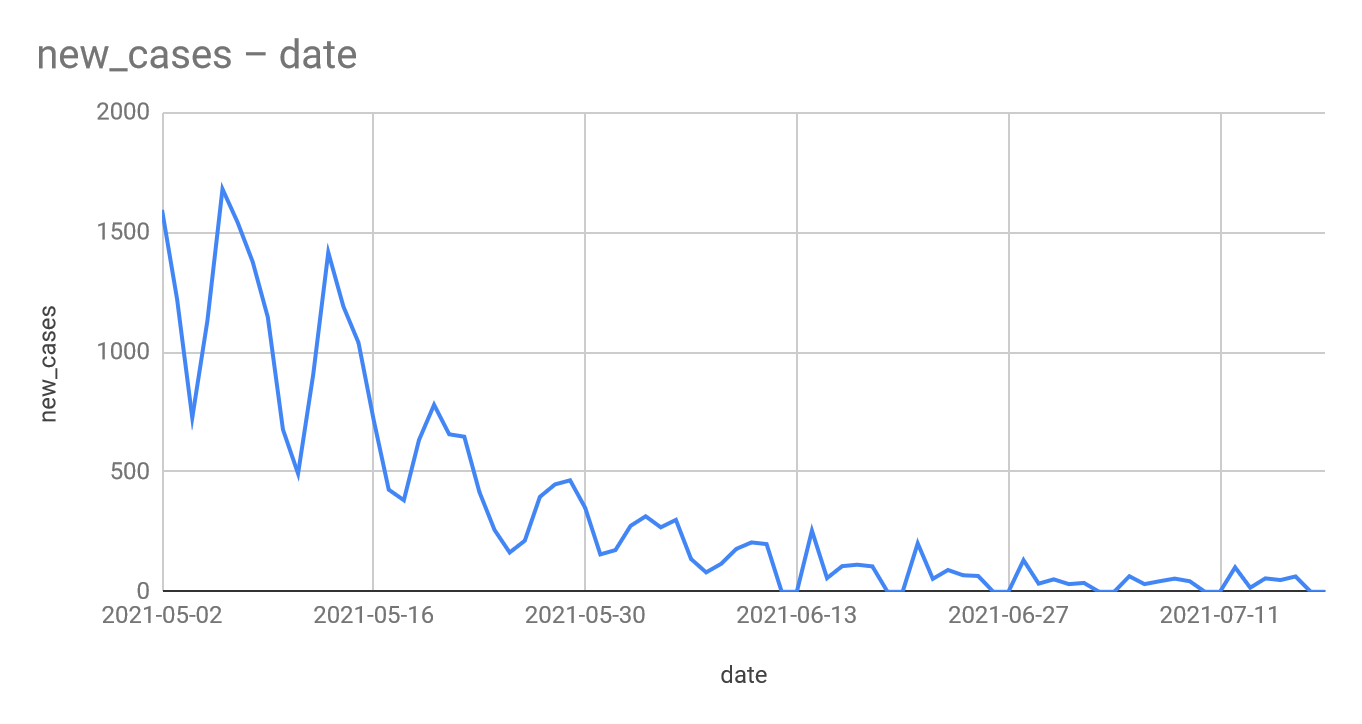
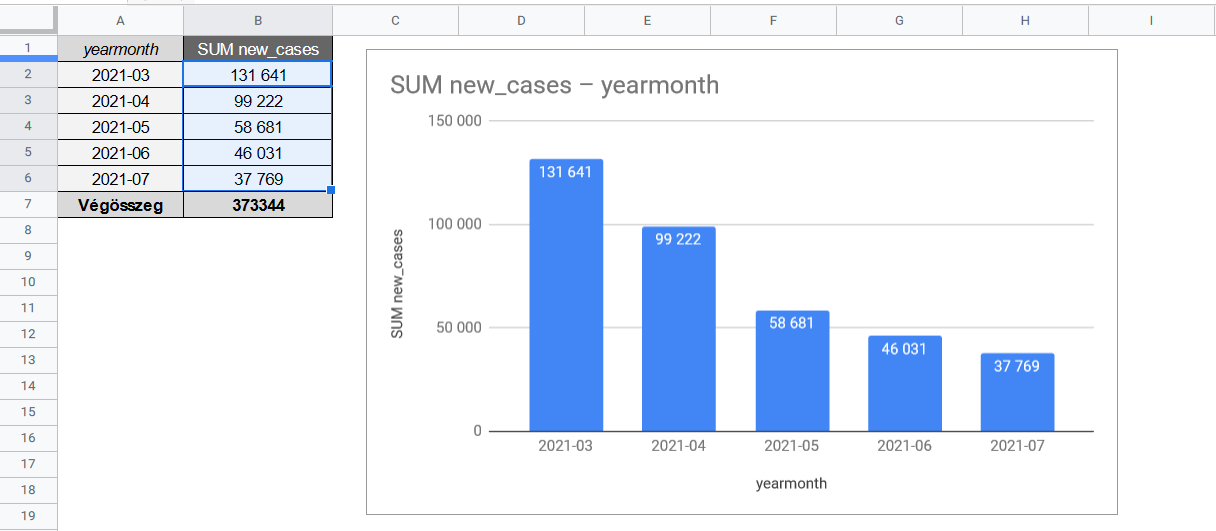
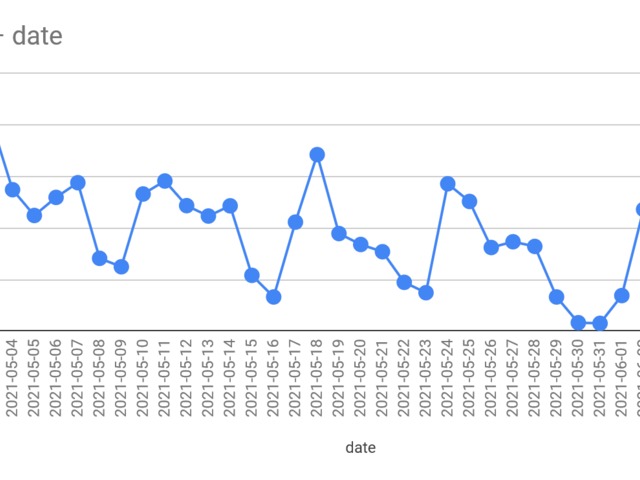
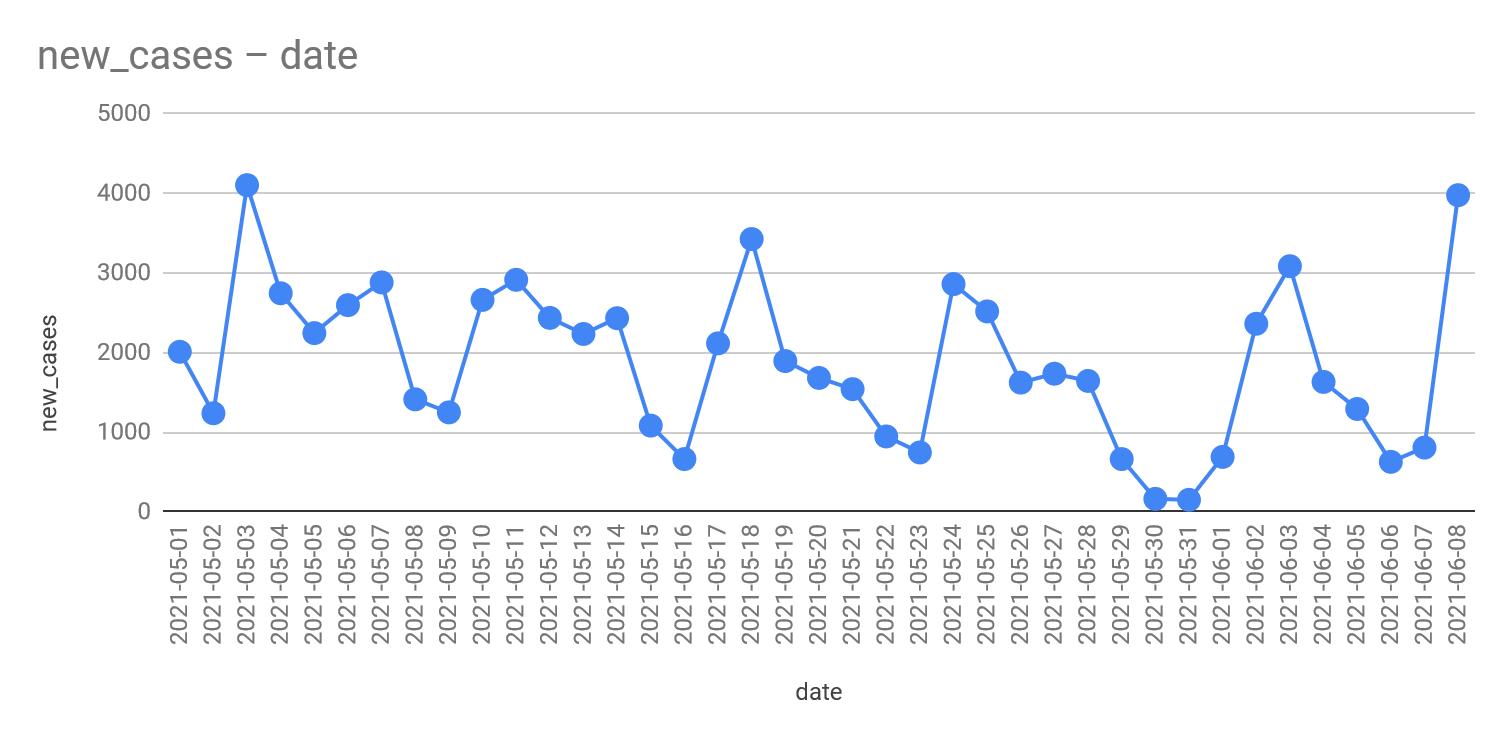
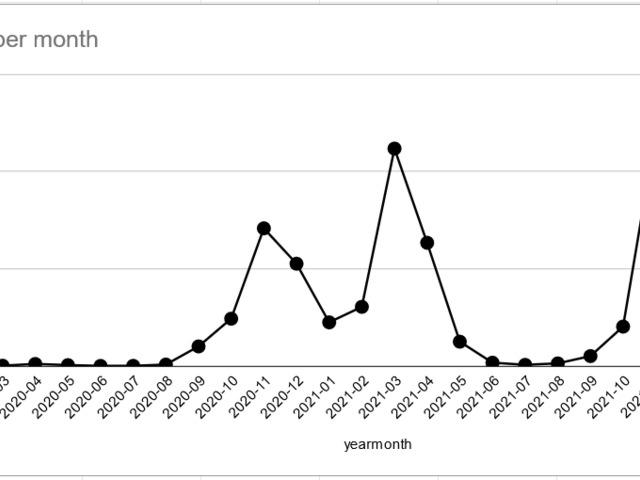
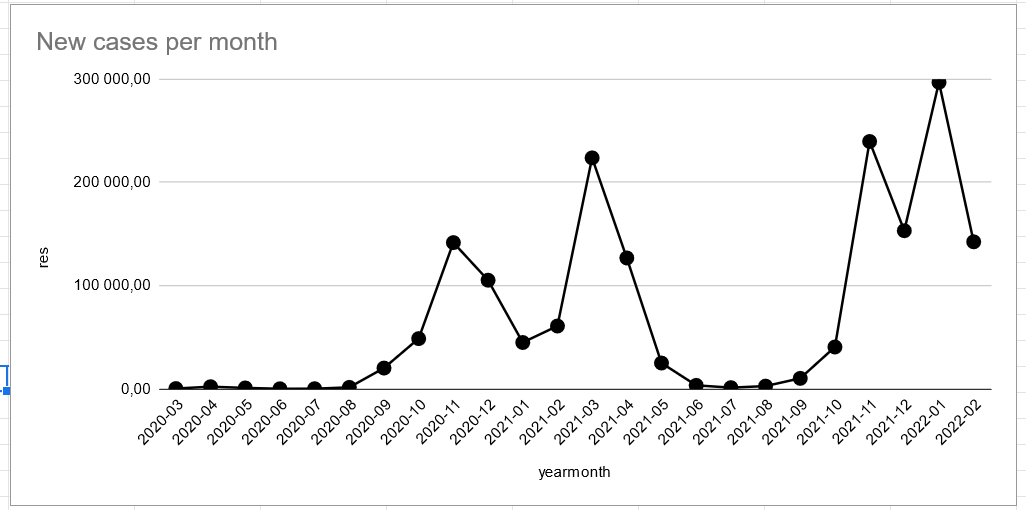
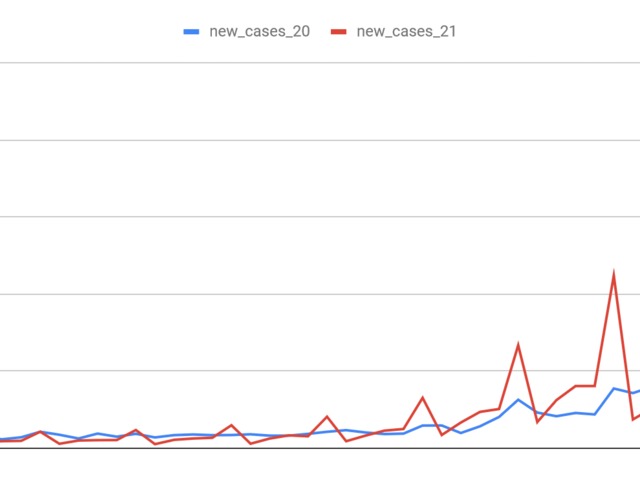
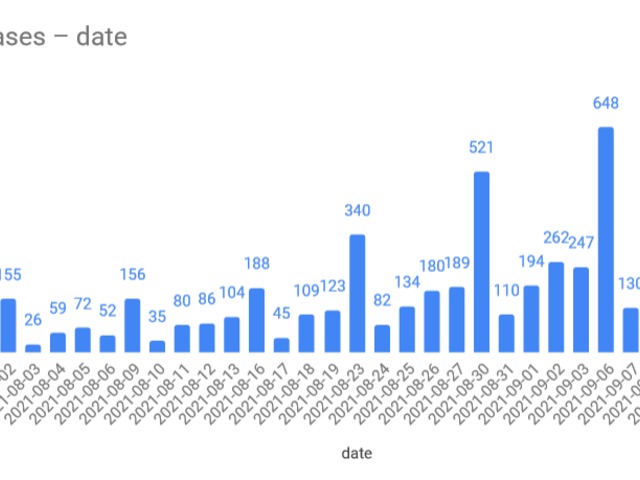
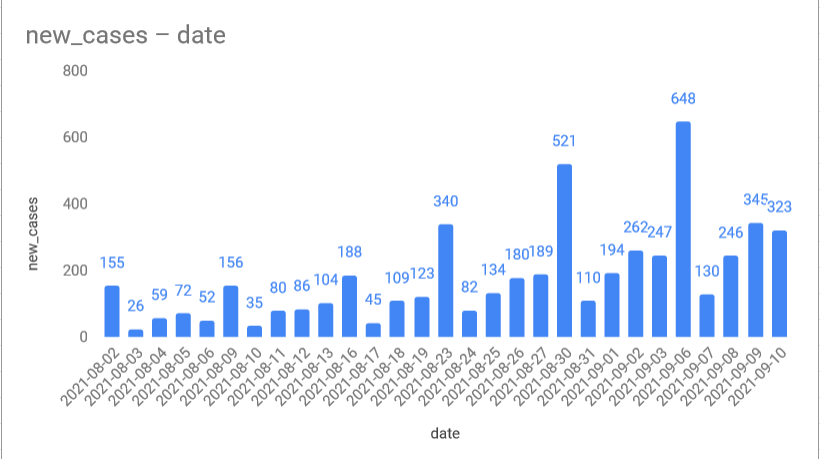
-spike in the winter is bigger than last year
-even summer cases are higher this year
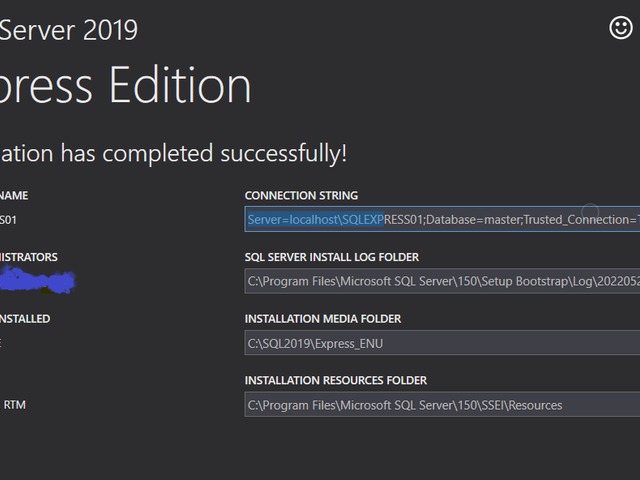
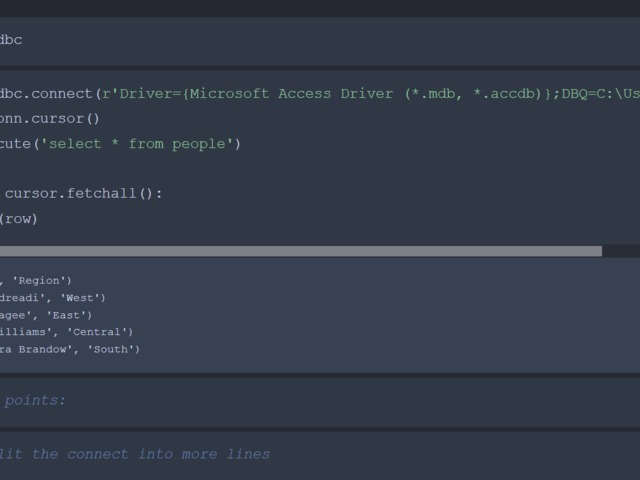
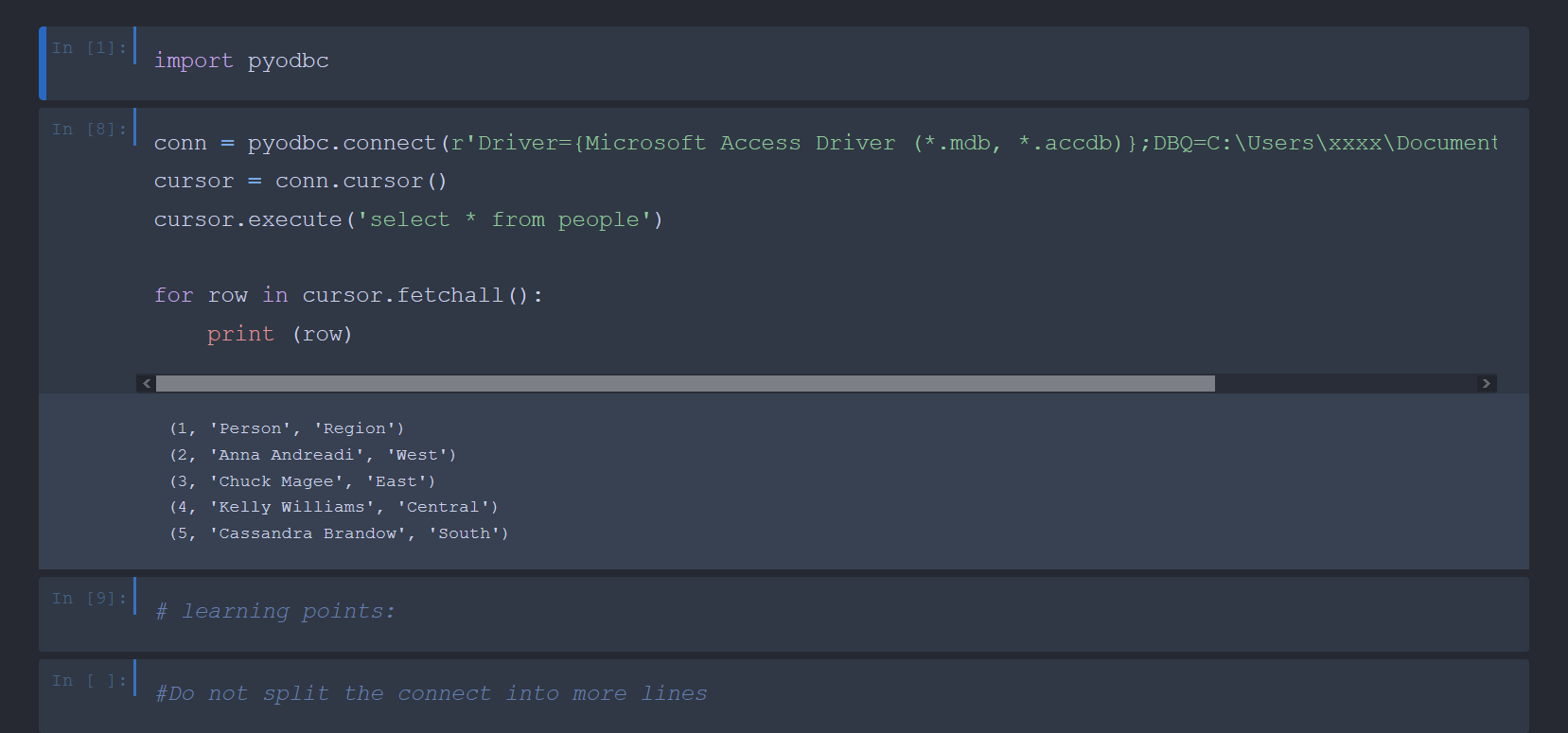
First you need a server to use management studio with..
Install sql server 2019 version
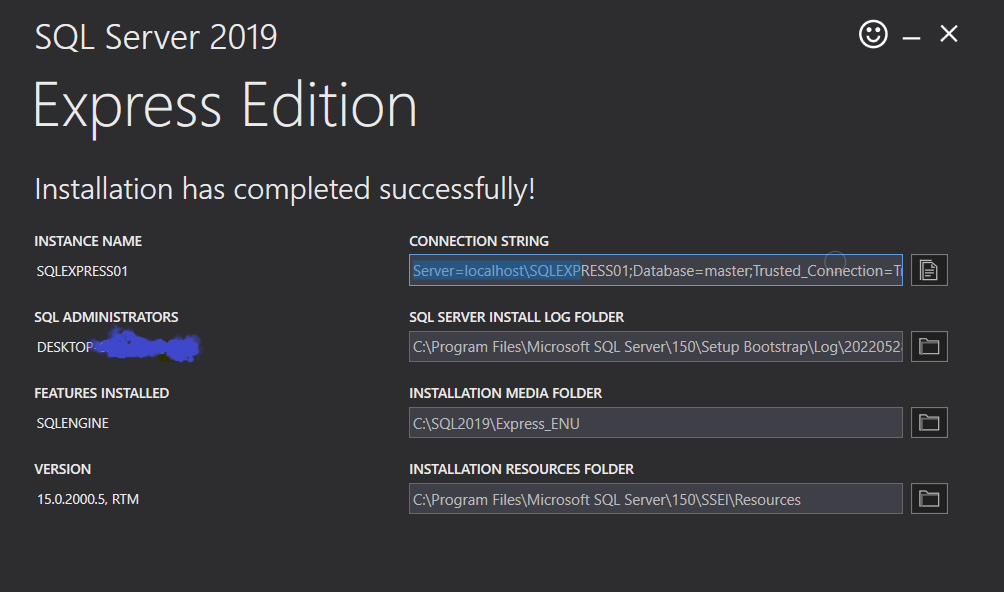
Now you can login with the first connection string
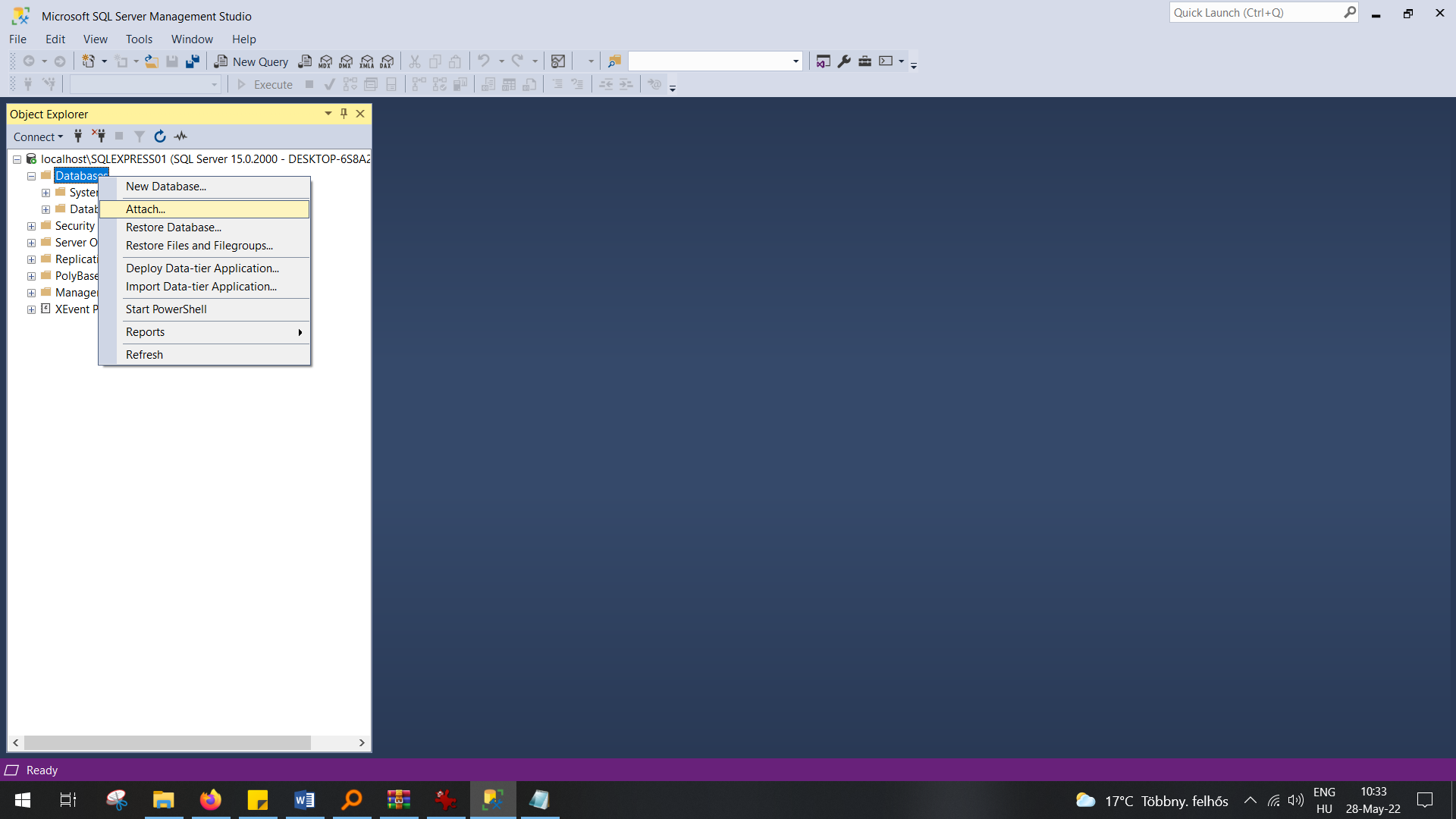
Copy the mdf file in that folder that this prompts up and select it.
And this is good to go.
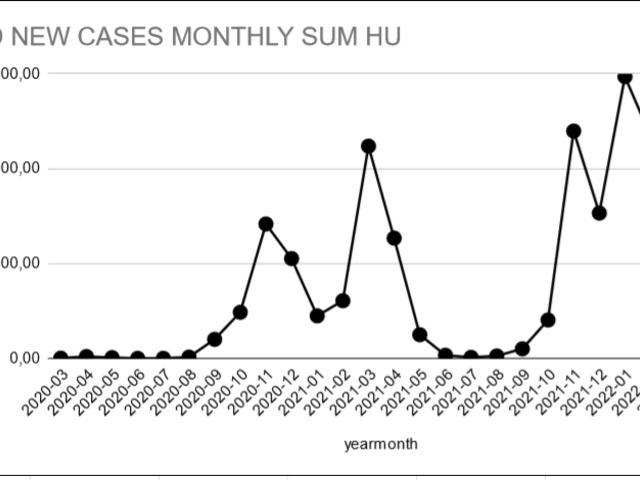
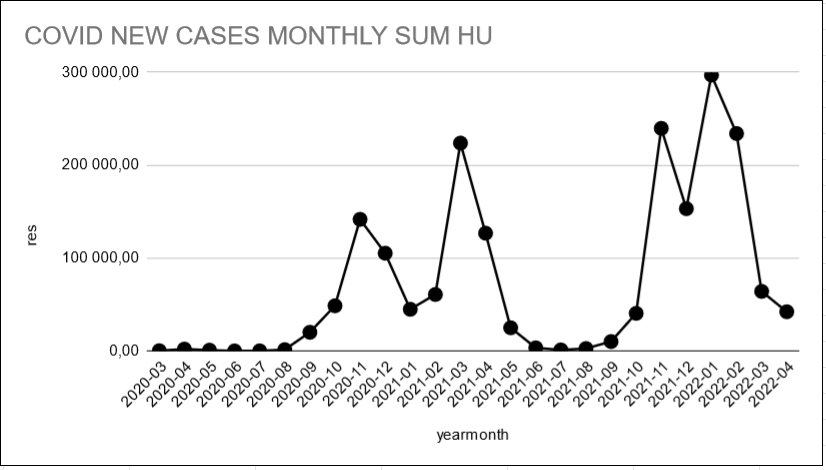
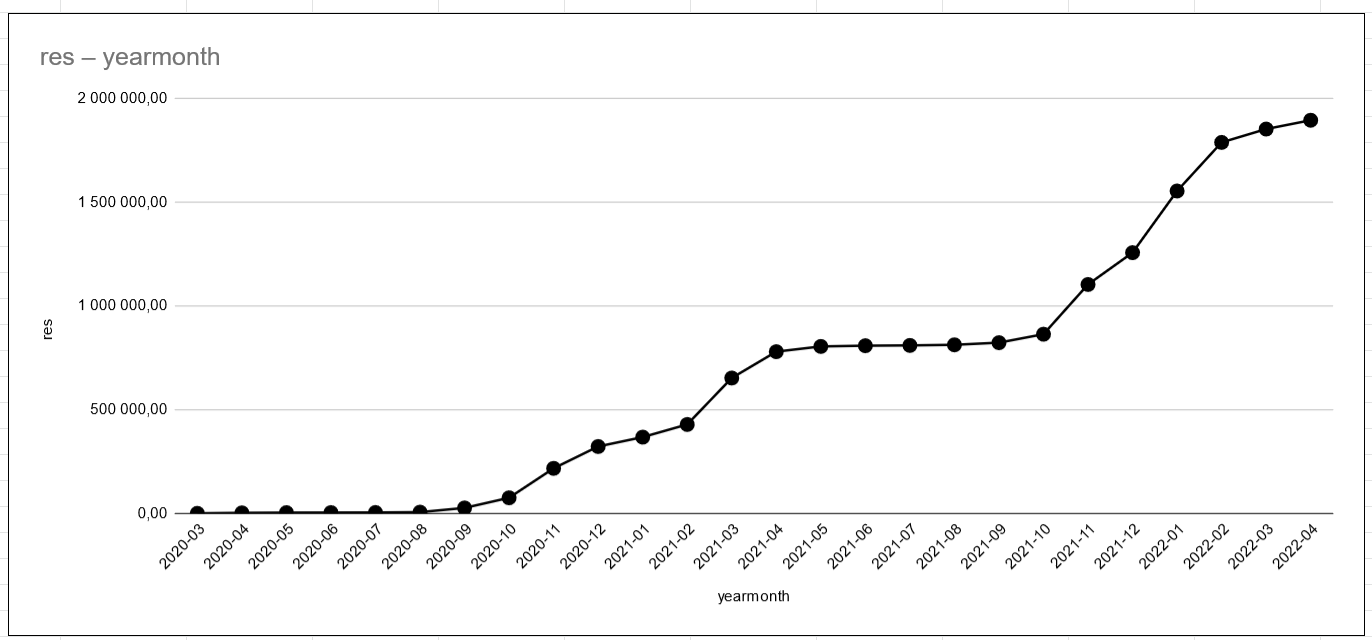
with data_21 as (
select * from (
select country_region, date as date_21, confirmed as confirmed_21, deaths as deaths_21
,LAG(confirmed, 1) OVER (PARTITION BY country_region ORDER BY date ASC) AS prev_day_21
,confirmed - LAG(confirmed, 1) OVER (PARTITION BY country_region ORDER BY date ASC) as new_cases_21
from `bigquery-public-data.covid19_jhu_csse.summary`
WHERE upper(country_region) = 'HUNGARY' AND date between '2020-01-01'
AND (select max(date) from `bigquery-public-data.covid19_jhu_csse.summary`)
)),
MONTHLY_NEW_CASES AS (
select
left(cast(date_21 as string),7) as yearmonth
,sum(new_cases_21) as res
from data_21
group by 1
order by 1 asc
),
TOTAL_CASES_MONTHS AS (
SELECT
left(cast(date_21 as string),7) as yearmonth
,MAX(confirmed_21) as res
from data_21
group by 1
order ...

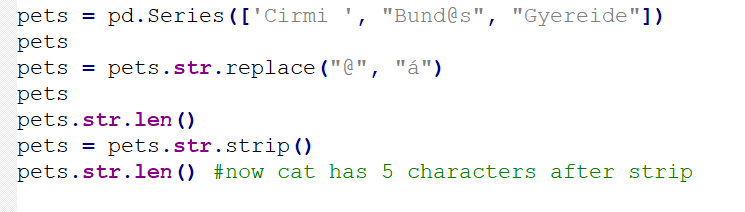
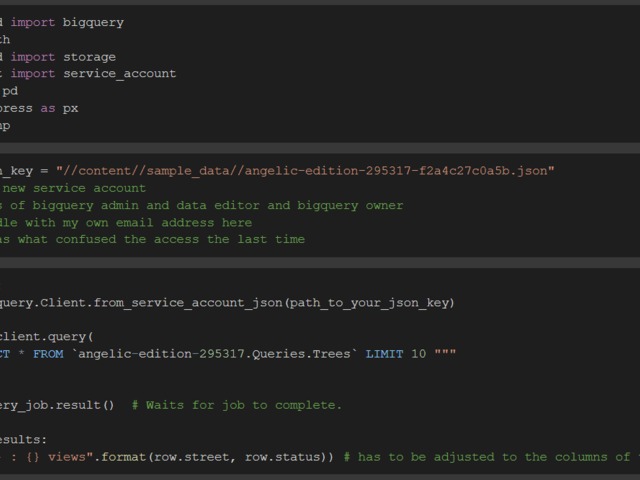
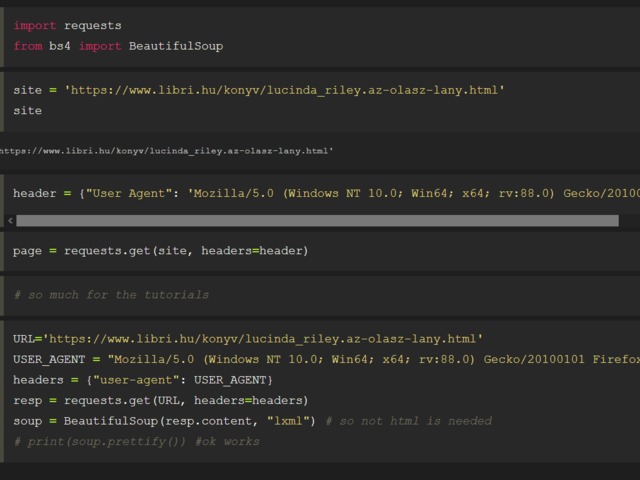
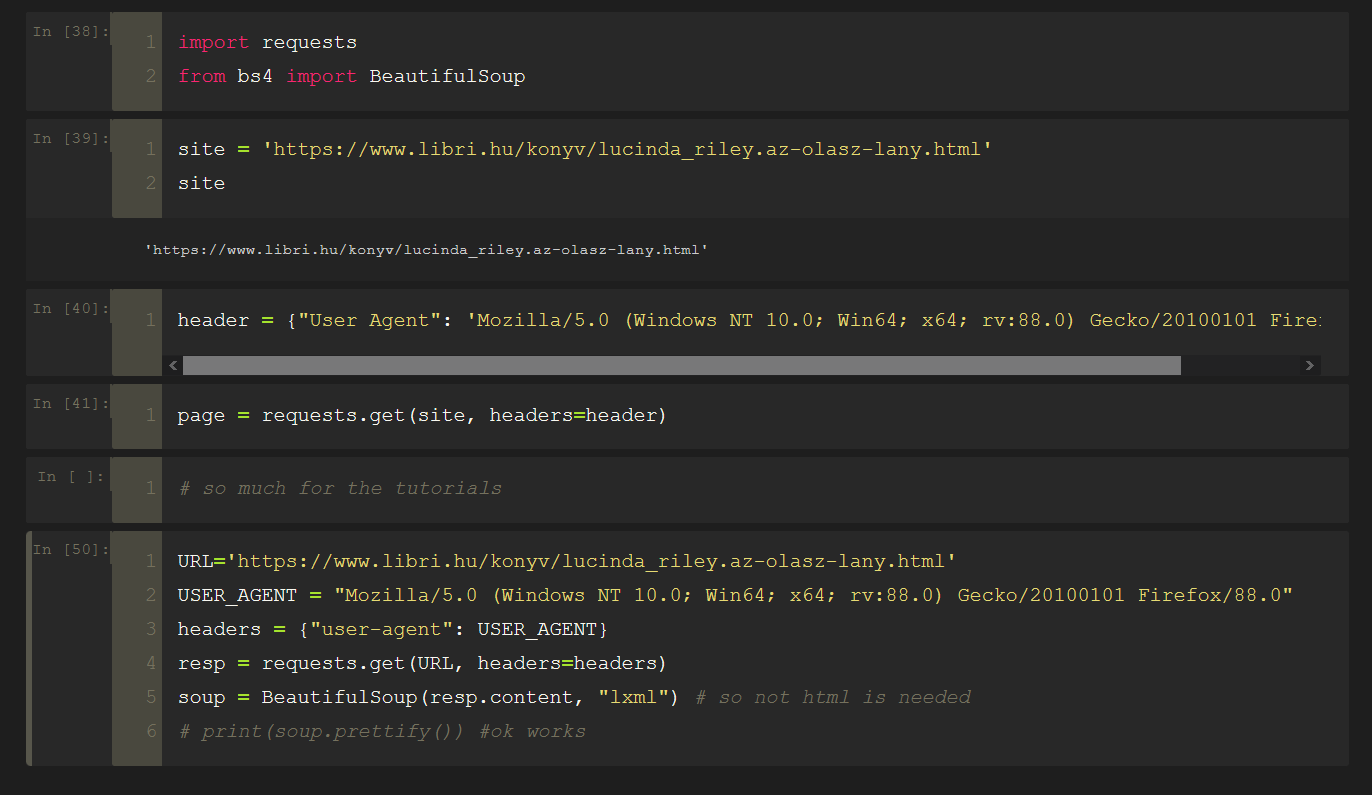
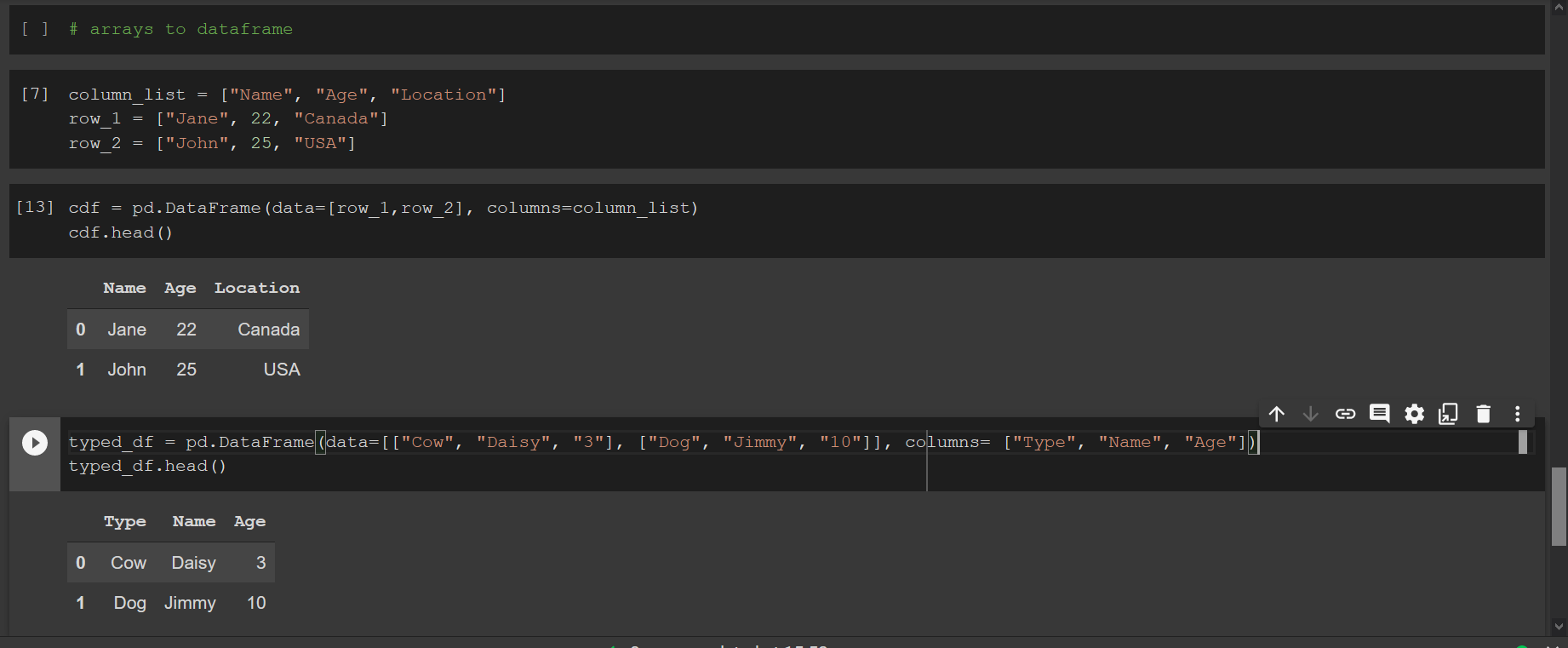
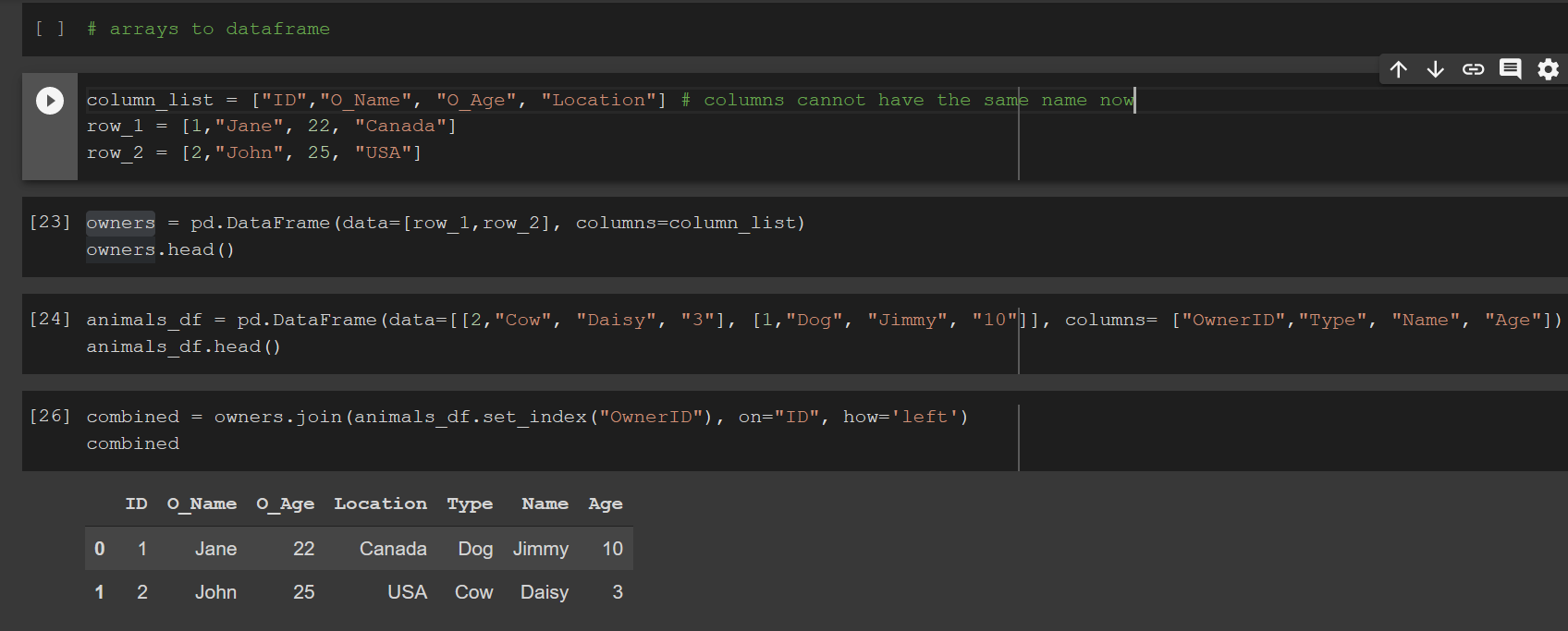
import pandas as pd
pets = pd.Series(['Cirmi ', "Bund@s", "Gyereide"])
pets
pets = pets.str.replace("@", "á")
pets
pets.str.len()
pets = pets.str.strip()
pets.str.len()
Website is: https://api.chucknorris.io/
Alright, let's see what we can do:
This is a web source, no authentication needed,so:
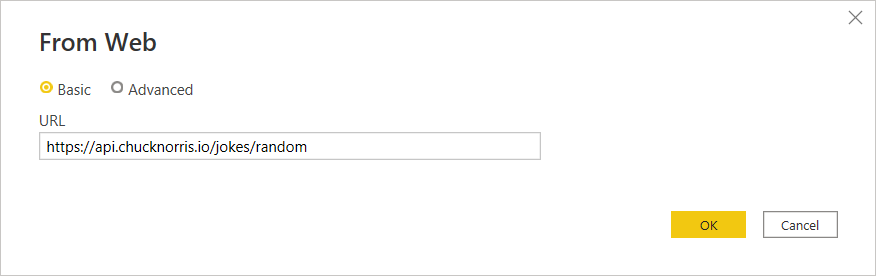
Just connect aaand..
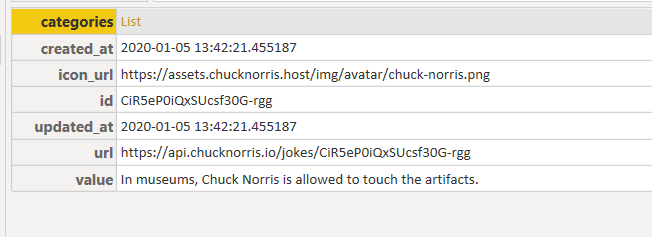
Convert to columns in table and keep only the value column which is the joke.
Now for the categories:

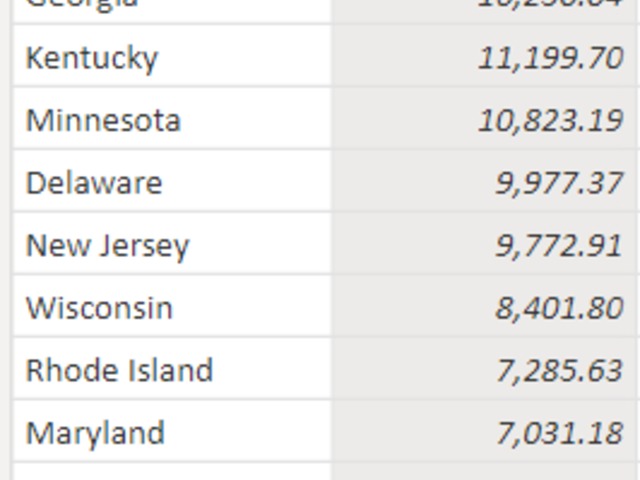
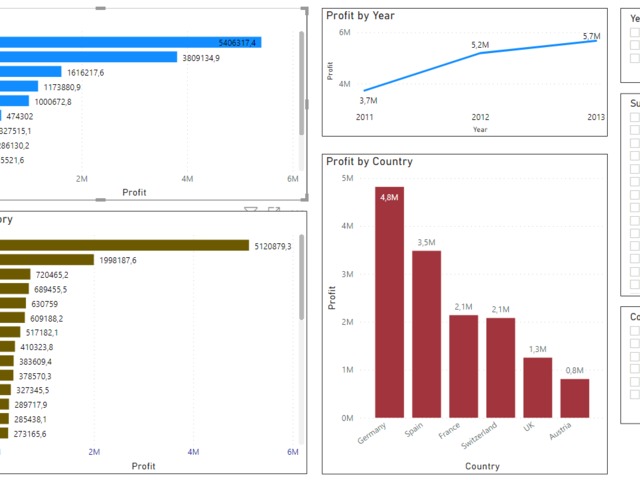
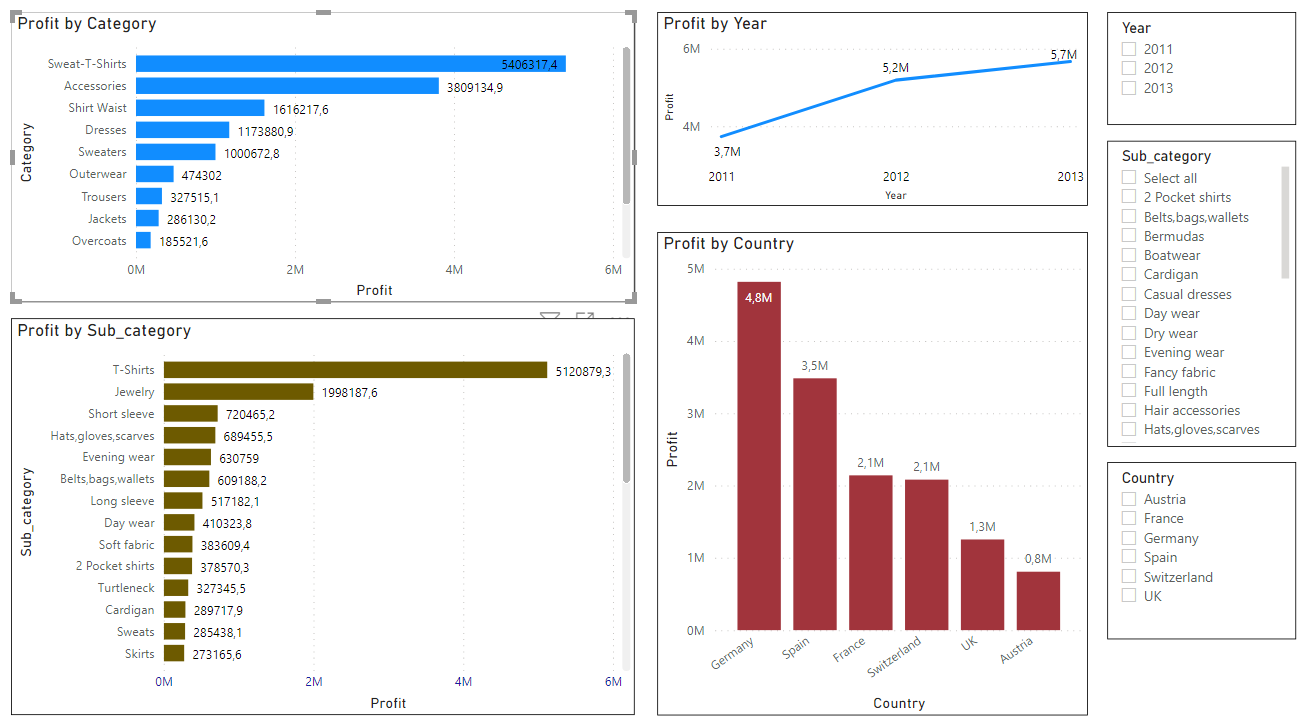
Let's make a summarized a table:
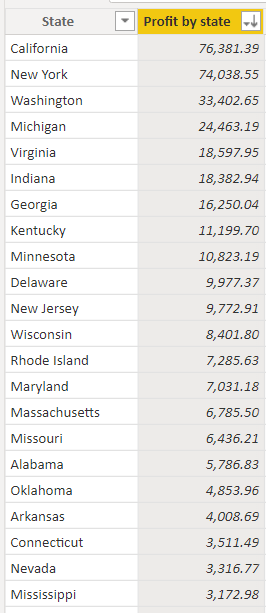
Now, we have a separate excel file with 2 values
Let's make our summarized table use this profit value.
with data_21 as (
select * from (
select country_region, date as date_21, confirmed as confirmed_21, deaths as deaths_21
,LAG(confirmed, 1) OVER (PARTITION BY country_region ORDER BY date ASC) AS prev_day_21
,confirmed - LAG(confirmed, 1) OVER (PARTITION BY country_region ORDER BY date ASC) as new_cases_21
from `bigquery-public-data.covid19_jhu_csse.summary`
WHERE upper(country_region) = 'HUNGARY' AND date between '2022-01-01'
AND (select max(date) from `bigquery-public-data.covid19_jhu_csse.summary`)
))
select
*
from data_21
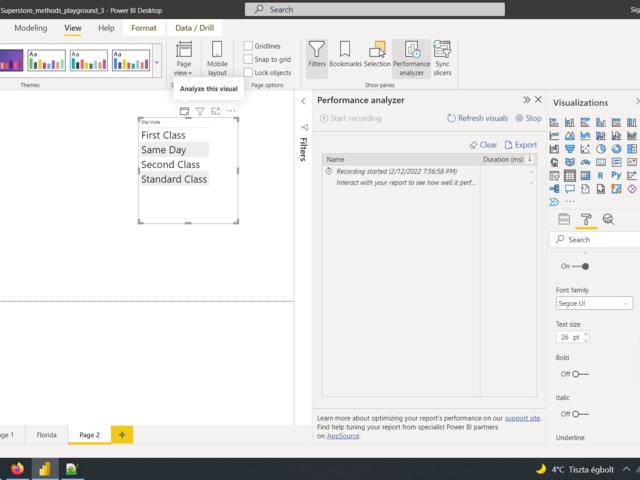
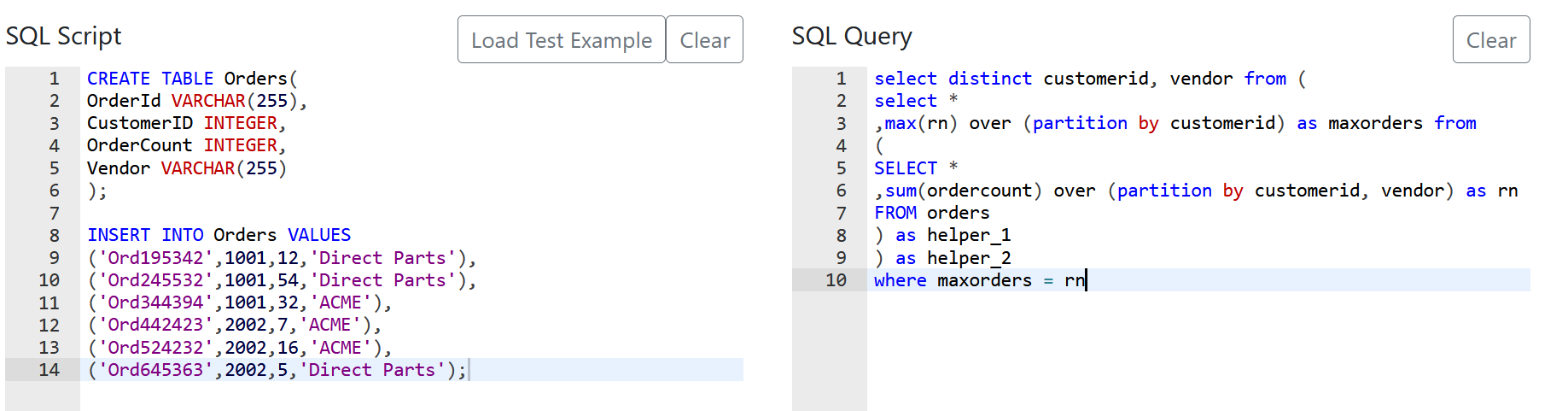
Step 1: Turn on performance analyzer and select the analyze this visual option.
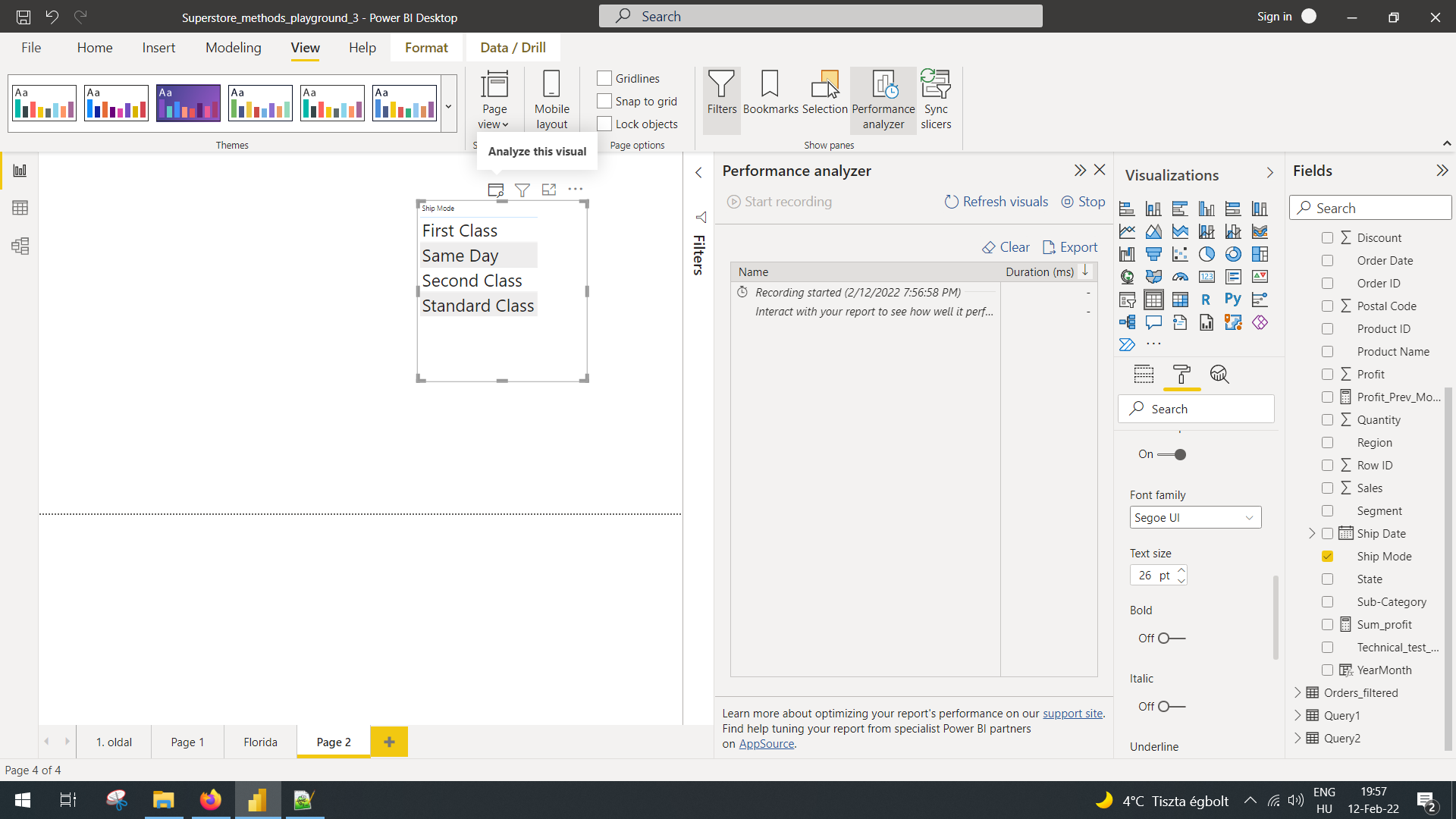
After that, performance analyzer adds some lines:
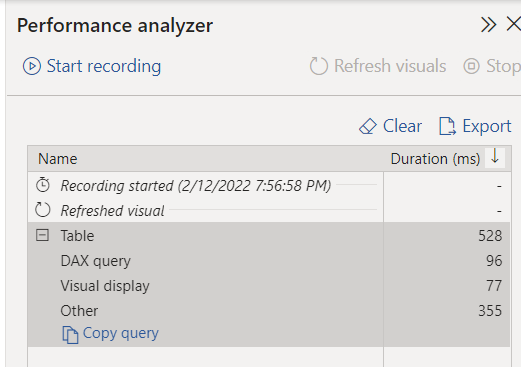
Click copy query and paste anywhere:
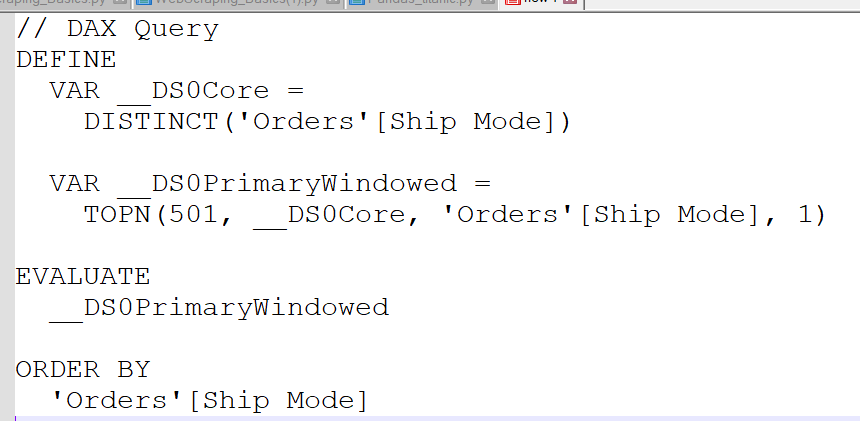
And you see, there is the distinct value on it. Let's add something unique, like the orderID:

These are auto-generated in the background..And we reached the end of this idea.
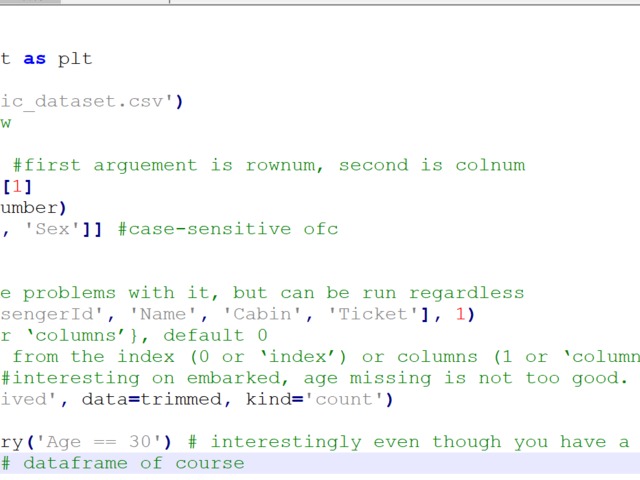
So the basics, nothing hard here:
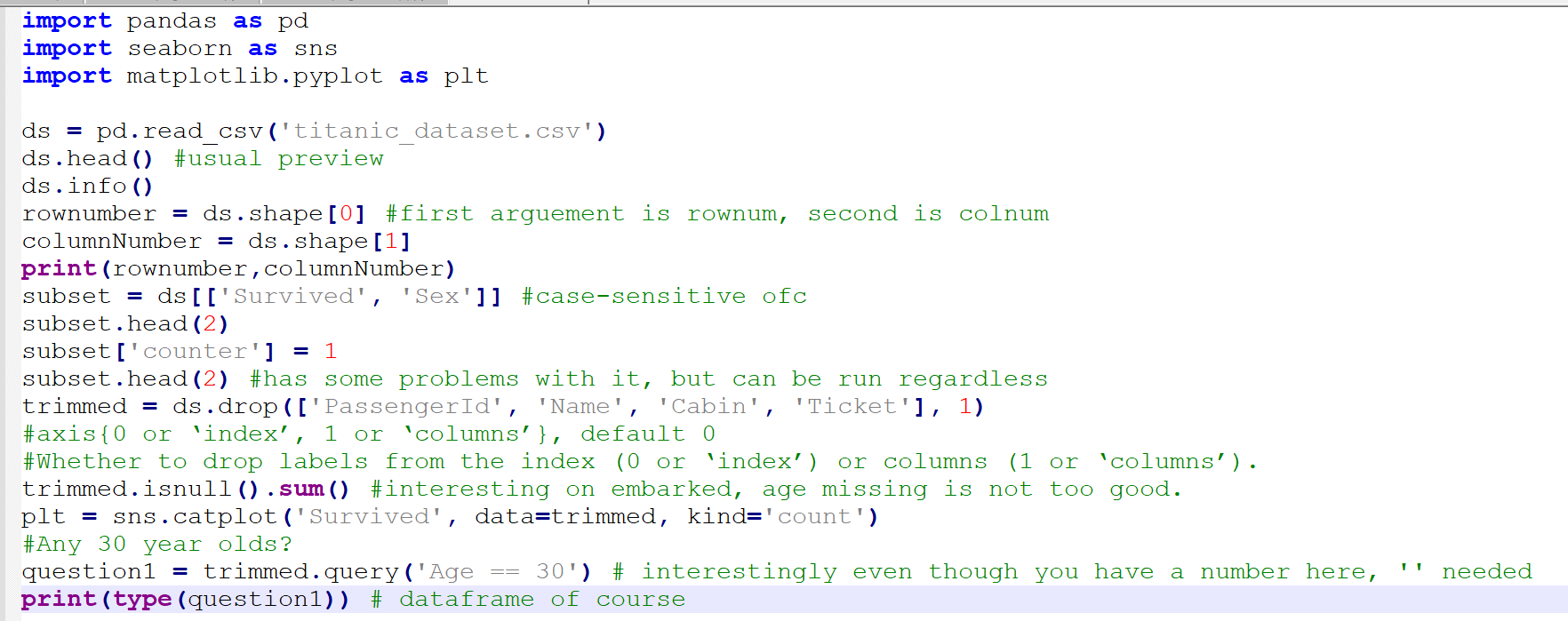
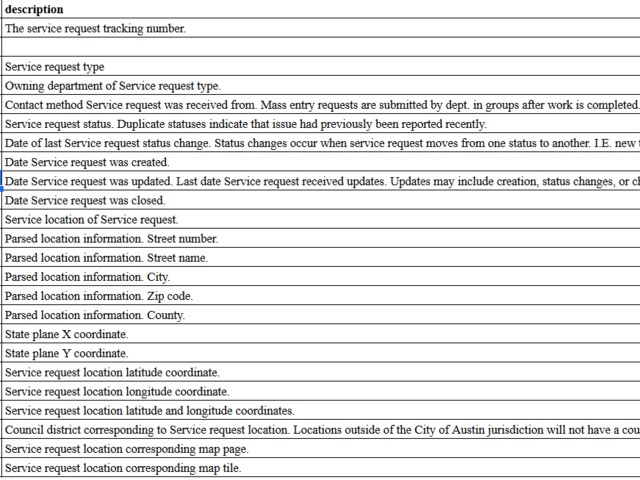
Let's see the metadata first
SELECT column_name, data_type, description
FROM
`bigquery-public-data`
.austin_311.
INFORMATION_SCHEMA.COLUMN_FIELD_PATHS
WHERE
table_name="311_service_requests"
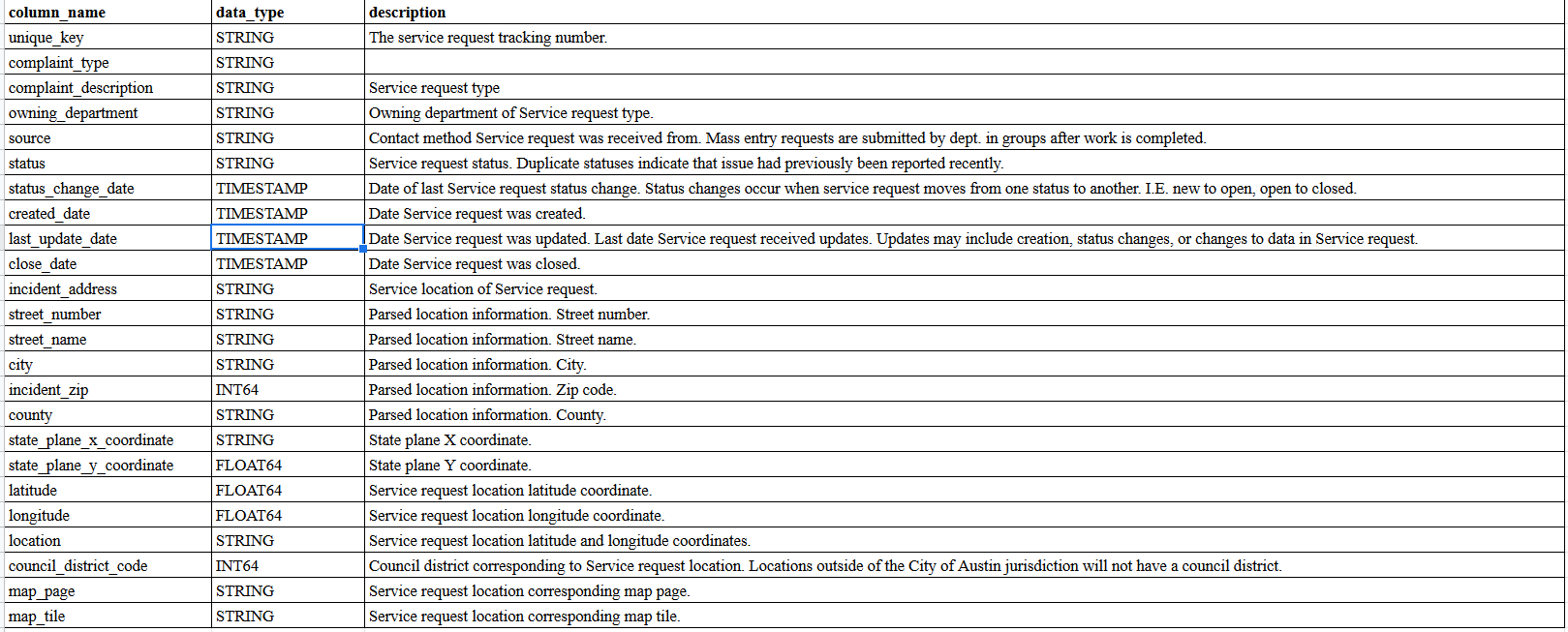
Let's see how many years this database encompasses:
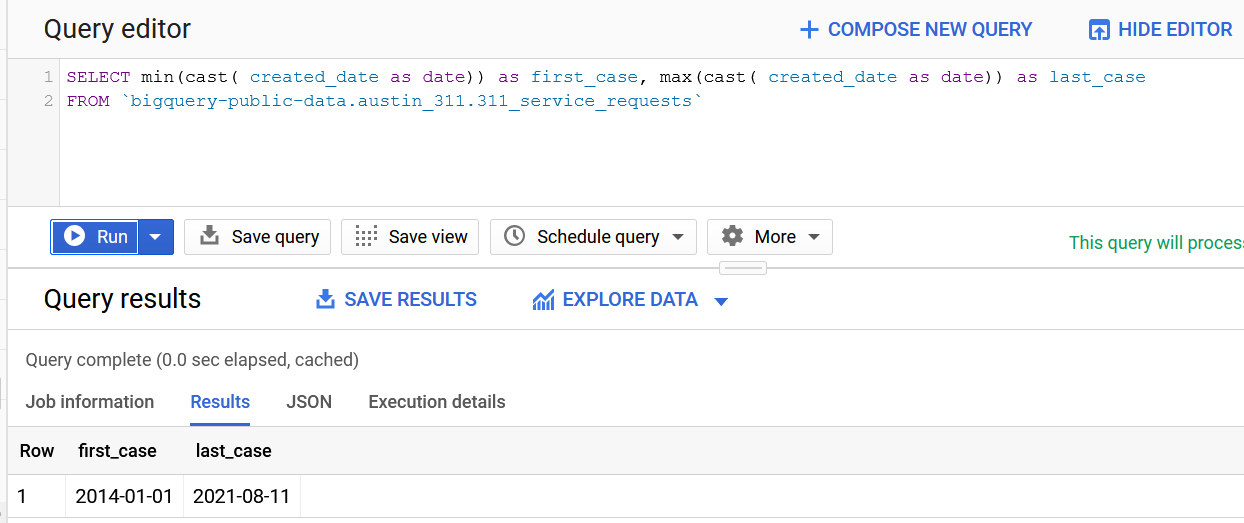
Looks like a lot of time.
As the dataset seems to have changed or disappeared from the public database, this is the end of this analysis.

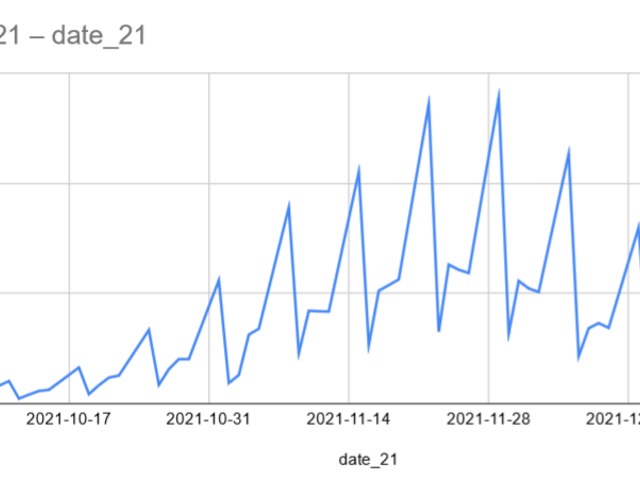
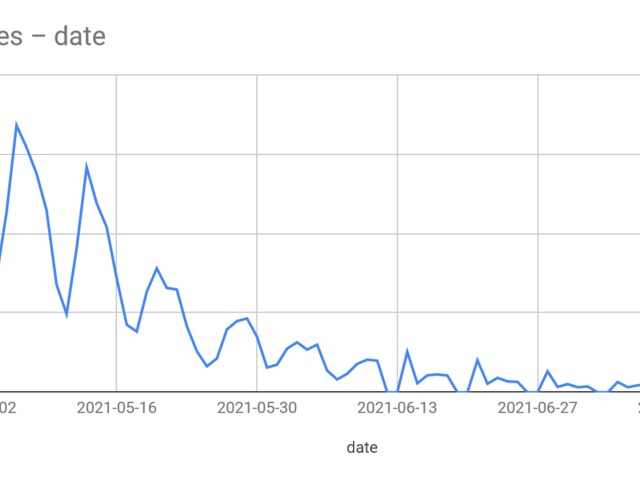
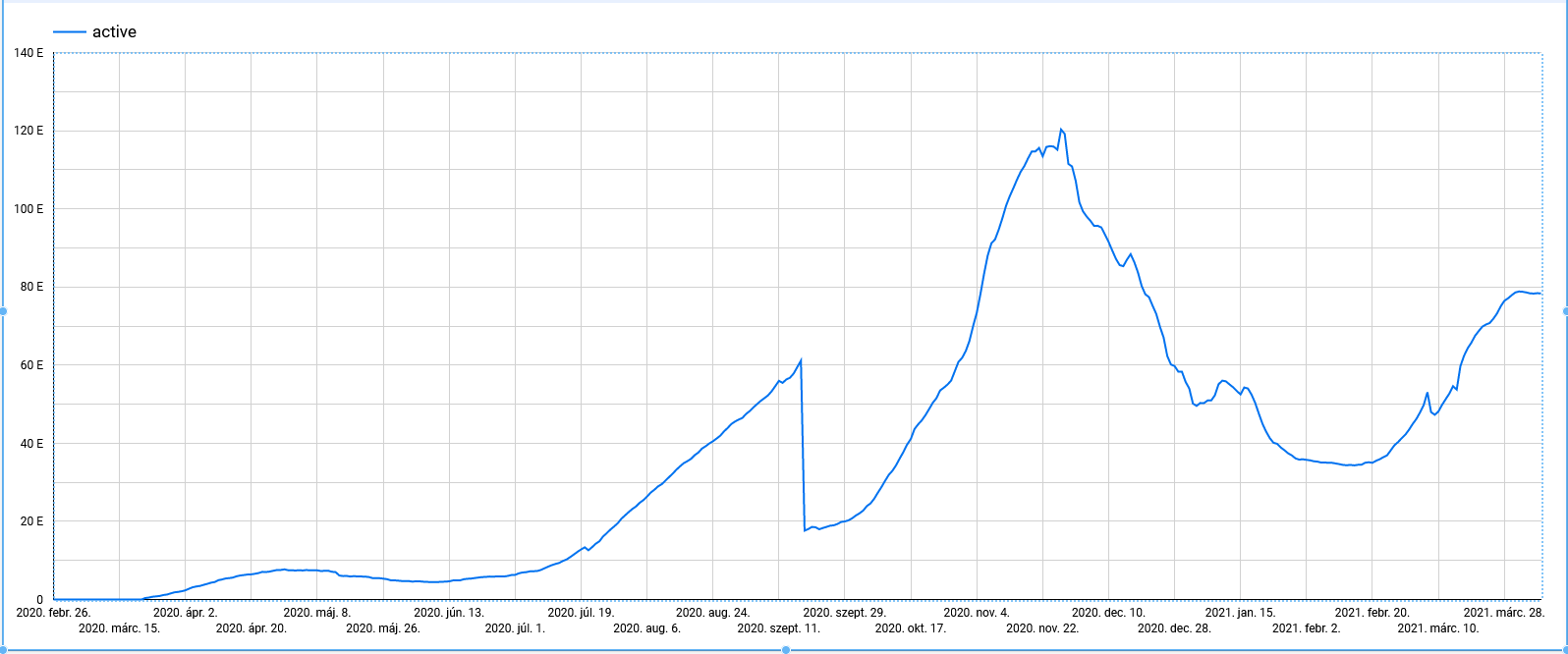
Same as always, the weekends get added to the next Monday's results.
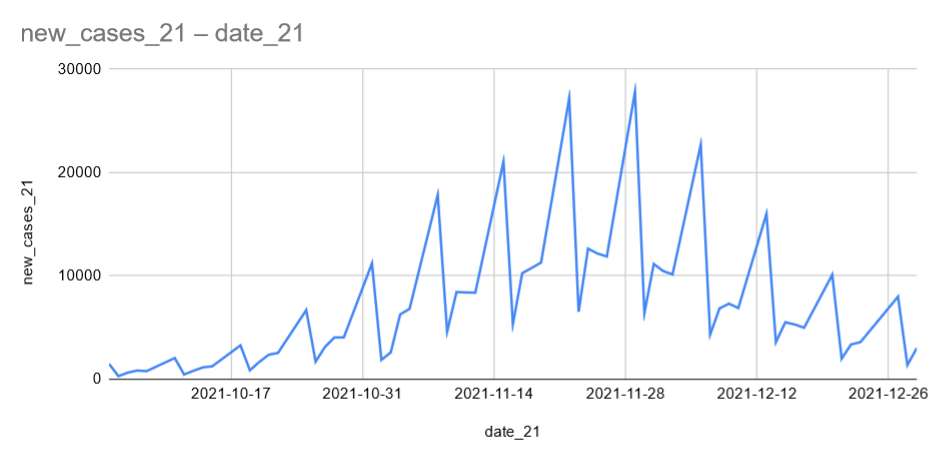
This causes spikes, however we can see that these spikes are going down too fortunately.
Let's remove these spike days.
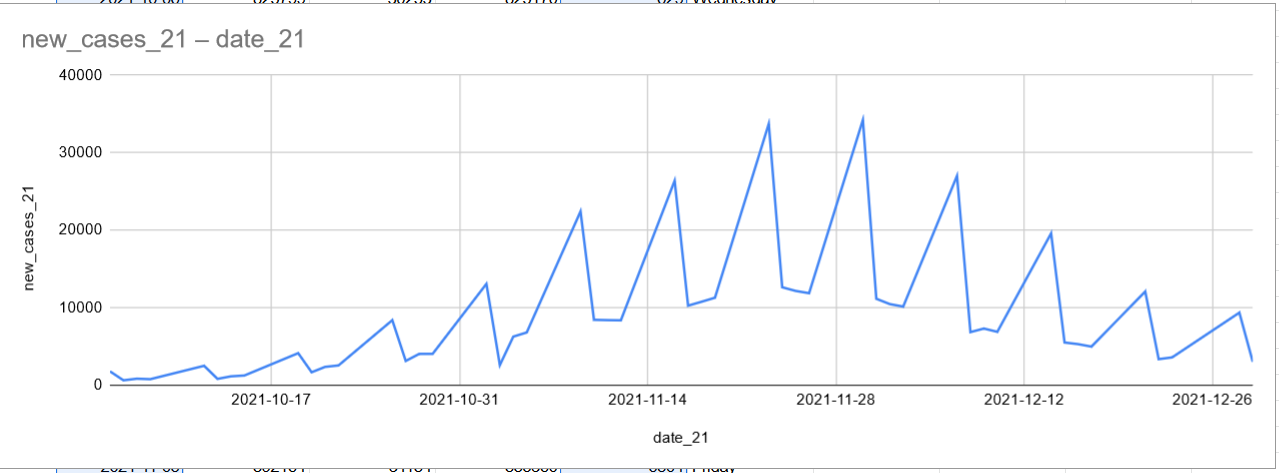
Doesn't really change. Looks like they test more on the beginning of the week and by the end, it drops.
with data_21 as (
select * from (
select country_region, date as date_21, confirmed as confirmed_21, deaths as deaths_21
,LAG(confirmed, 1) OVER (PARTITION BY country_region ORDER BY date ASC) AS prev_day_21
,confirmed - LAG(confirmed, 1) OVER (PARTITION BY country_region ORDER BY date ASC) as new_cases_21
from `bigquery-public-data.covid19_jhu_csse.summary`
WHERE upper(country_region) = 'HUNGARY' AND date between '2021-10-01'
AND (select max(date) from ...
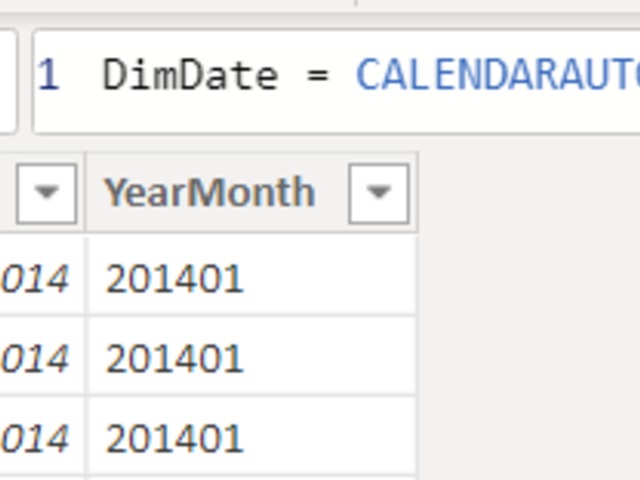
For this to work, we need a Calendar table, or in another name a date table.
Why isn't one of our existing columns in our data good? Because:
-we need a table which contains all dates without skipping non-business days, holidays etc so all 365 days in a year.
-all the dates must occur only once (while in our tables multiple transactions can happen in a day or even none at all)
So let's create this table, the easiest was is through DAX calendarauto function. This will cover our dateframe which is existing in our dataset.
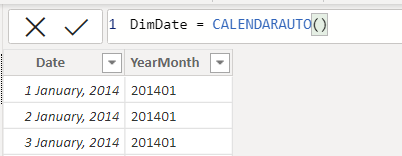
The main date column has to be set in DATE FORMAT. NOT DATETIME. Make sure you have in DATE format through any means necessary.
When this is done, you need to create the relationship between this, and your tables. This is done in a relatively easy way as ...
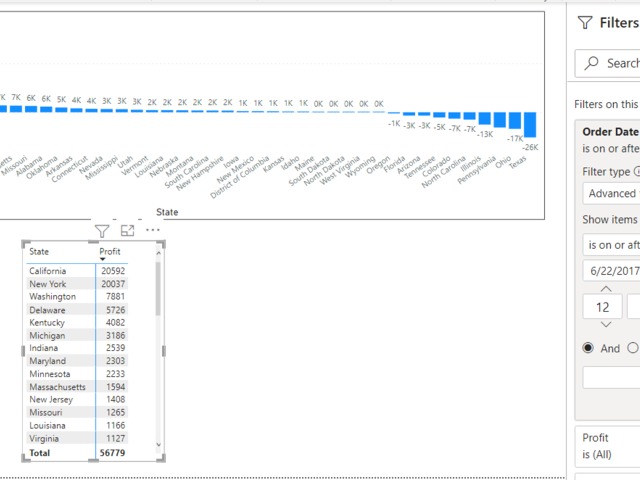
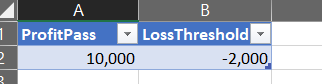
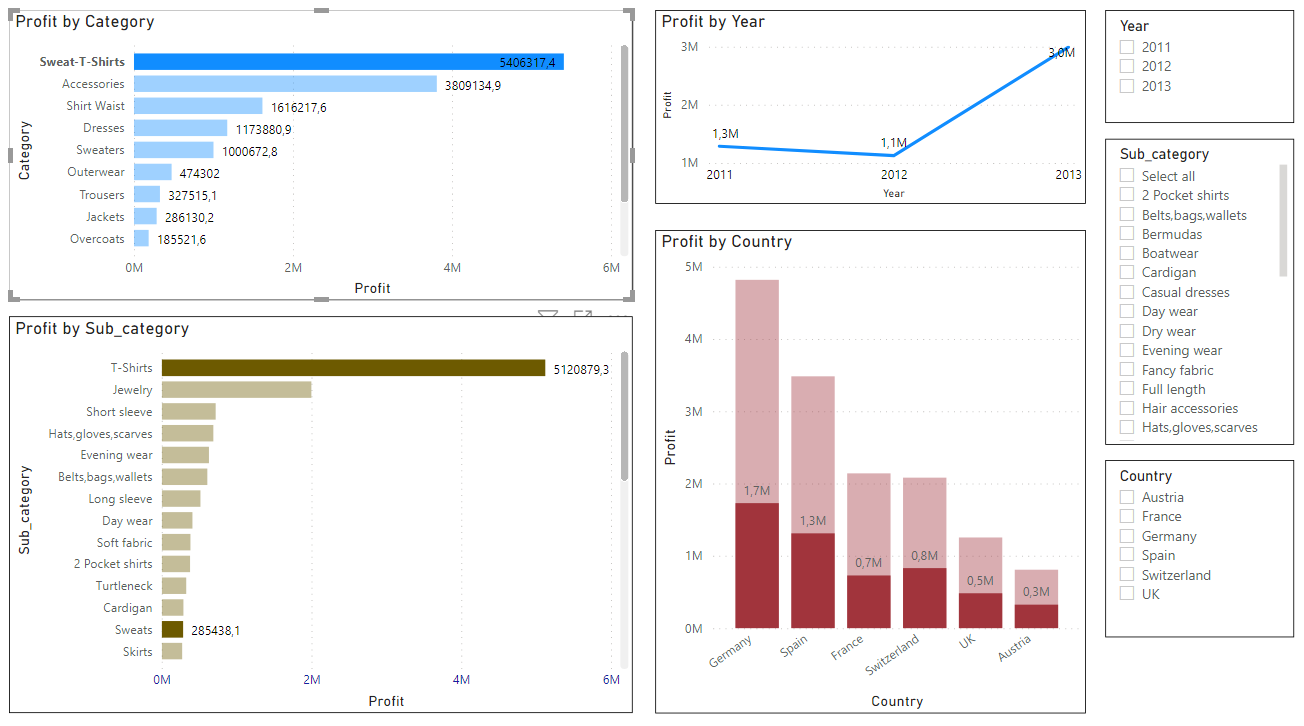
Filter Sum of profit AFTER A SPECIFIC DATE with only GUI options:
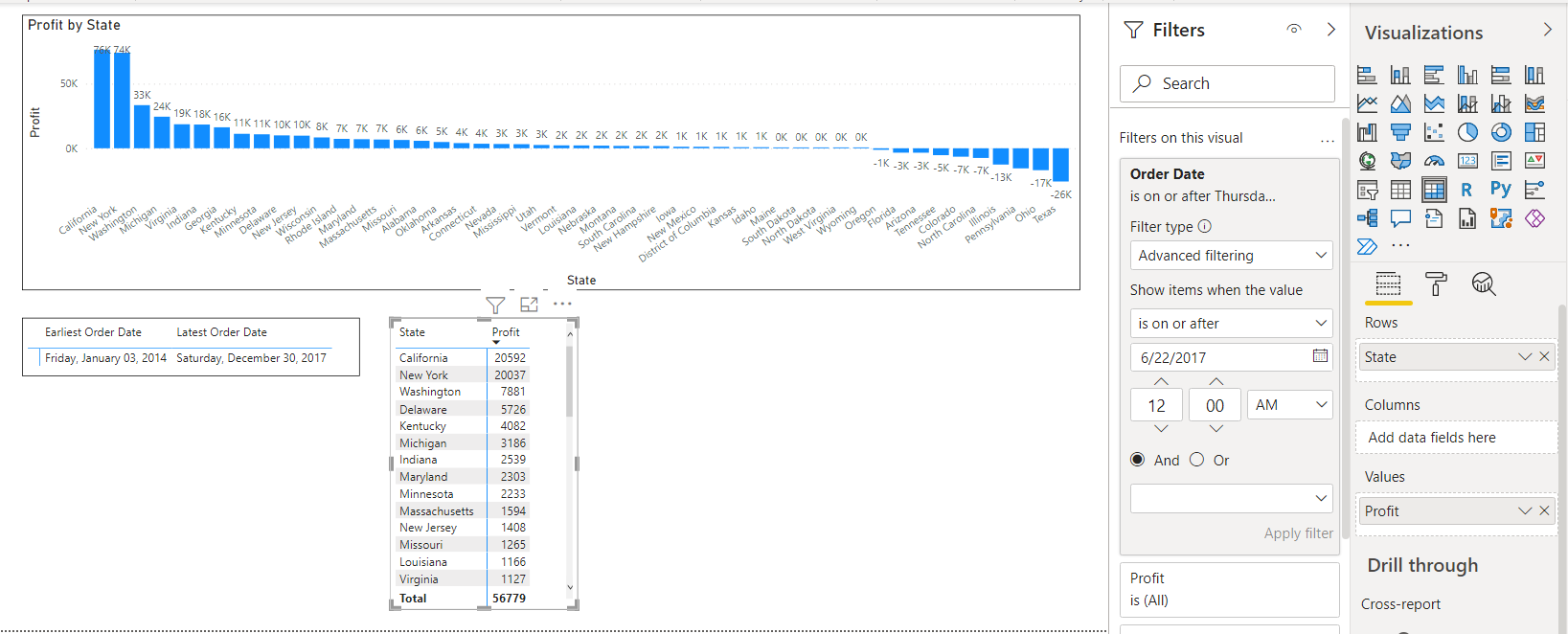
Profit is set to whole number just for readability.
--------------------------------------------------
Filter with parameter and DAX formulas:
1. Add paramter
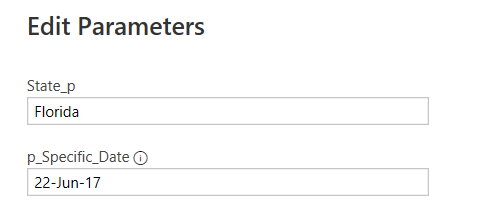
2. Convert parameter to query for referencing it in the formula: 
3. Create DAX formula

4. Check if results are the same
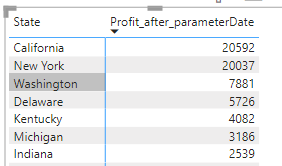
Excel check returns the same,so it works.
----------------------------------------------------------------------
Use filters to select specific data:

Some other touches:
Replace_from_other_column = Table.ReplaceValue(#"Changed Type",null, each [Profit] , Replacer.ReplaceValue,{"Technical_test_col"})
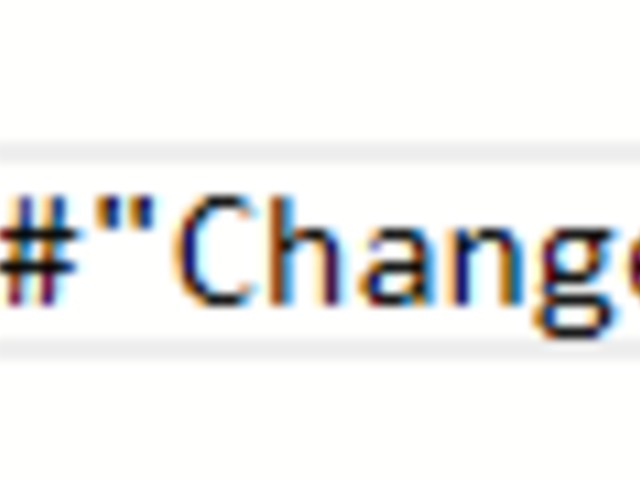
Filtering rows: 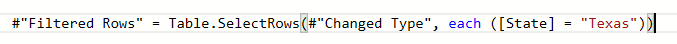
Grouping:
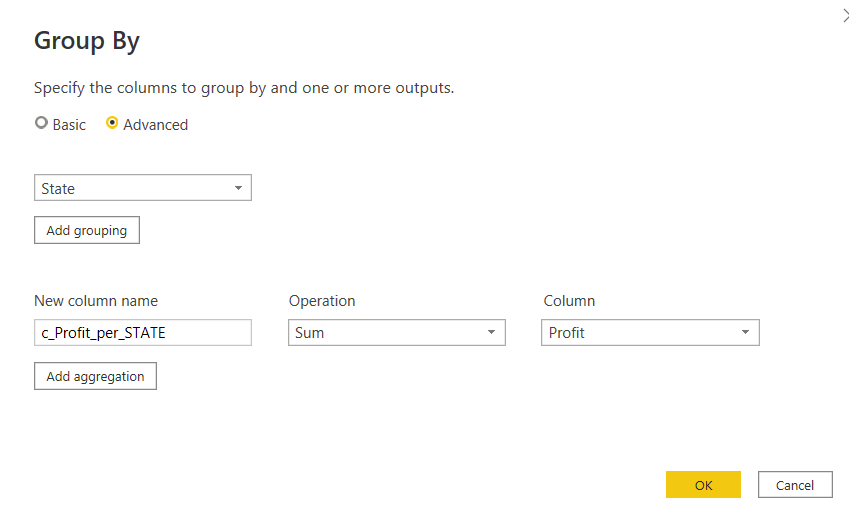
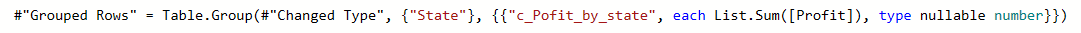
#"Grouped Rows" = Table.Group(#"Changed Type", {"State"}, {{"c_Pofit_by_state", each List.Sum([Profit]), type nullable number}})
Note: this is pretty slow when doing it from the editor, gui pivot is much faster.
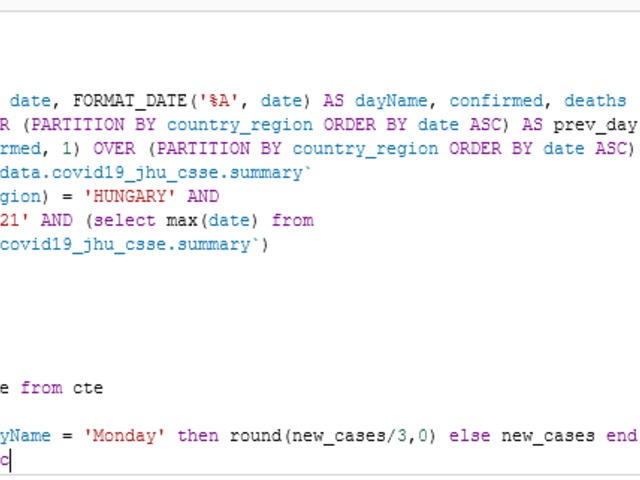
What is going on?
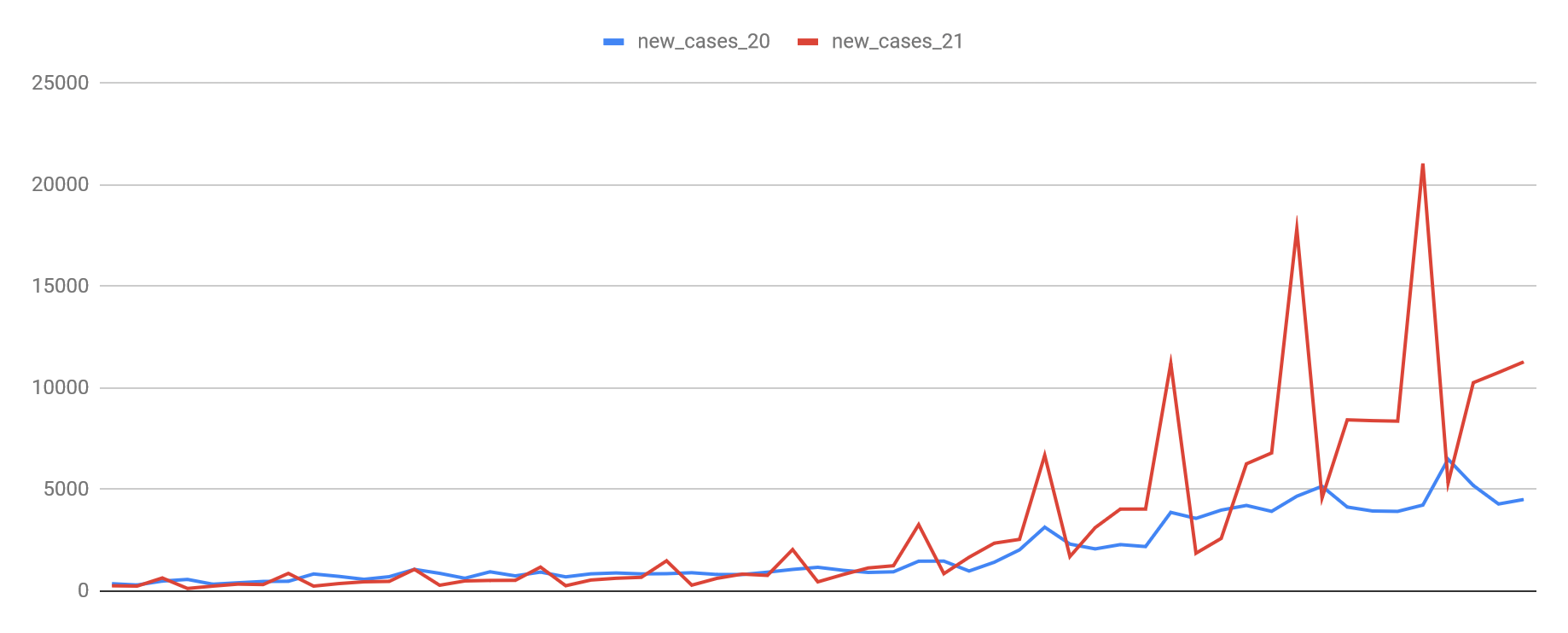
Table:
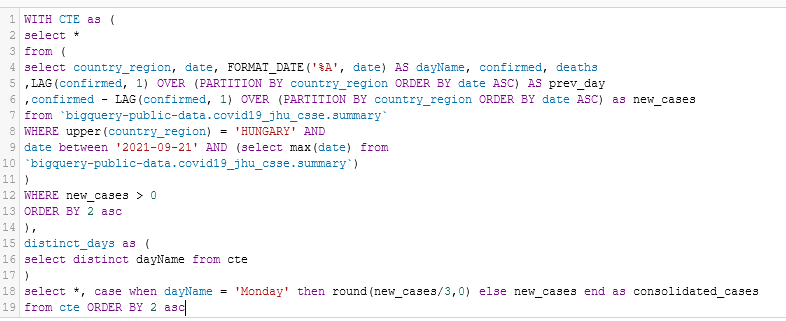
All days with abnormally high case counts were usually Mondays. No Saturday or Sunday in the report.
This means Mondays contain 3 days worth of new cases.
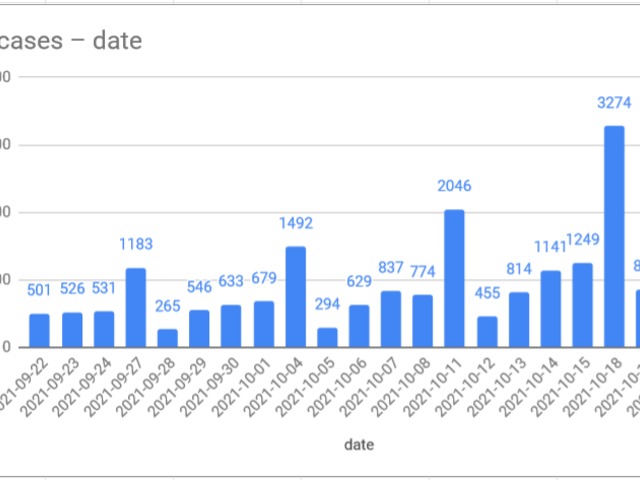
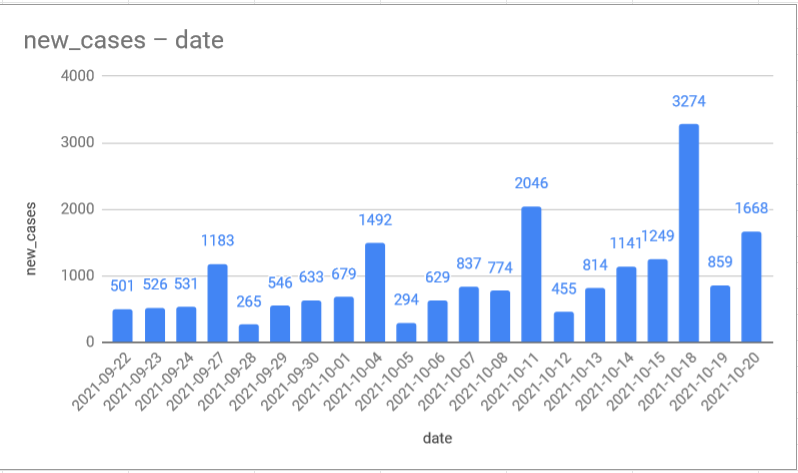
select *
from (
select country_region, date, confirmed, deaths
,LAG(confirmed, 1) OVER (PARTITION BY country_region ORDER BY date ASC) AS prev_day
,confirmed - LAG(confirmed, 1) OVER (PARTITION BY country_region ORDER BY date ASC) as new_cases
from `bigquery-public-data.covid19_jhu_csse.summary`
WHERE upper(country_region) = 'HUNGARY' AND
date between '2021-09-21' AND (select max(date) from
`bigquery-public-data.covid19_jhu_csse.summary`)
)
WHERE new_cases > 0
ORDER BY 2 asc
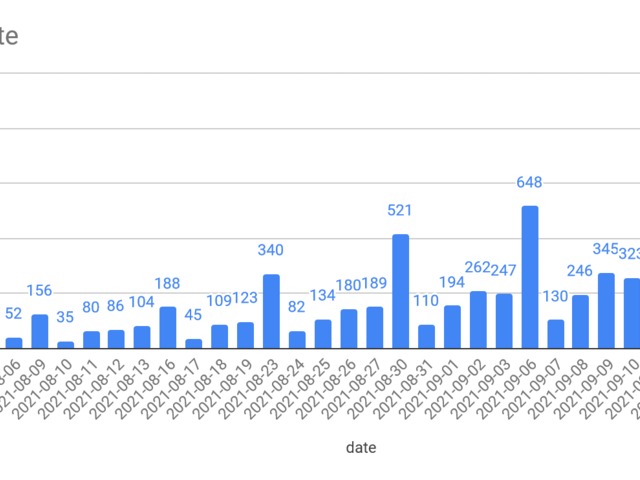
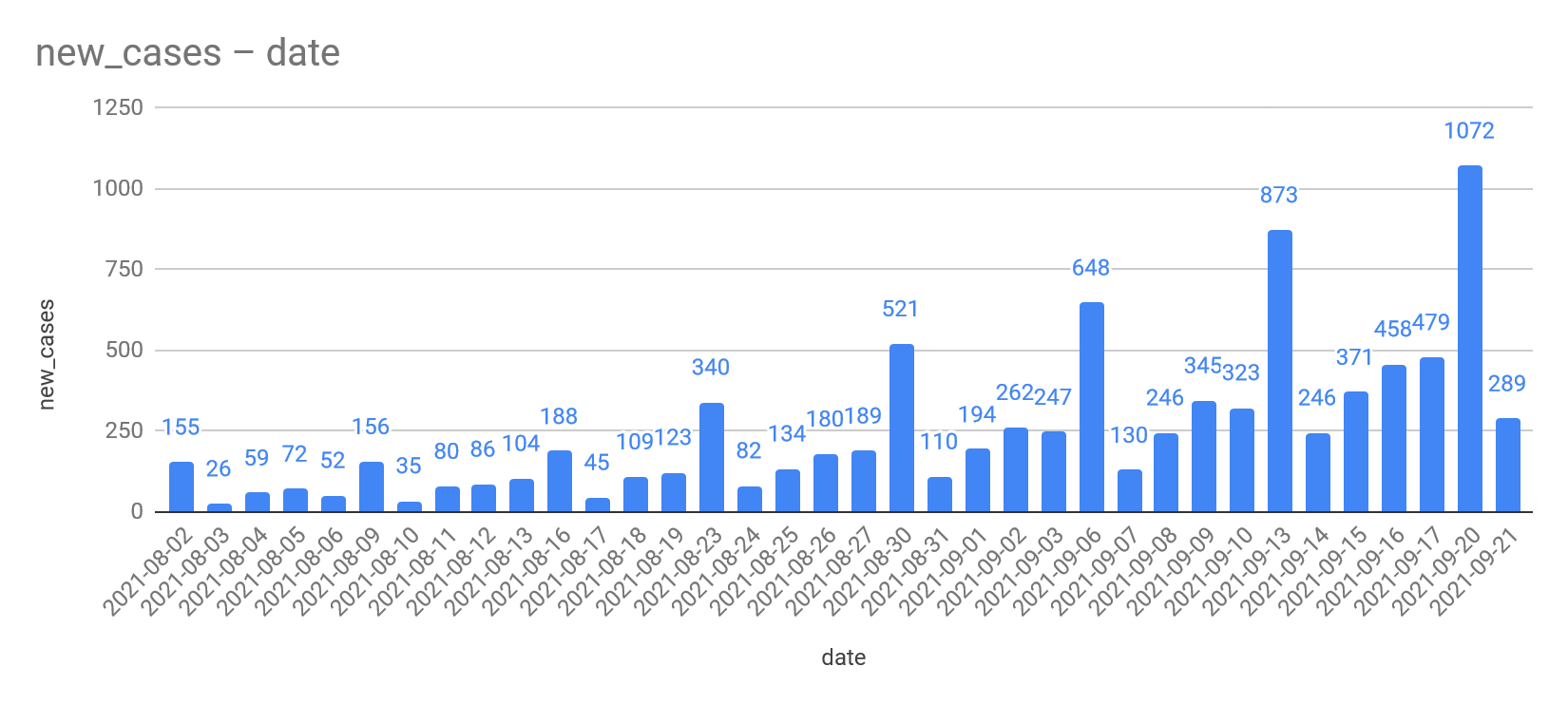
select *
from (
select country_region, date, confirmed, deaths, recovered, active
,LAG(confirmed, 1) OVER (PARTITION BY country_region ORDER BY date ASC) AS prev_day
,confirmed - LAG(confirmed, 1) OVER (PARTITION BY country_region ORDER BY date ASC) as new_cases
from `bigquery-public-data.covid19_jhu_csse.summary`
WHERE upper(country_region) = 'HUNGARY' AND
date between '2021-07-30' AND (select max(date) from
`bigquery-public-data.covid19_jhu_csse.summary`)
)
WHERE new_cases >0
ORDER BY 2 asc
select *
from (
select country_region, date, confirmed, deaths, recovered, active
,LAG(confirmed, 1) OVER (PARTITION BY country_region ORDER BY date ASC) AS prev_day
,confirmed - LAG(confirmed, 1) OVER (PARTITION BY country_region ORDER BY date ASC) as new_cases
from `bigquery-public-data.covid19_jhu_csse.summary`
WHERE upper(country_region) = 'HUNGARY' AND
date between '2021-07-30' AND (select max(date) from
`bigquery-public-data.covid19_jhu_csse.summary`)
)
WHERE new_cases >0
ORDER BY 2 asc


More testing maybe? From single digits to quadruple digits in 2 months :(
select country_region, date, confirmed, deaths, recovered, active
,LAG(confirmed, 1) OVER (PARTITION BY country_region ORDER BY date ASC) AS prev_day
,confirmed - LAG(confirmed, 1) OVER (PARTITION BY country_region ORDER BY date ASC) as new_cases
from `bigquery-public-data.covid19_jhu_csse.summary`
WHERE upper(country_region) = 'ISRAEL' AND
date between '2021-06-01' AND (select max(date) from
`bigquery-public-data.covid19_jhu_csse.summary`)
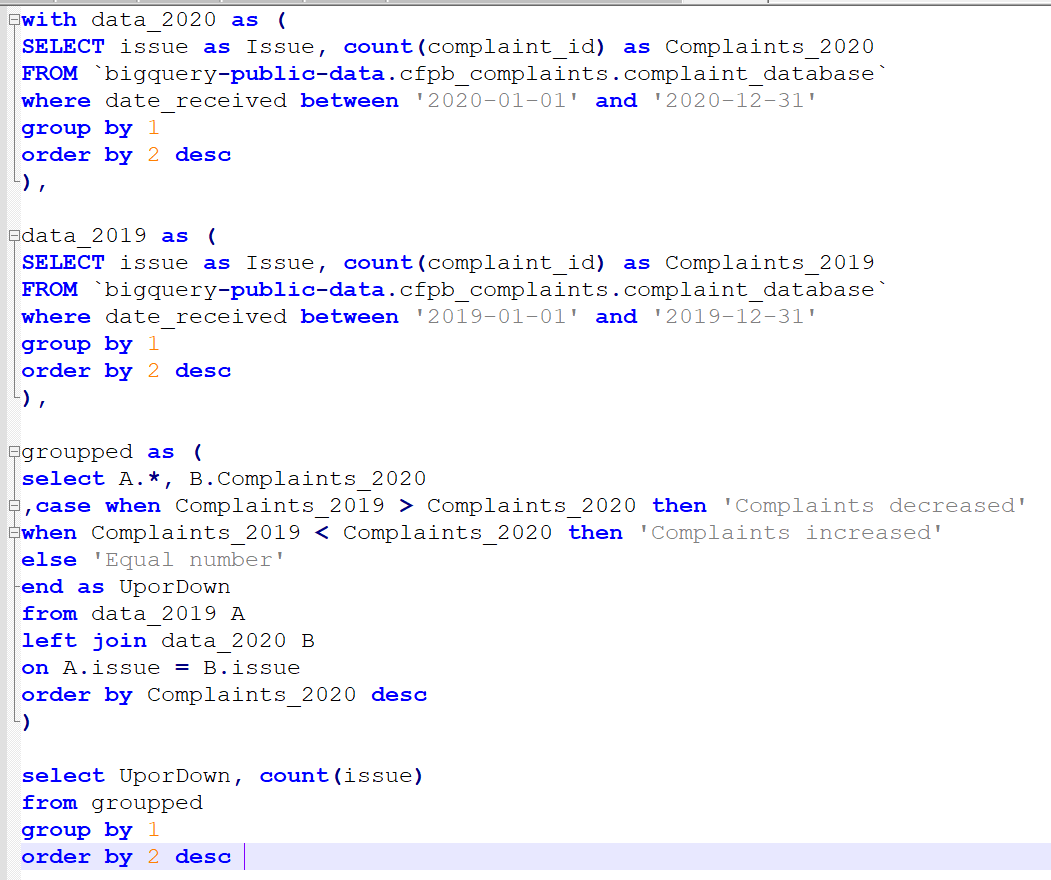
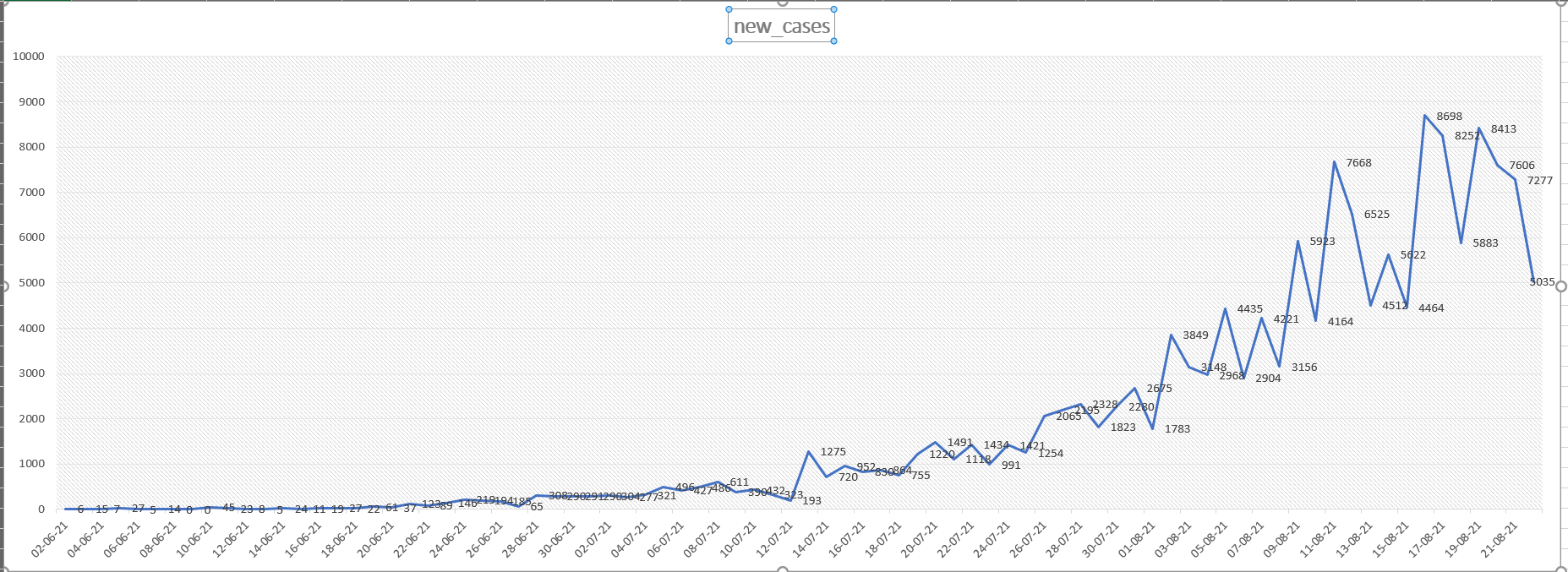
But why would you do this convoluted solution?
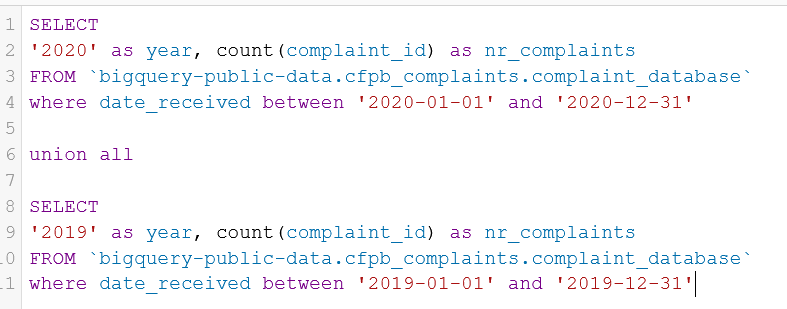
Which companies are most involved?
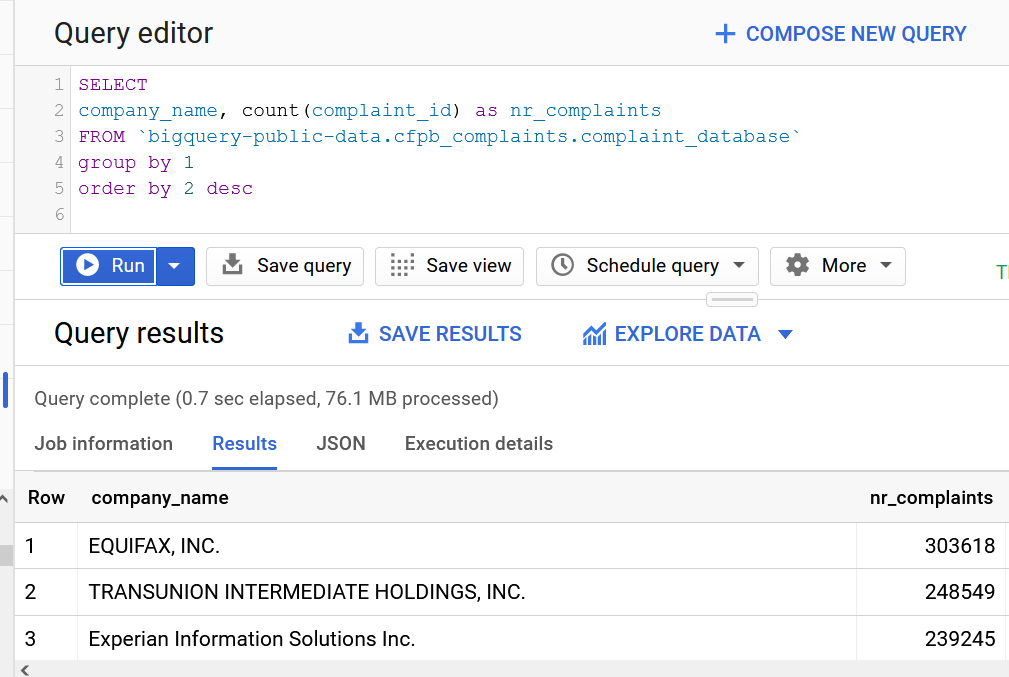
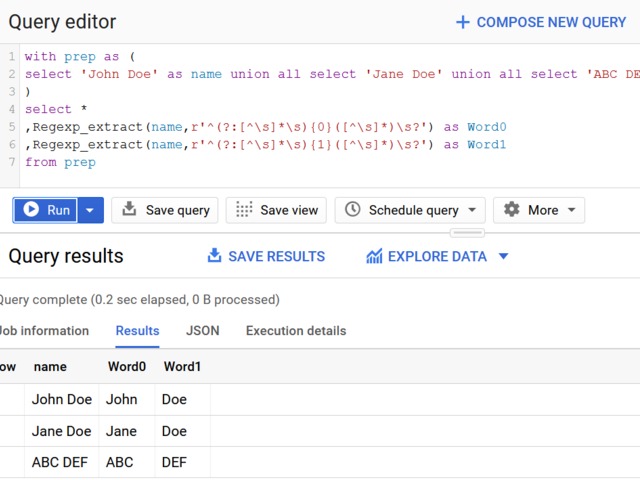
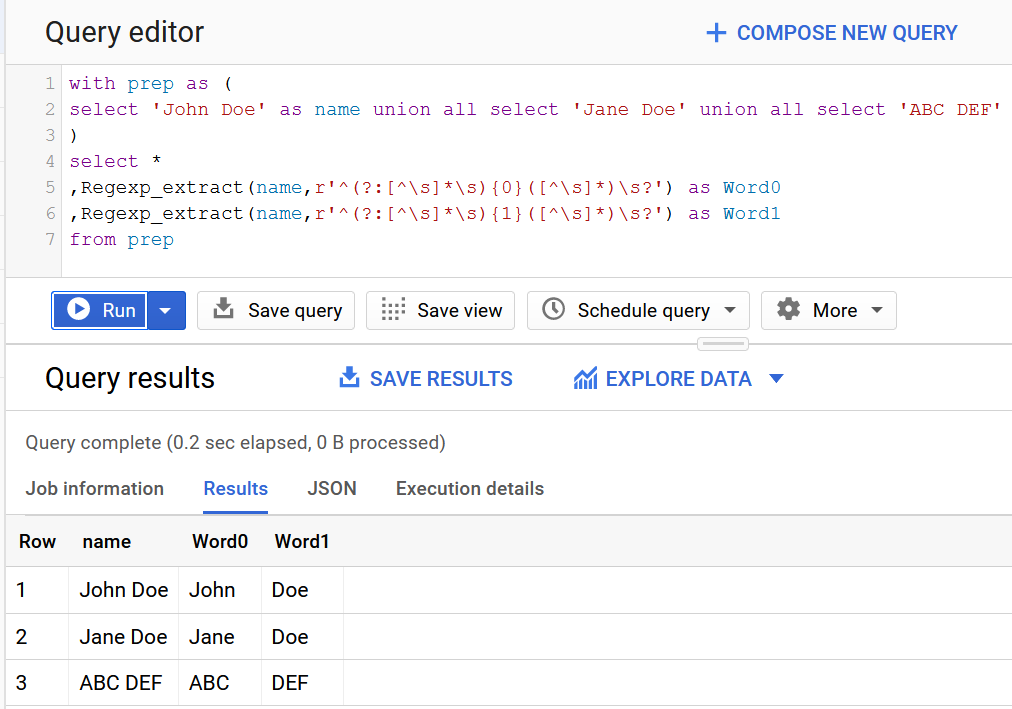
with prep as (
select 'John Doe' as name union all select 'Jane Doe' union all select 'ABC DEF'
)
select *
,Regexp_extract(name,r'^(?:[^\s]*\s){0}([^\s]*)\s?') as Word0
,Regexp_extract(name,r'^(?:[^\s]*\s){1}([^\s]*)\s?') as Word1
from prep
If there are more parts, there are no errors to those who have less:
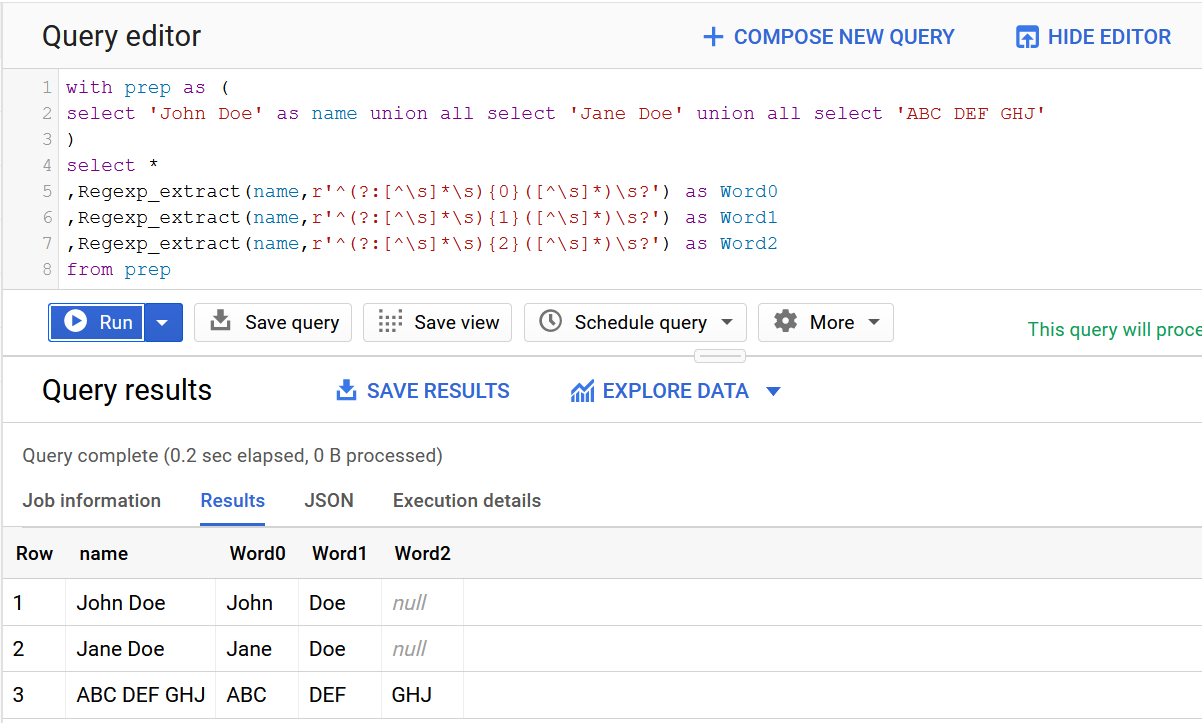
Great, I love it.
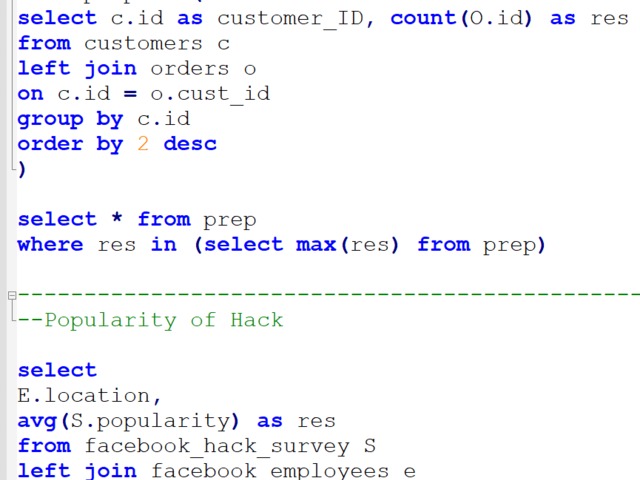
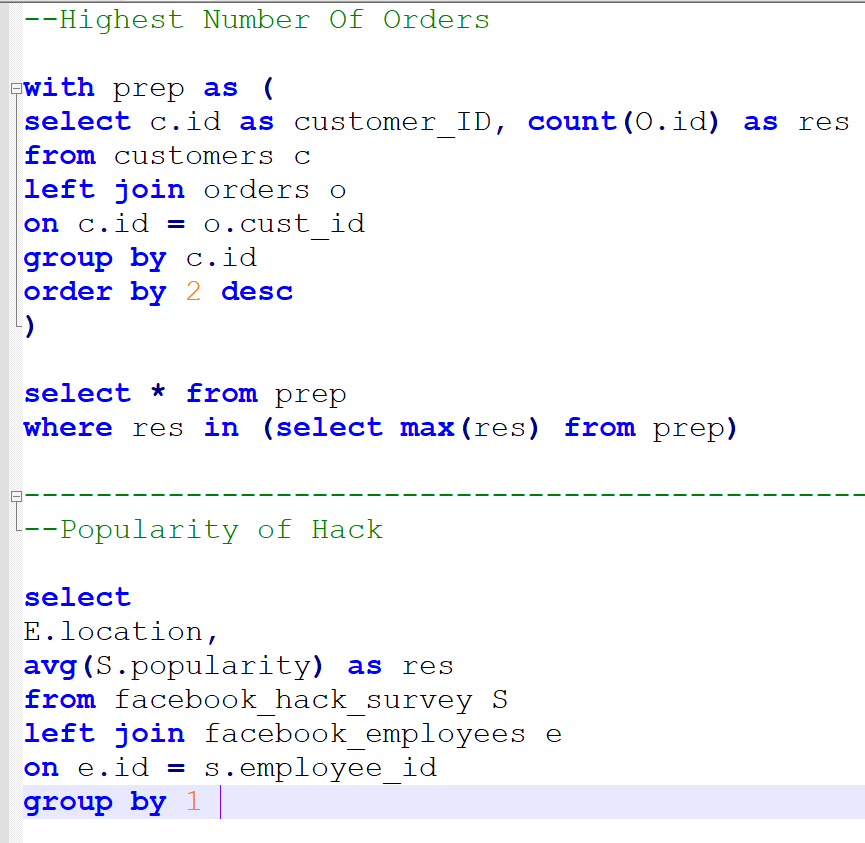
Coding challenges source: StrataScratch
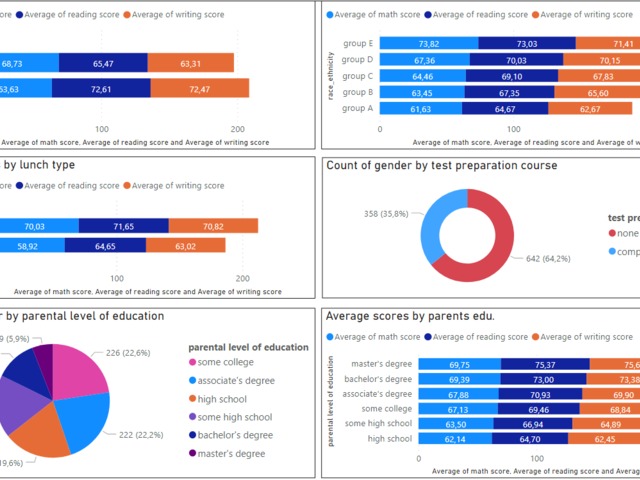
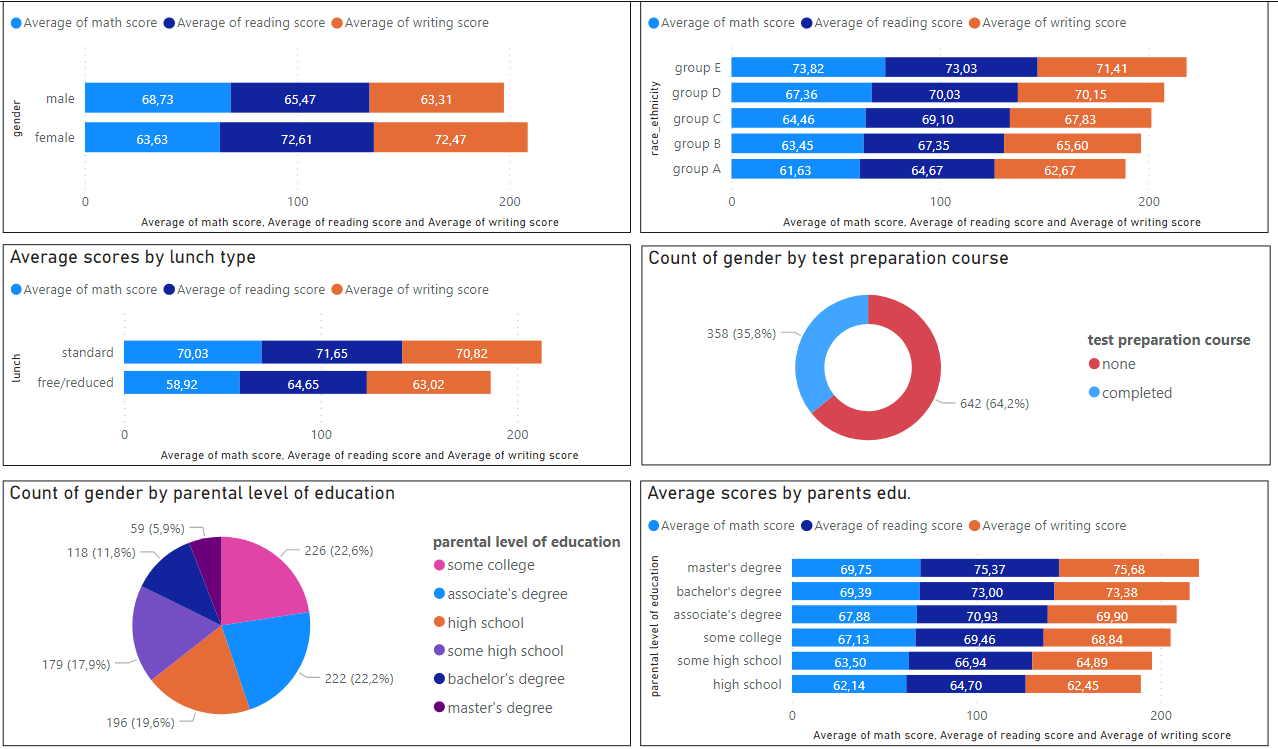

From:
https://www.kaggle.com/spscientist/students-performance-in-exams?select=StudentsPerformance.csv
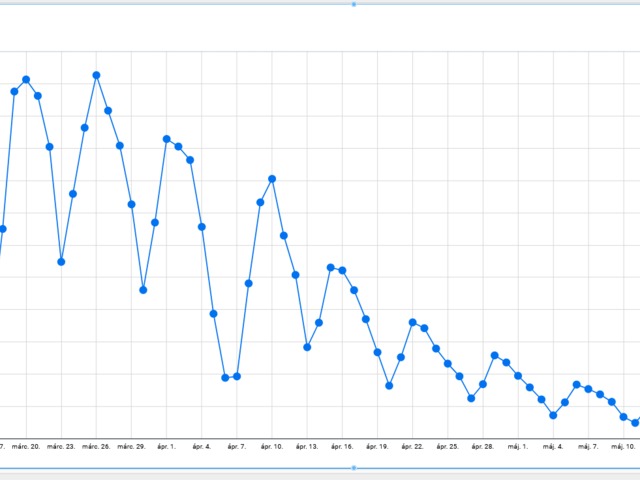
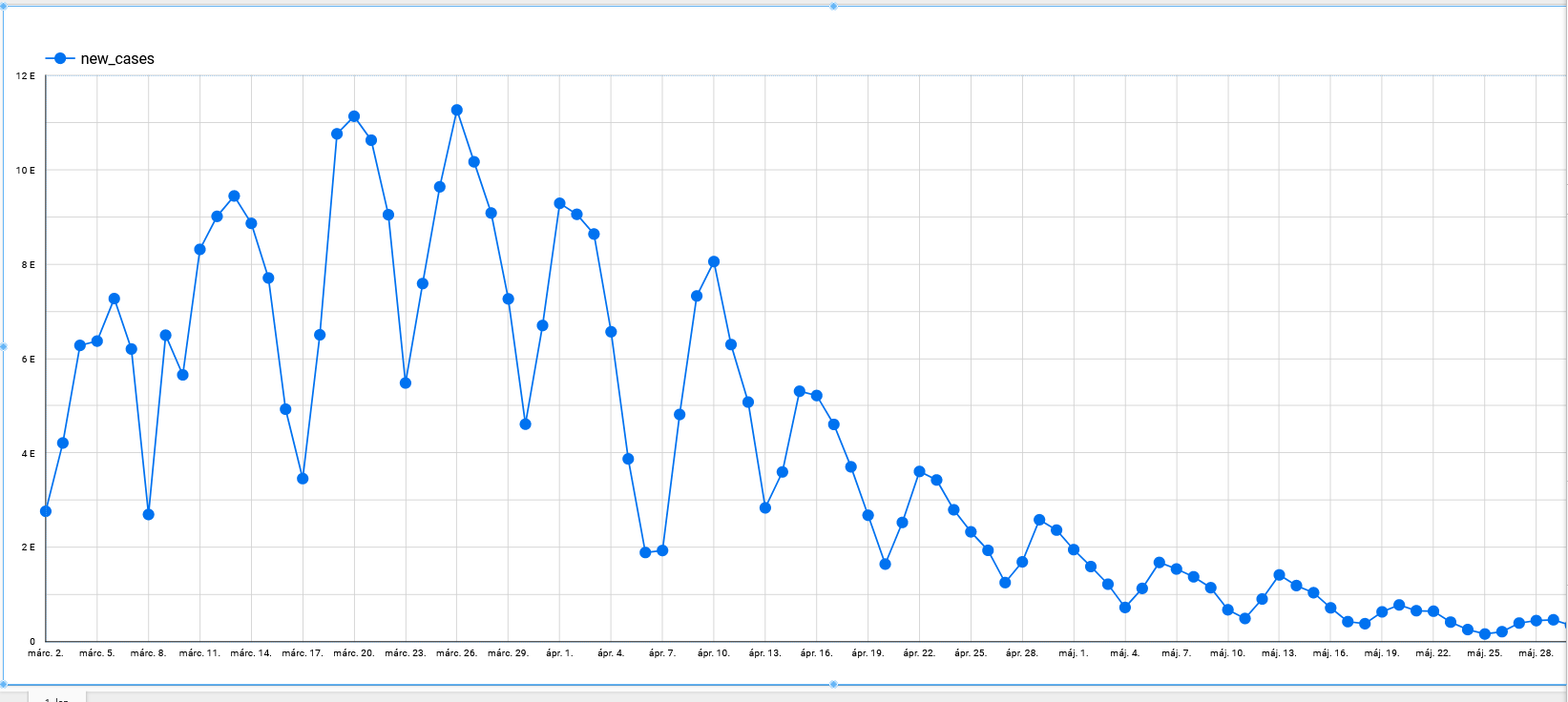
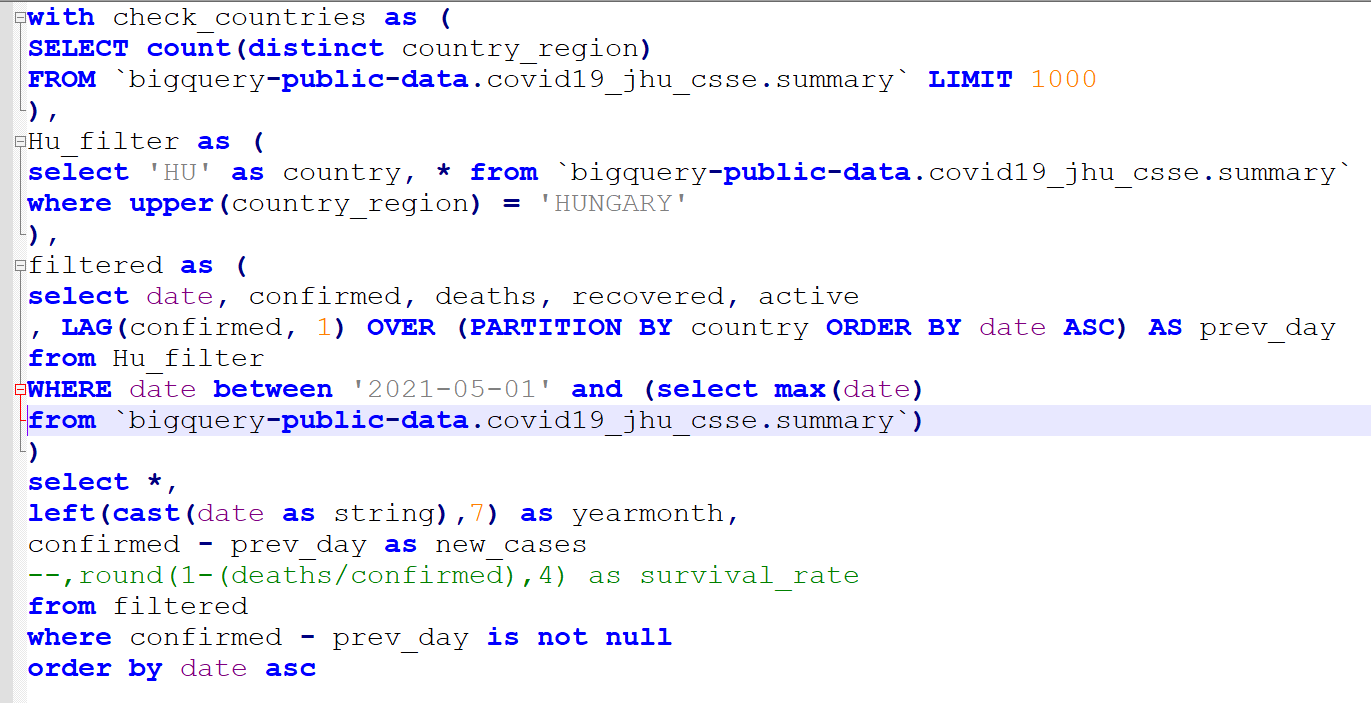
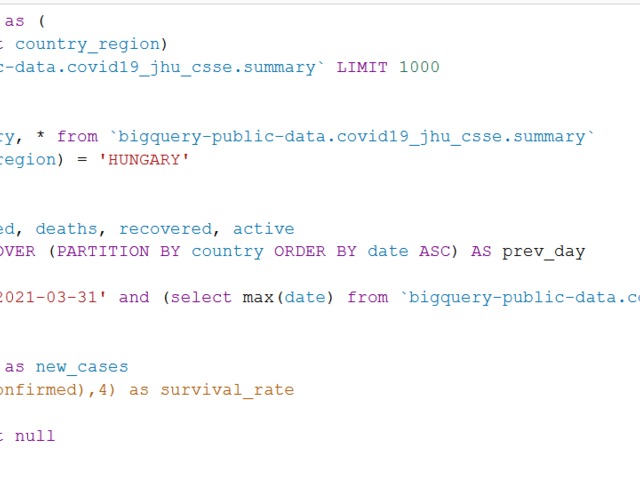
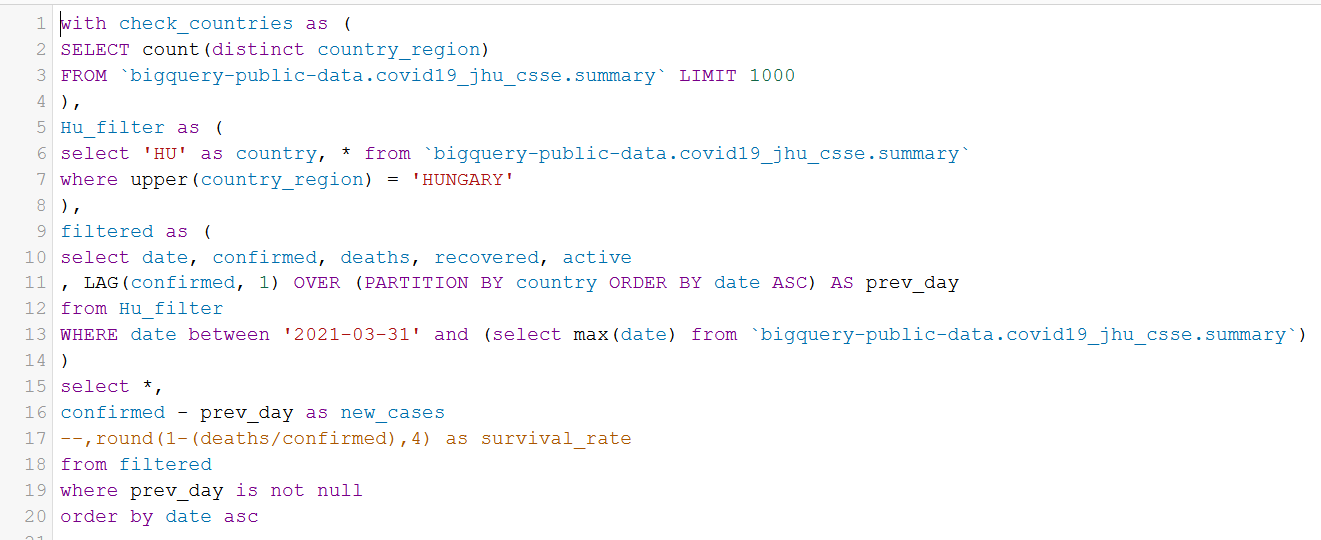
with check_countries as (
SELECT count(distinct country_region)
FROM `bigquery-public-data.covid19_jhu_csse.summary` LIMIT 1000
),
Hu_filter as (
select 'HU' as country, * from `bigquery-public-data.covid19_jhu_csse.summary`
where upper(country_region) = 'HUNGARY'
),
filtered as (
select date, confirmed, deaths, recovered, active
, LAG(confirmed, 1) OVER (PARTITION BY country ORDER BY date ASC) AS prev_day
from Hu_filter
WHERE date between '2021-03-01' and (select max(date) from `bigquery-public-data.covid19_jhu_csse.summary`)
)
select *,
confirmed - prev_day as new_cases
--,round(1-(deaths/confirmed),4) as survival_rate
from filtered
where confirmed - prev_day is not null
order by date asc


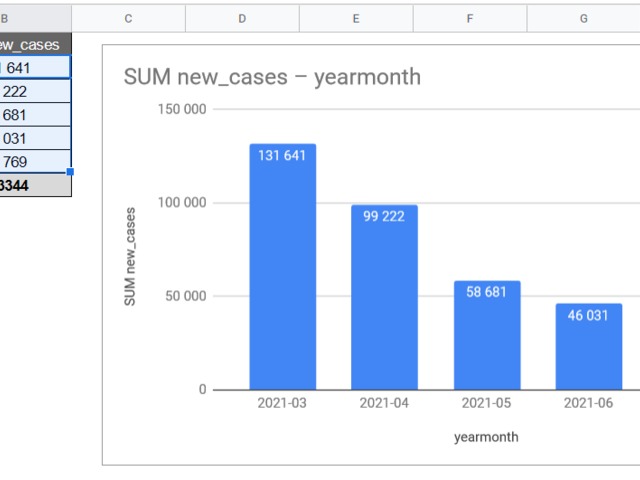
with generate_months as (
SELECT * FROM
UNNEST(GENERATE_DATE_ARRAY('2020-01-01', '2021-12-1', INTERVAL 1 MONTH)) AS dates
)
select 1 as key, left(cast(dates as string),7) as yearmonth
from generate_months
with ranked as (
select *
,dense_rank() over (order by score desc) as rn
from scores
)
select score, rn as 'Rank'
from ranked
order by score desc
with combined as (
select E.*, D.name as dep_name
from employee E
left join department D
on E.departmentid = d.id
),
ranked as (
select *
,dense_rank() over (partition by dep_name order by salary desc) as rn
from combined
)
select
dep_name as department,
name as Employee,
salary as Salary
from ranked where rn <= 3
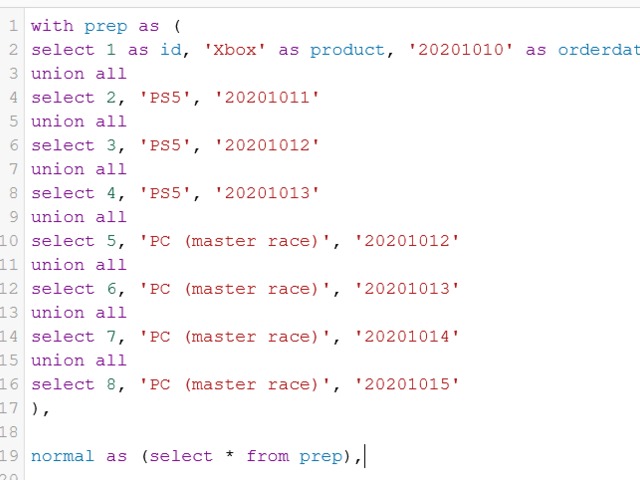
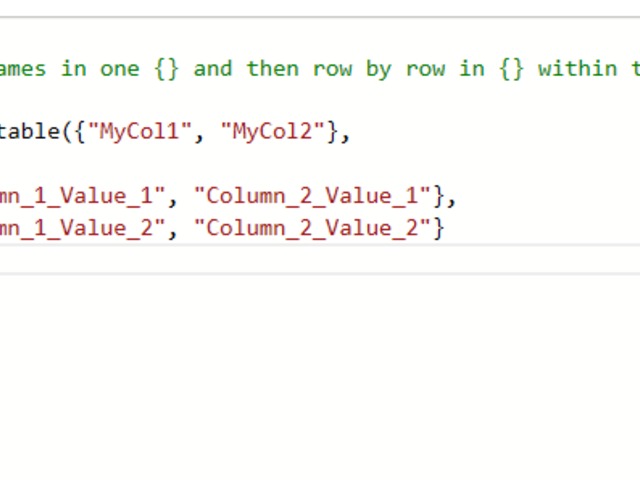
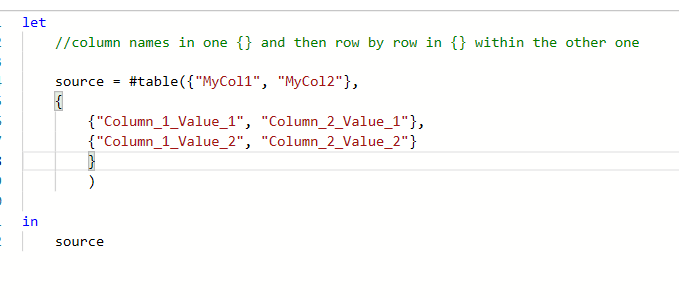
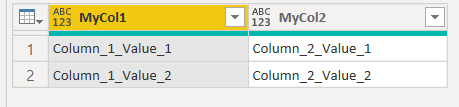
Let's take this example table first:
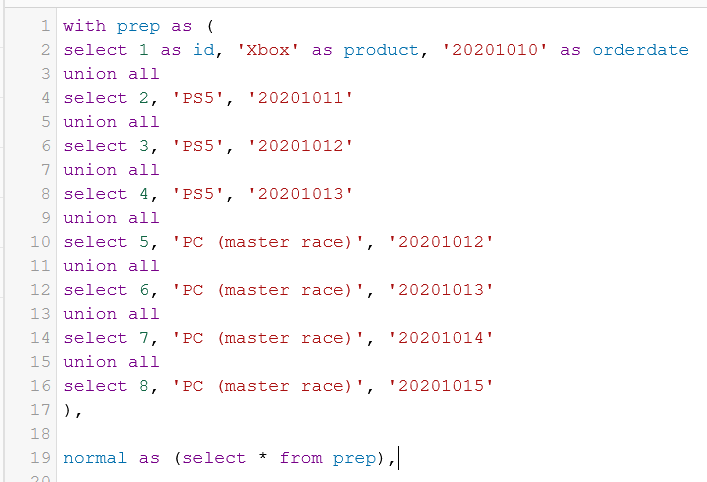
Results in simple 8 lines:
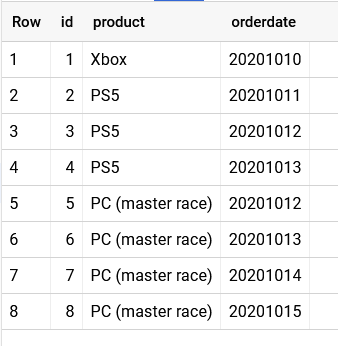
When I use the same table 3 times in the FROM clause:
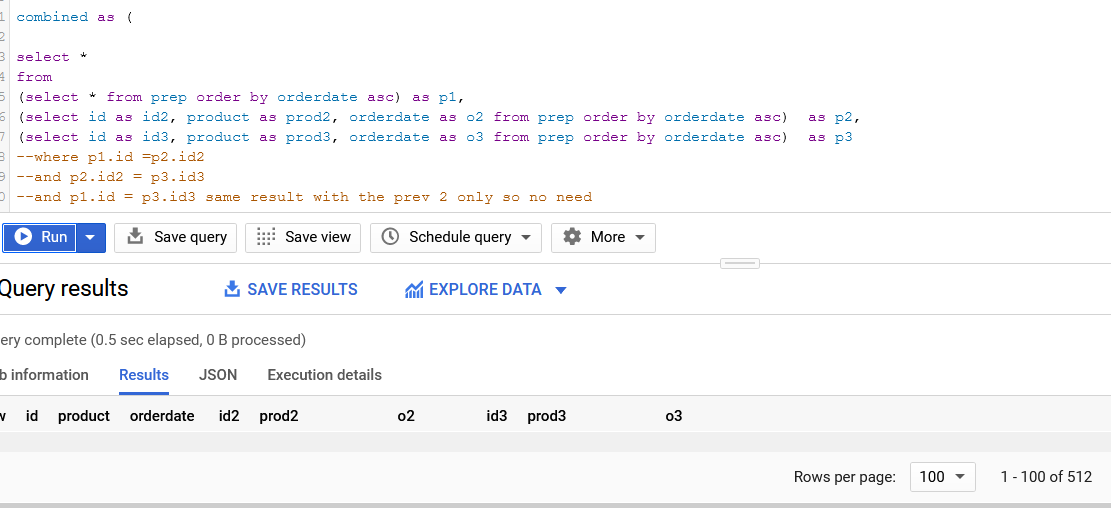
512 rows..But why? 8*8*8 = 512.
So you need to narrow that combination down with the commented part:
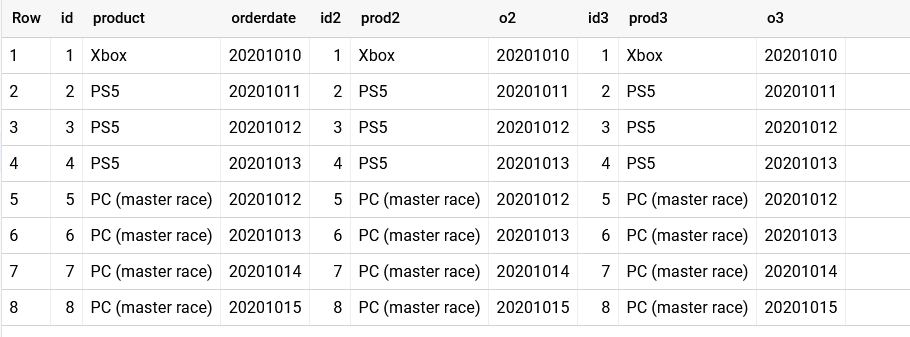
Now we have the same table, 3 times, without the weired combinations.
This is a partition table.. let's see what values can we partition by then:
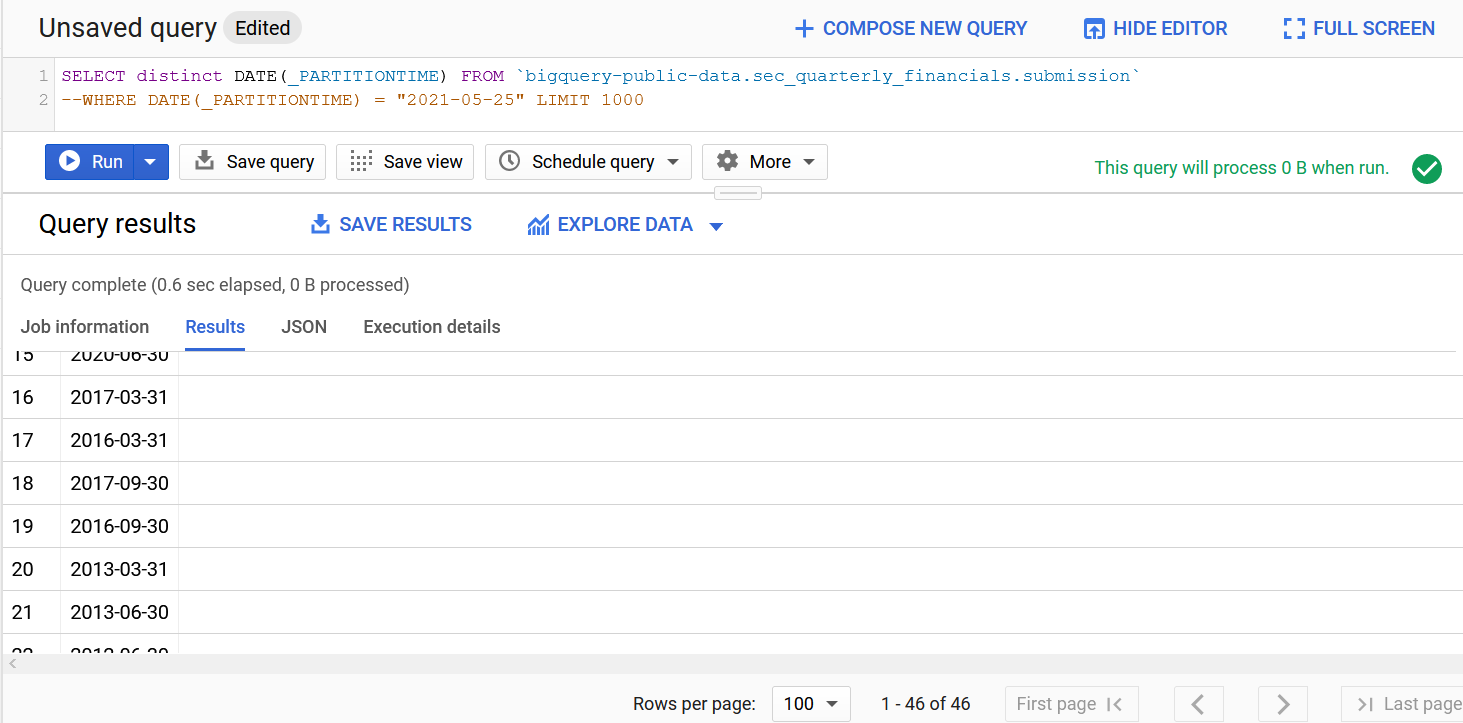
Test:

How many companies:
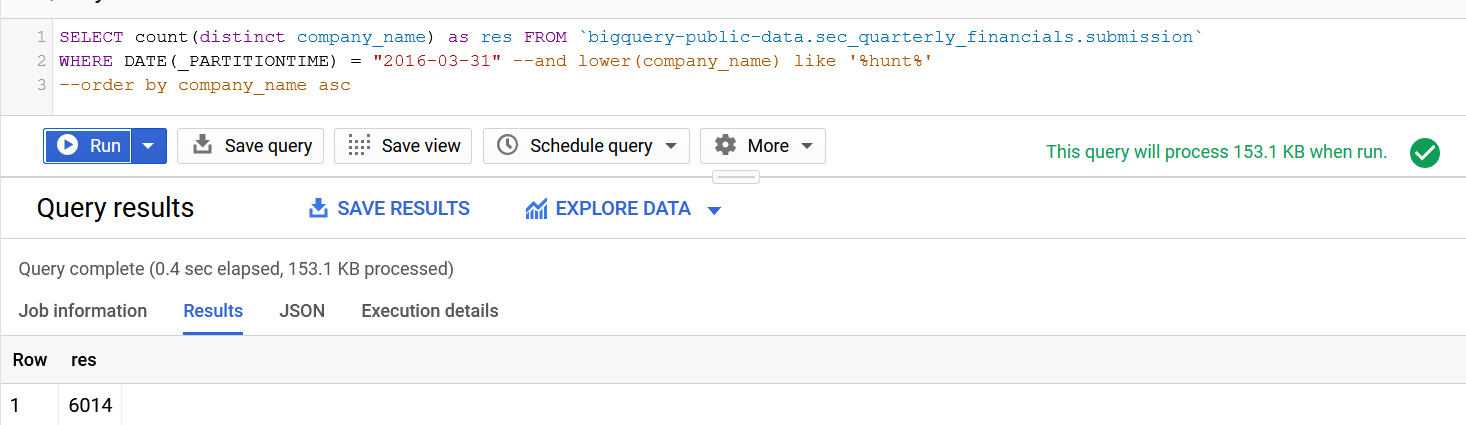
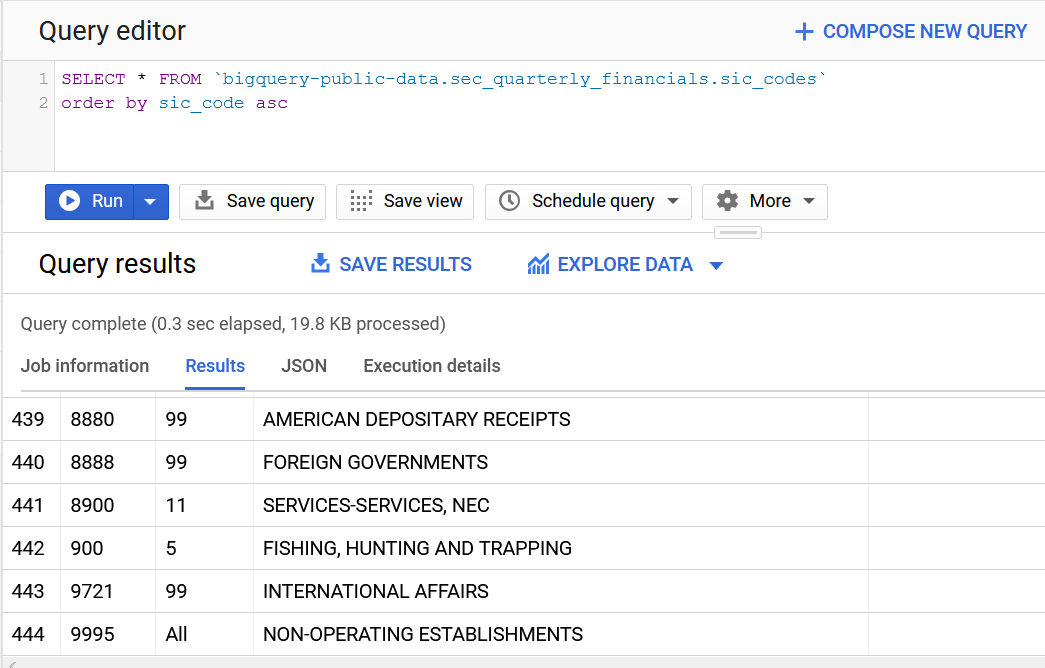
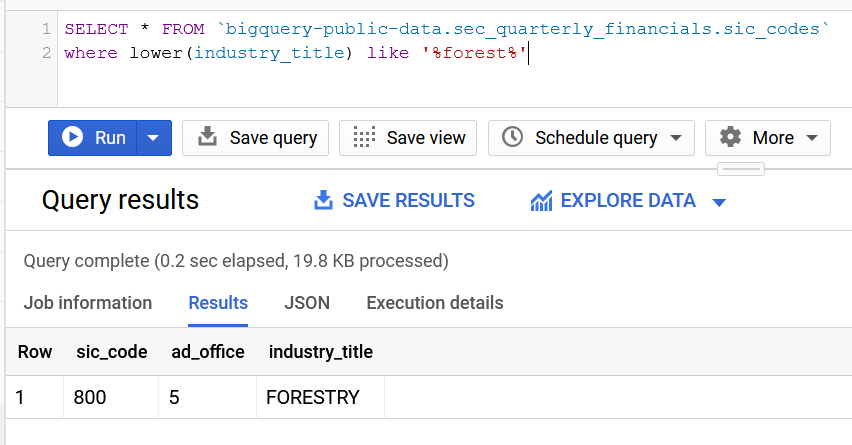
SIC codes:
Getting all data:

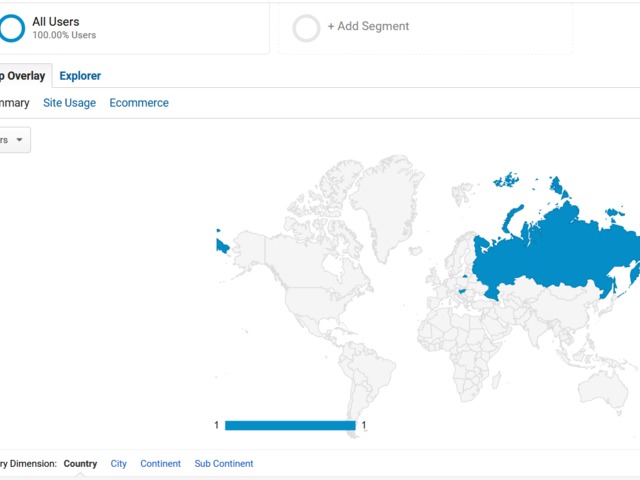

So nothing was viewed specifically
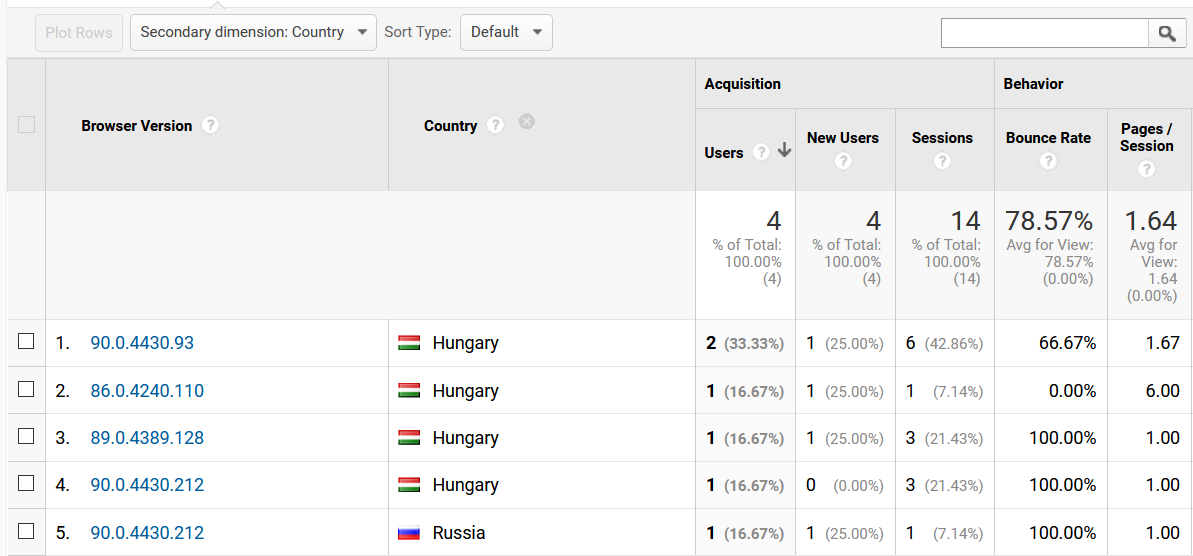
Browser versions:
Get the value of the text in the form, TRY IT OUT:

with check_countries as (
SELECT count(distinct country_region)
FROM `bigquery-public-data.covid19_jhu_csse.summary` LIMIT 1000
),
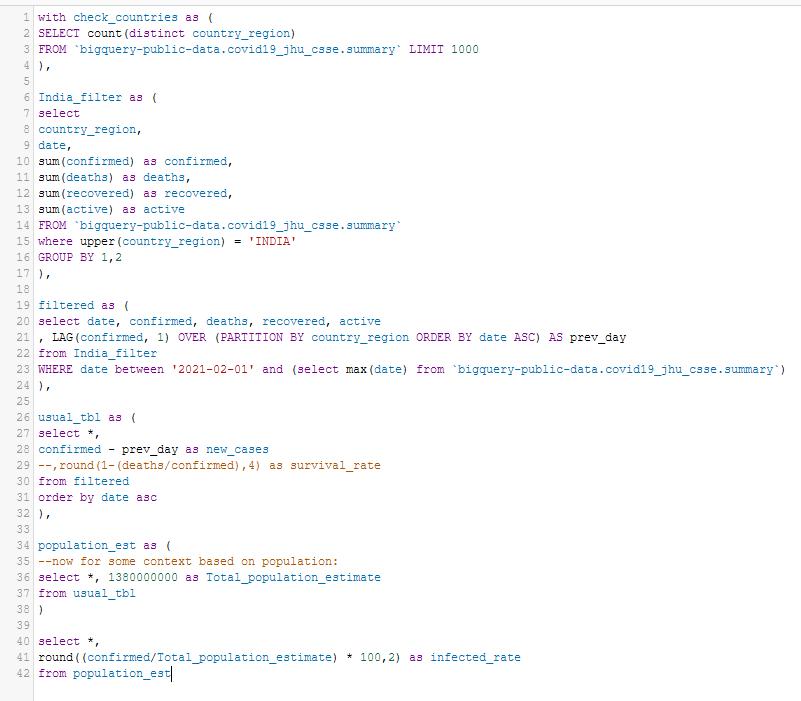
India_filter as (
select
country_region,
date,
sum(confirmed) as confirmed,
sum(deaths) as deaths,
sum(recovered) as recovered,
sum(active) as active
FROM `bigquery-public-data.covid19_jhu_csse.summary`
where upper(country_region) = 'INDIA'
GROUP BY 1,2
),
filtered as (
select date, confirmed, deaths, recovered, active
, LAG(confirmed, 1) OVER (PARTITION BY country_region ORDER BY date ASC) AS prev_day
from India_filter
WHERE date between '2021-02-01' and (select max(date) from `bigquery-public-data.covid19_jhu_csse.summary`)
),
usual_tbl as (
select *,
confirmed - prev_day as new_cases
--,round(1-(deaths/confirmed),4) as survival_rate
from ...
For Tagmanager or just basic JS/HTML exercise:
<script>
function GiveBackName() {
let inputvalue = document.getElementById("fname").value
alert(inputvalue)
console.log(inputvalue)
// for TagManager you just need:
// return document.getElementById("fname").value
}
</script>
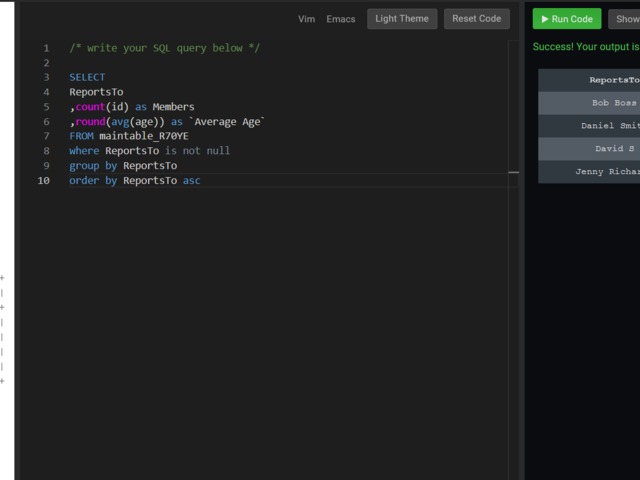
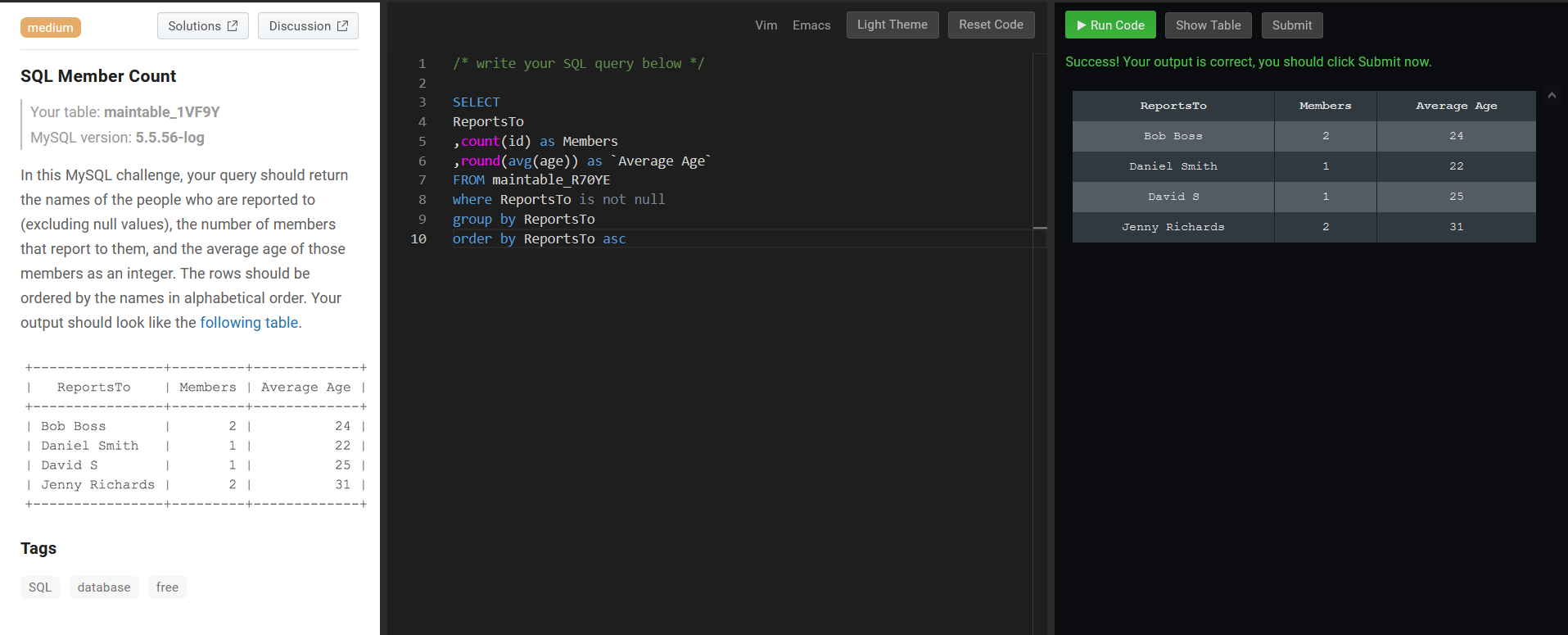
SELECT
ReportsTo
,count(id) as Members
,round(avg(age)) as `Average Age`
FROM maintable_R70YE
where ReportsTo is not null
group by ReportsTo
order by ReportsTo asc

And the results are:
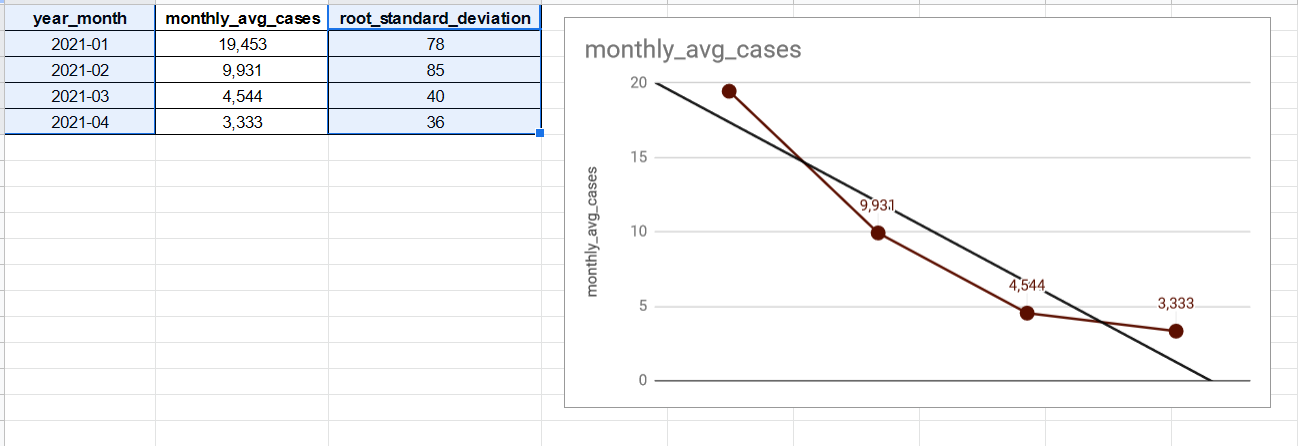
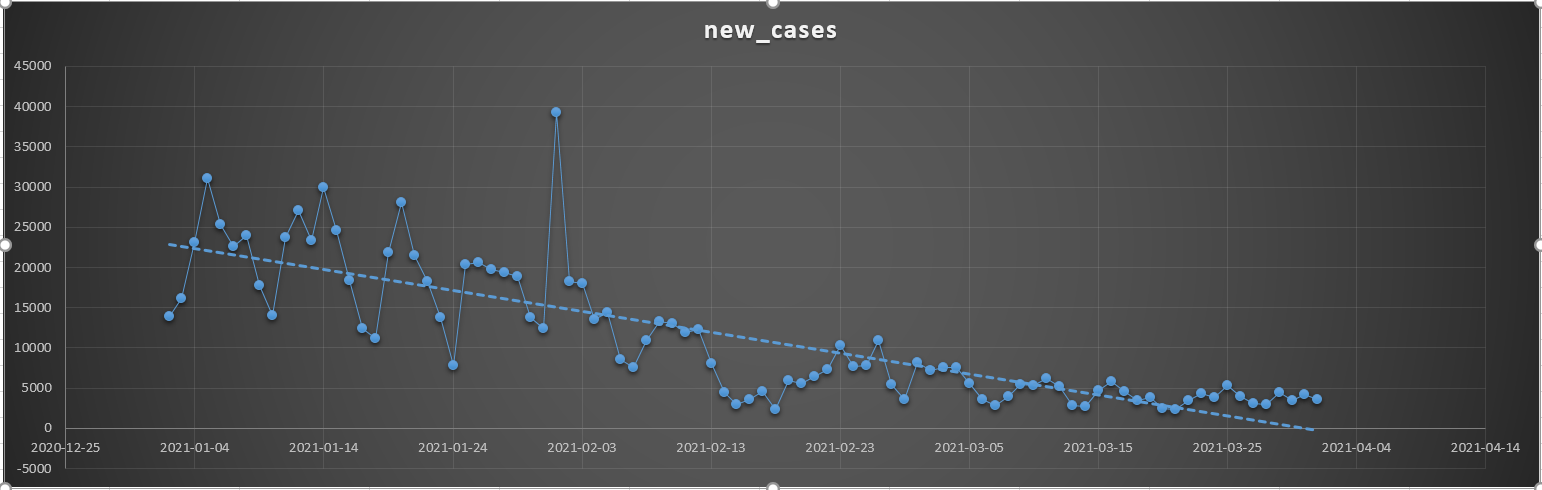
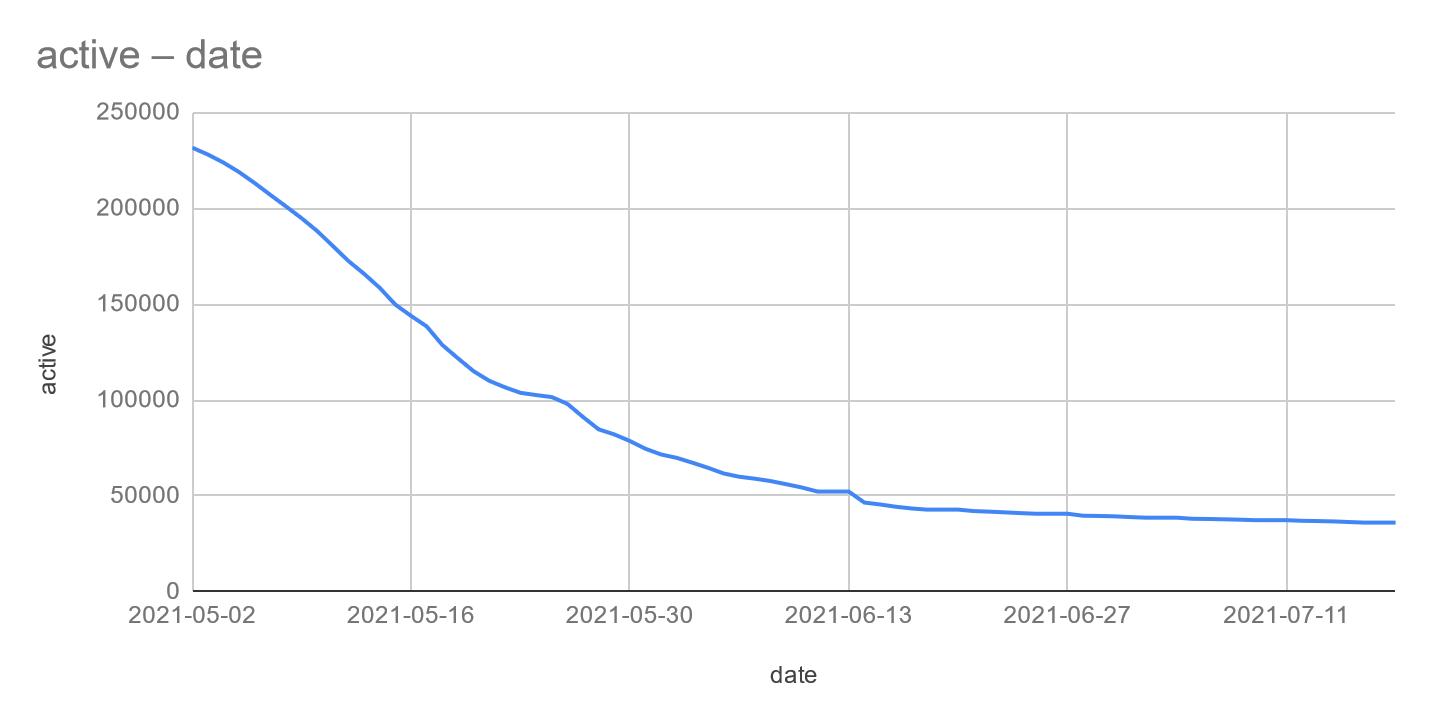
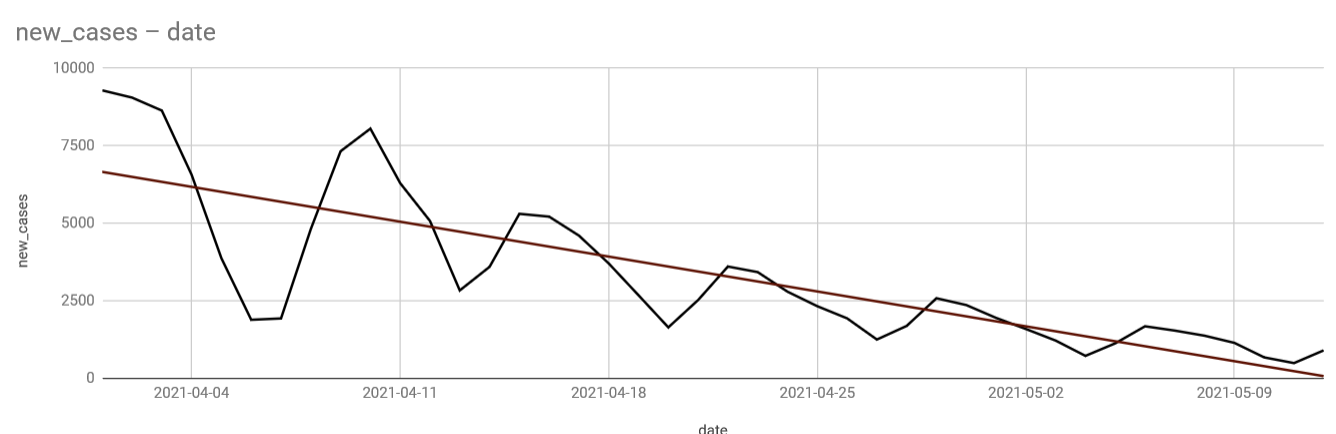
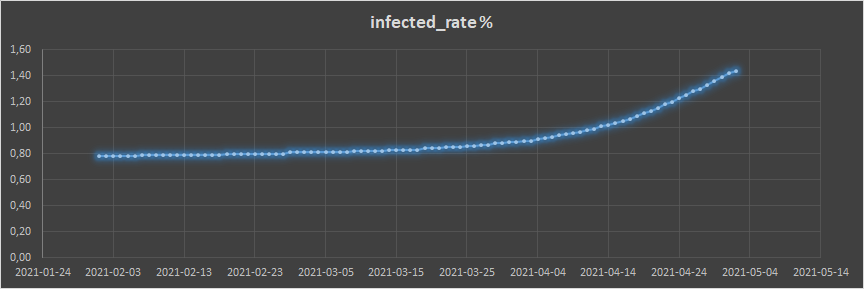
Good news, seems to be still dropping more and more.


SELECT
device.browser,
SUM ( totals.transactions ) AS total_transactions
FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE
_TABLE_SUFFIX BETWEEN '20170701' AND '20170731'
GROUP BY device.browser
HAVING SUM ( totals.transactions ) > 0
ORDER BY
total_transactions DESC
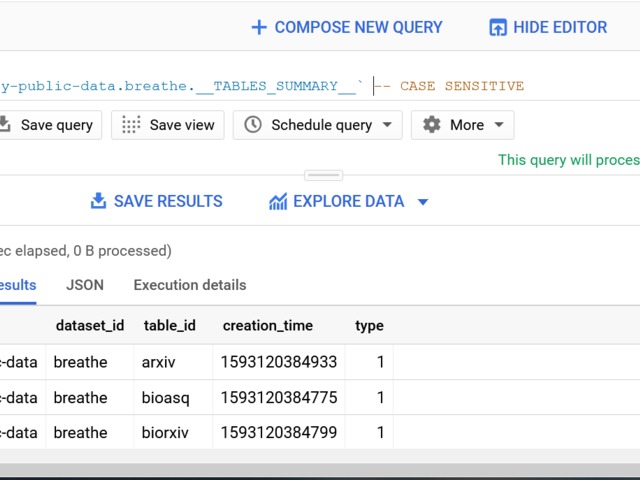
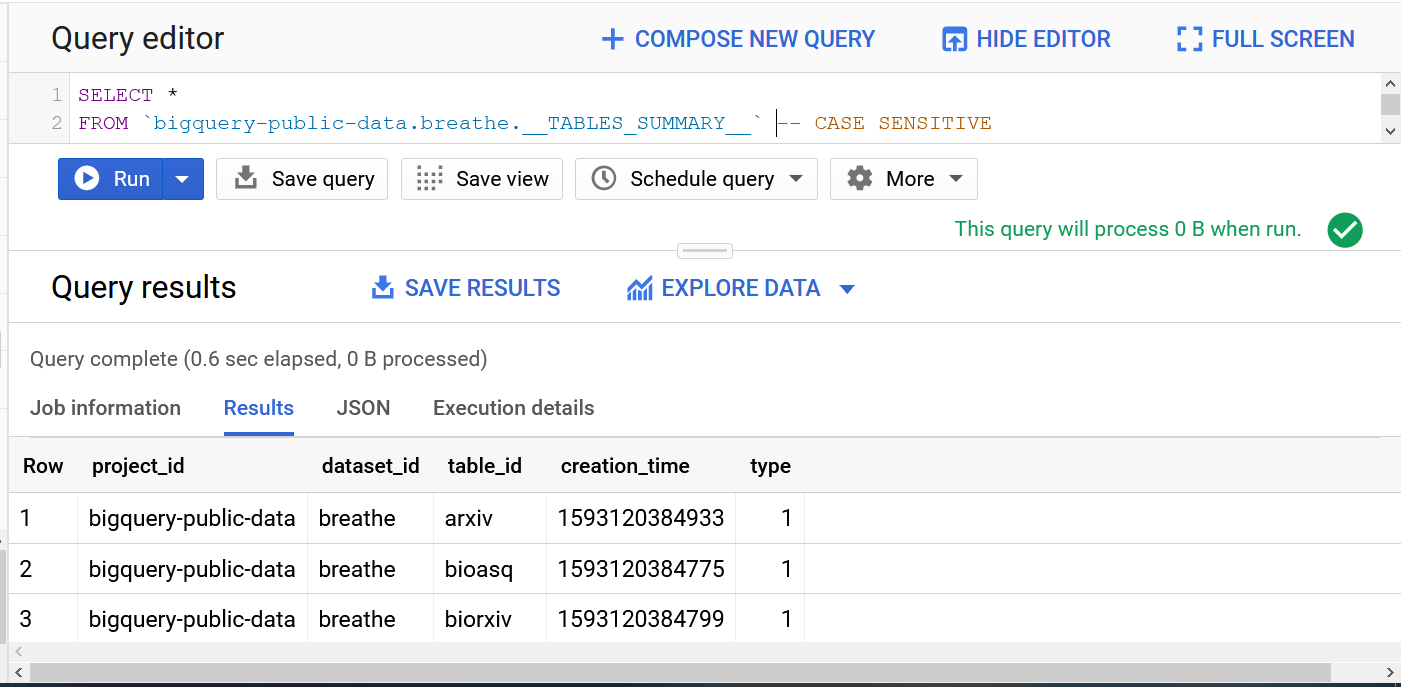
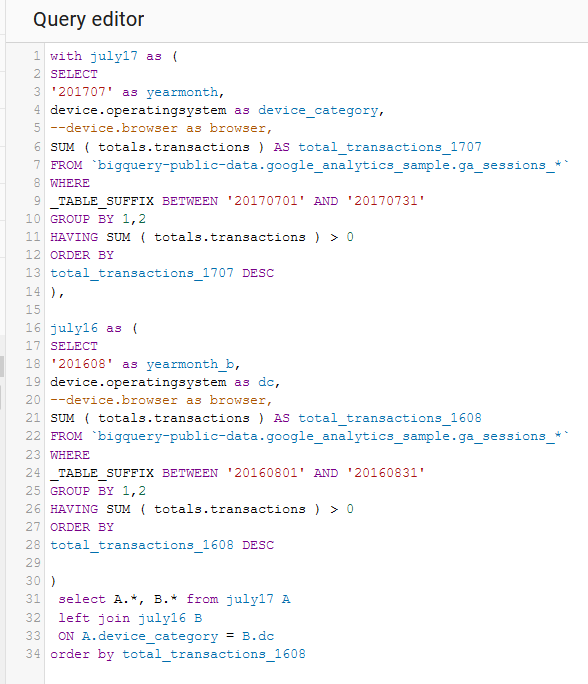
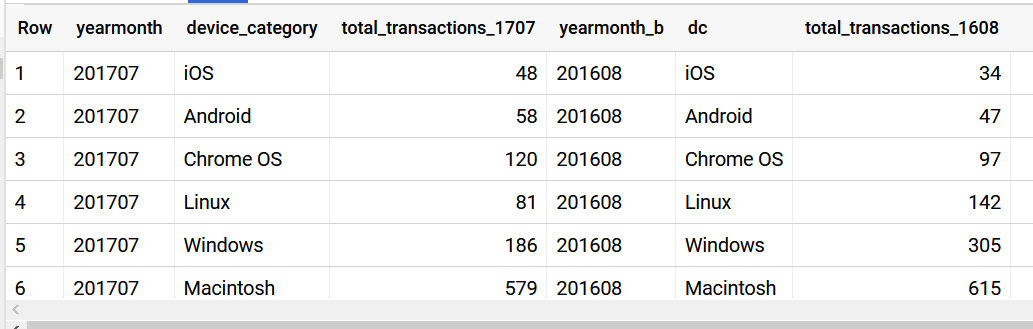
More tables, like with Google Analytics:
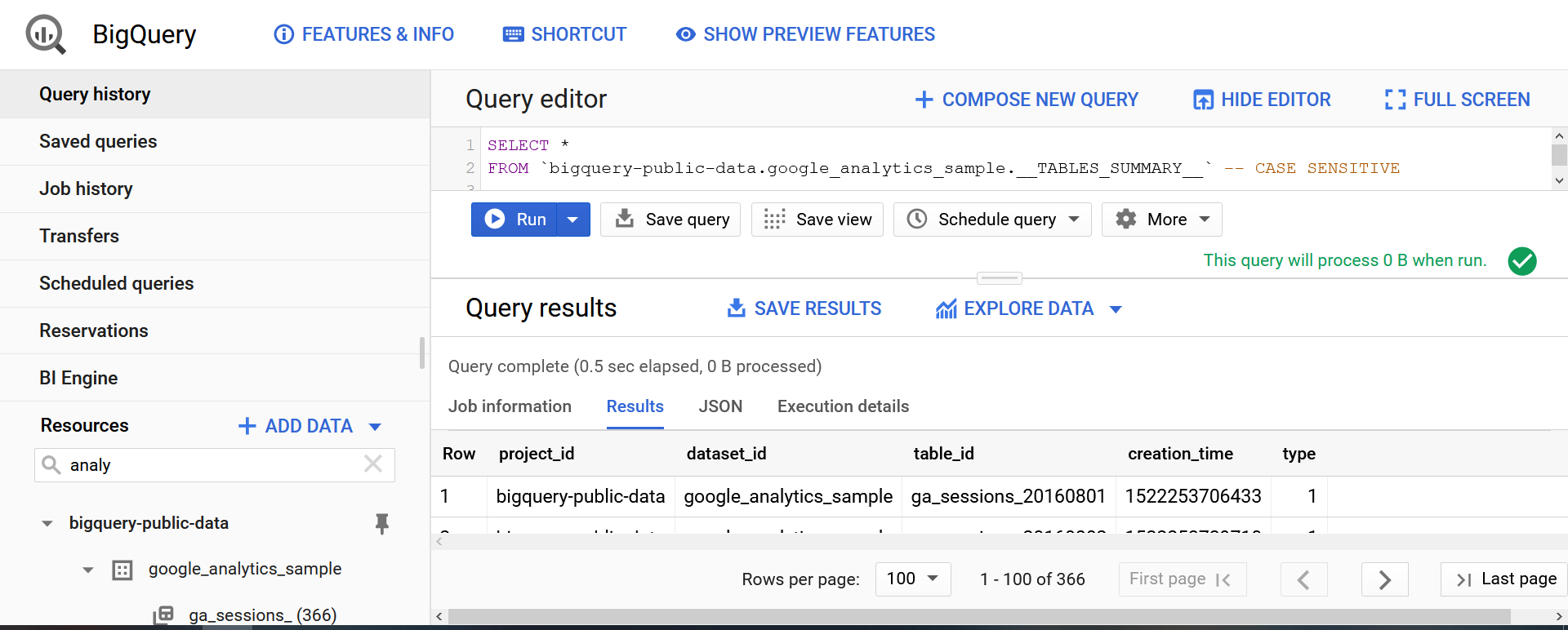
Get latest (freshest date/table)
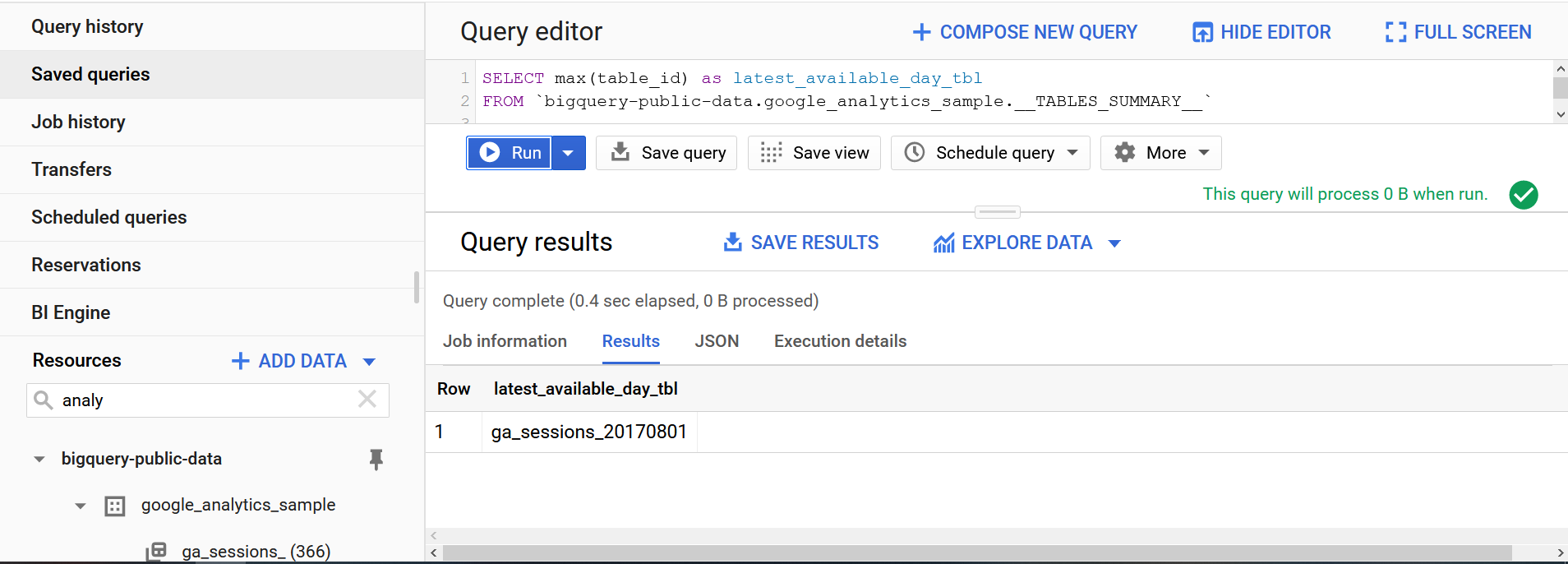
It is so META good.
SELECT max(table_id) as latest_available_day_tbl
FROM `bigquery-public-data.google_analytics_sample.__TABLES_SUMMARY__`
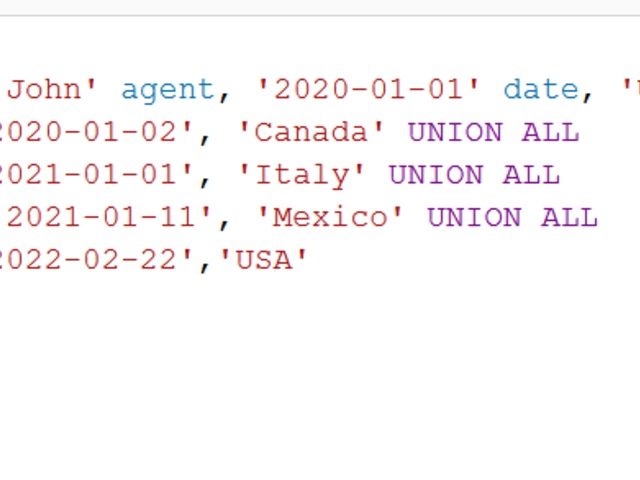
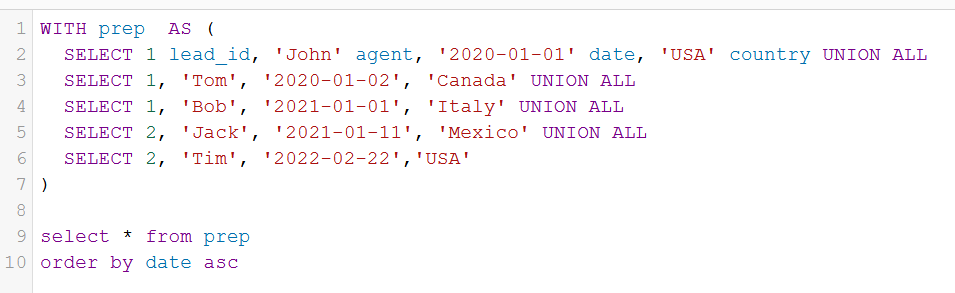
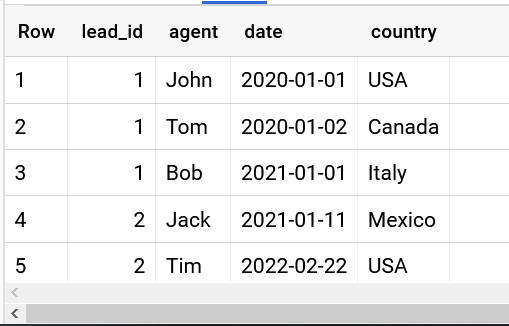
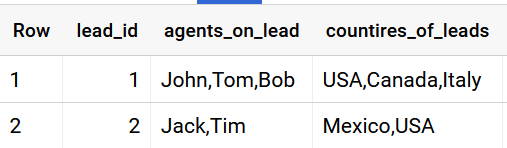
Using STRING_AGG(CONCAT( colname , ''))

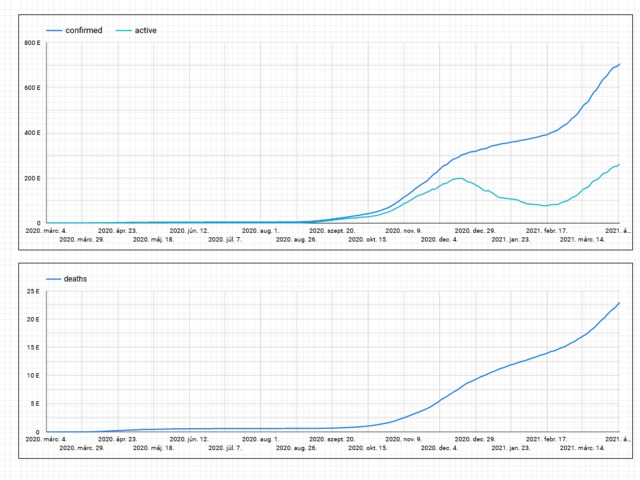
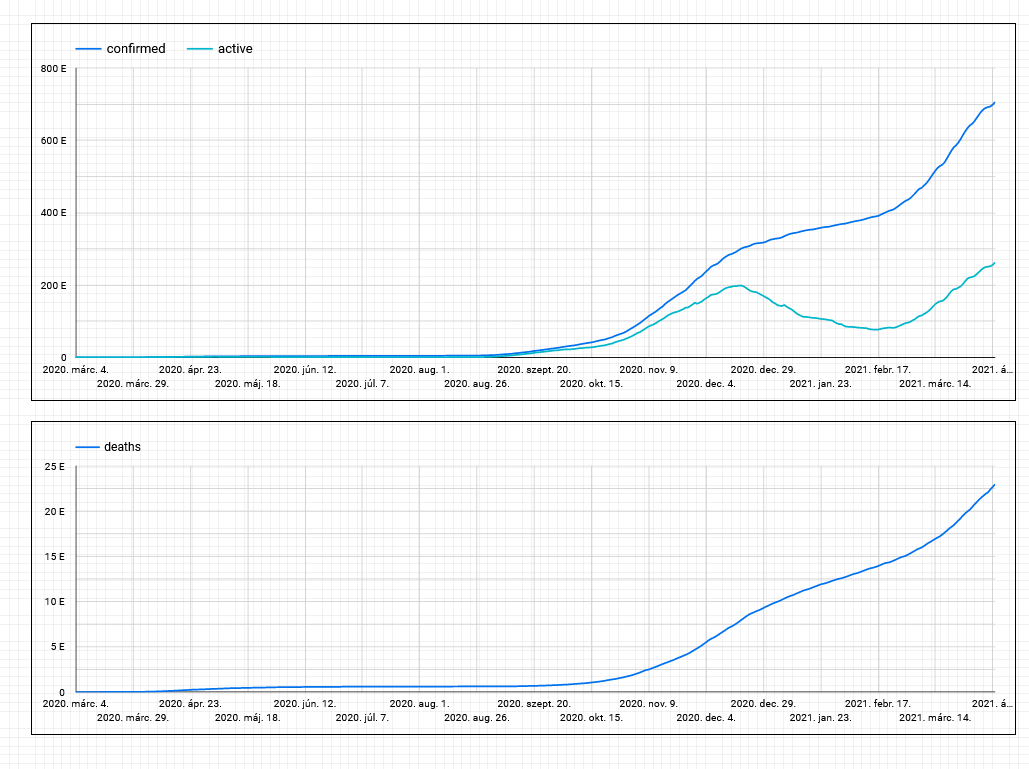
with check_countries as (
SELECT count(distinct country_region)
FROM `bigquery-public-data.covid19_jhu_csse.summary` LIMIT 1000
),
Hu_filter as (
select 'HU' as country, * from `bigquery-public-data.covid19_jhu_csse.summary`
where upper(country_region) = 'HUNGARY'
),
filtered as (
select date, confirmed, deaths, recovered, active
, LAG(confirmed, 1) OVER (PARTITION BY country ORDER BY date ASC) AS prev_day
from Hu_filter
WHERE date between '2020-03-01' and (select max(date) from `bigquery-public-data.covid19_jhu_csse.summary`)
)
select *,
confirmed - prev_day as new_cases
--,round(1-(deaths/confirmed),4) as survival_rate
from filtered
order by date asc
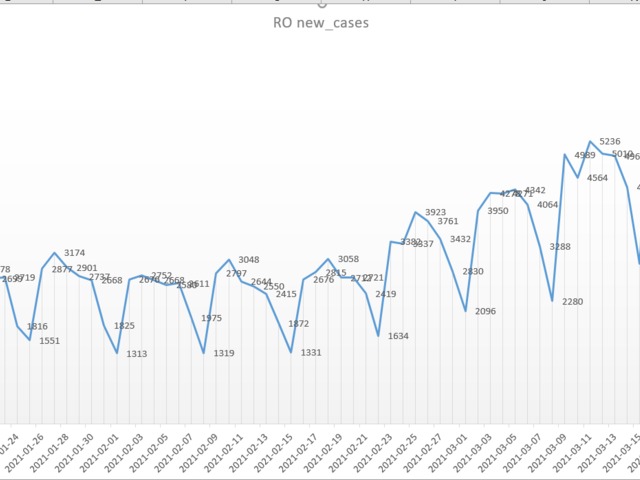
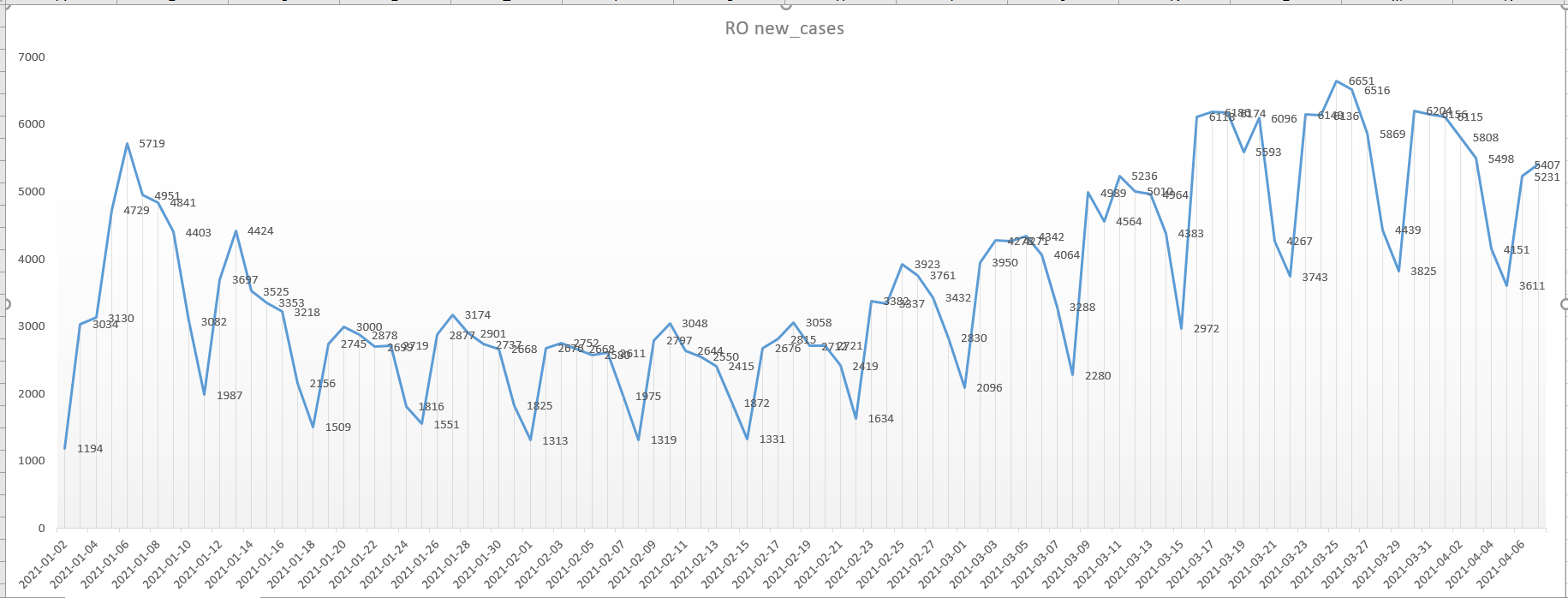
with check_countries as (
SELECT count(distinct country_region)
FROM `bigquery-public-data.covid19_jhu_csse.summary` LIMIT 1000
),
Ro_filter as (
select 'HU' as country, * from `bigquery-public-data.covid19_jhu_csse.summary`
where upper(country_region) = 'ROMANIA'
),
filtered as (
select date, confirmed, deaths, recovered, active
, LAG(confirmed, 1) OVER (PARTITION BY country ORDER BY date ASC) AS prev_day
from Hu_filter
WHERE date between '2021-01-01' and (select max(date) from `bigquery-public-data.covid19_jhu_csse.summary`)
)
select *,
confirmed - prev_day as new_cases
--,round(1-(deaths/confirmed),4) as survival_rate
from filtered
order by date asc
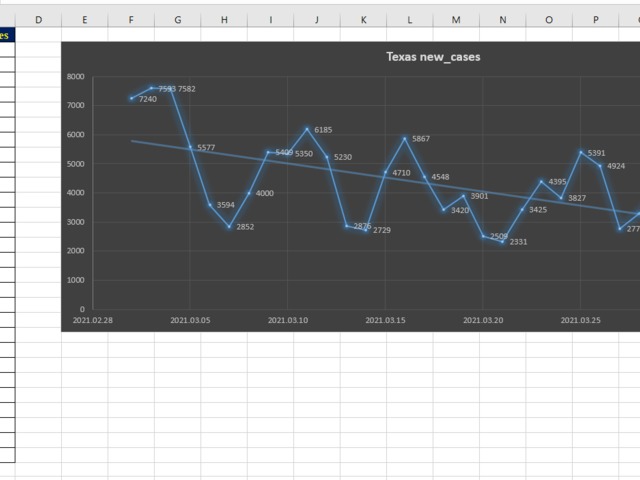
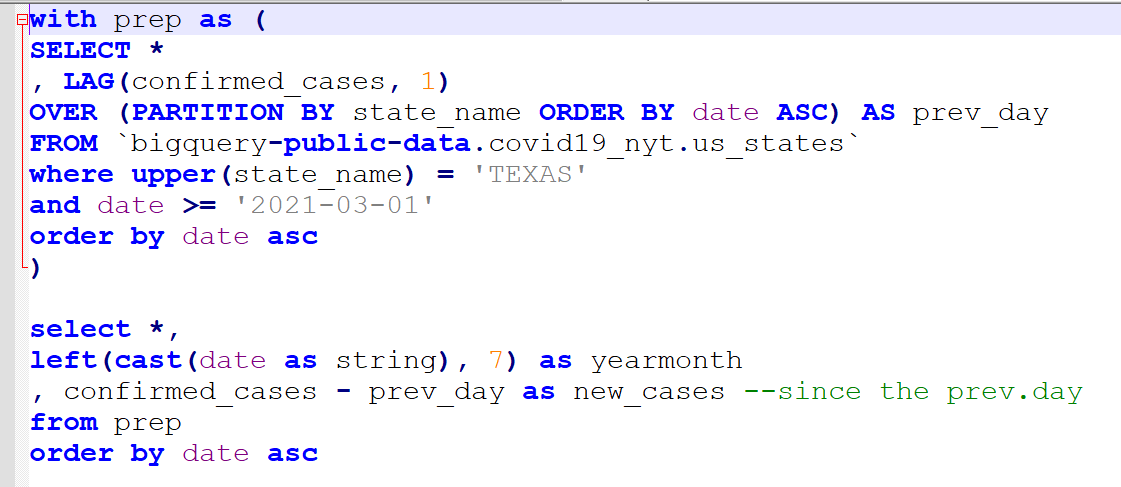
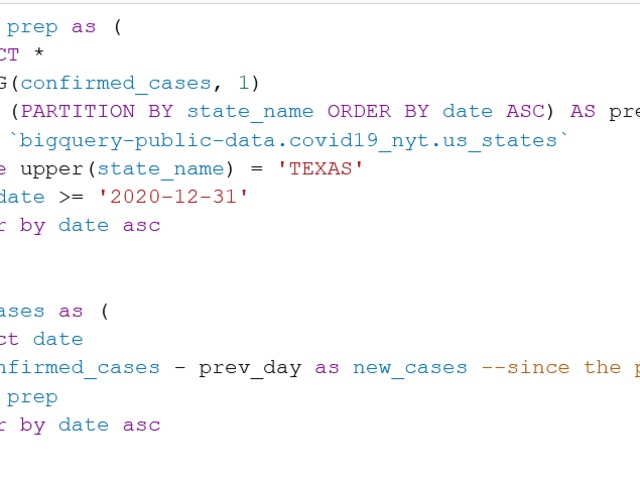
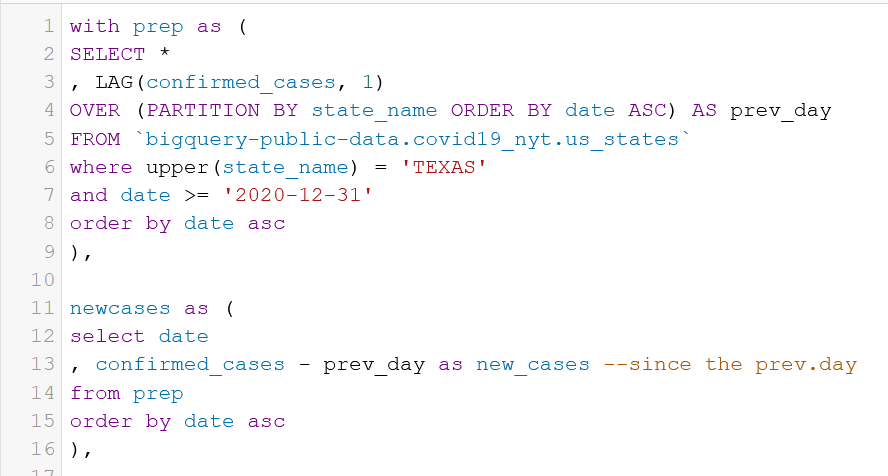
with prep as (
SELECT *
, LAG(confirmed_cases, 1)
OVER (PARTITION BY state_name ORDER BY date ASC) AS prev_day
FROM `bigquery-public-data.covid19_nyt.us_states`
where upper(state_name) = 'TEXAS'
and date >= '2021-03-01'
order by date asc
)
select date
, confirmed_cases - prev_day as new_cases --since the prev.day
from prep
order by date asc